【对抗攻击代码实战】对抗样本的生成——FGSM
论文链接:论文笔记链接:主要讲如何用FGSM生成对抗样本代码来源于pytorch官网:fgsm_tutoriall基于优化的对抗样本首先我们讲一下基于优化方法的FGSM
前言
让我们来看一下,怎么从深度学习的基本过程到对抗样本的生成?回顾一下深度学习训练的过程,通过计算预测值与实际值之间的损失函数,通过梯度下降,反向传播,更新了参数,不断减小损失函数的值,过程如下图所示:
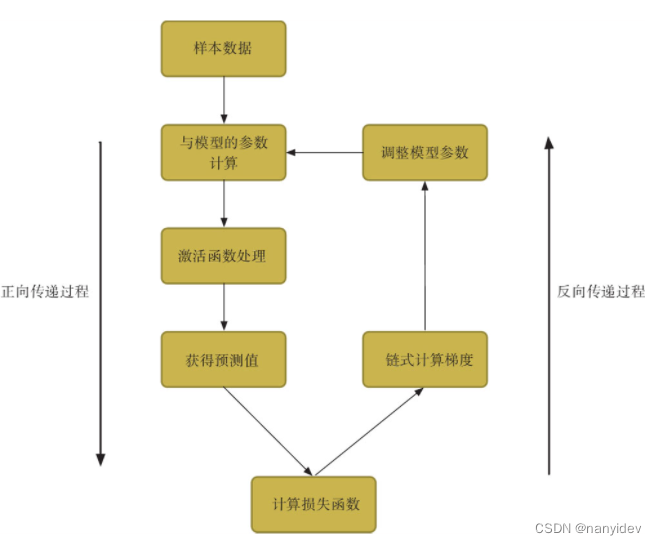
那对抗样本的生成也可以参考这样的过程。不同的是,对抗样本的生成过程中网络参数不变(一般是训练好的分类器),通过反向传播不断地更新调整对抗样本,也是不断的减小损失函数。关于loss函数这篇有讲到:来自人类的恶意:对抗攻击

基于优化的对抗样本
基于优化方法的对抗样本生成与深度学习训练过程类似,核心代码如下:
optimizer = torch.optim.Adam([img])(优化的对象是img)
代码参考自:AI安全之对抗样本
# 攻击的模型是alexnet
model = models.alexnet(pretrained=True).to(device).eval()
# 先预测出这张img的标签,需要先取他的数据再转移到cpu再转成numpy
label = np.argmax(model(img).data.cpu().numpy())
print("label={}".format(label))
# 图像数据梯度可以获取
img.requires_grad = True
# 设置为不保存梯度值 自然也无法修改
for param in model.parameters():
param.requires_grad = False
# 注意这里,和一般的深度学习训练不一样
optimizer = torch.optim.Adam([img],lr=0.01)
loss_func = torch.nn.CrossEntropyLoss()
epochs = 100
target = 288 # 定向攻击的标签
target = Variable(torch.Tensor([float(target)]).to(device).long())
for epoch in range(epochs):
# 梯度清零
optimizer.zero_grad()
# forward + backward
output = model(img)
loss = loss_func(output, target)
label = np.argmax(output.data.cpu().numpy())
print("epoch={} loss={} label={}".format(epoch, loss, label))
# 如果定向攻击成功
if label == target:
break
loss.backward()
optimizer.step()
FGSM
之前是用优化的方法,现在考虑的是用梯度来生成对抗样本——Fast Gradient Sign Method(FGSM)
论文链接:Explaining andHarnessing Adversarial Examples
论文笔记链接:click here
代码参考于pytorch官网:fgsm_tutoriall
1.首先导入相关包和参数设置:
预训练模型下载:lenet_mnist_model.pth
也可以通过训练文件重新训练模型:example-mnist
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
# 定义扰动值列表
epsilons = [0, .05, .1, .15, .2, .25, .3]
# 预训练模型路径(训练好的模型文件的存储路径)
pretrained_model = "checkpoint/lenet_mnist_model.pth"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2.加载数据
采用MNIST测试集数据,batch_size=1
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./datasets', train=False, download=True, transform=transforms.ToTensor()),
batch_size=1,
shuffle=True
)
3.定义网络模型
# 定义LeNet模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
# 初始化网络
model = Net().to(device)
# 加载已经预训练的模型
model.load_state_dict(torch.load(pretrained_model, map_location='cpu'))
# 在评估模式下设置模型(Dropout层不被考虑)
model.eval()
4.定义攻击函数
FGSM论文中的公式:
p
e
r
t
u
r
b
e
d
_
i
m
a
g
e
=
i
m
a
g
e
+
e
p
s
i
l
o
n
∗
s
i
g
n
(
d
a
t
a
_
g
r
a
d
)
=
x
+
ϵ
∗
s
i
g
n
(
∇
x
J
(
θ
,
x
,
y
)
)
perturbed\_image=image+epsilon∗sign(data\_grad)=x+ϵ∗sign(∇_ xJ(θ,x,y))
perturbed_image=image+epsilon∗sign(data_grad)=x+ϵ∗sign(∇xJ(θ,x,y))
def fgsm_attack(image, epsilon, data_grad):
"""
:param image: 需要攻击的图像
:param epsilon: 扰动值的范围
:param data_grad: 图像的梯度
:return: 扰动后的图像
"""
# 收集数据梯度的元素符号
sign_data_grad = data_grad.sign()
# 通过调整输入图像的每个像素来创建扰动图像
perturbed_image = image + epsilon*sign_data_grad
# 添加剪切以维持[0,1]范围
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# 返回被扰动的图像
return perturbed_image
5.开始攻击
def test( model, device, test_loader, epsilon ):
# 精度计数器
correct = 0
adv_examples = []
# 循环遍历测试集中的所有示例
for data, target in test_loader:
# 把数据和标签发送到设备
data, target = data.to(device), target.to(device)
# 设置张量的requires_grad属性,这对于攻击很关键
data.requires_grad = True
# 通过模型前向传递数据
output = model(data)
init_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
# 如果初始预测是错误的,不打断攻击,继续
if init_pred.item() != target.item():
continue
# 计算损失
loss = F.nll_loss(output, target)
# 将所有现有的渐变归零
model.zero_grad()
# 计算后向传递模型的梯度
loss.backward()
# 收集datagrad
data_grad = data.grad.data
# 唤醒FGSM进行攻击
perturbed_data = fgsm_attack(data, epsilon, data_grad)
# 重新分类受扰乱的图像
output = model(perturbed_data)
# 检查是否成功
final_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
if final_pred.item() == target.item():
correct += 1
# 保存0 epsilon示例的特例
if (epsilon == 0) and (len(adv_examples) < 5):
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )
else:
# 稍后保存一些用于可视化的示例
if len(adv_examples) < 5:
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )
# 计算这个epsilon的最终准确度
final_acc = correct/float(len(test_loader))
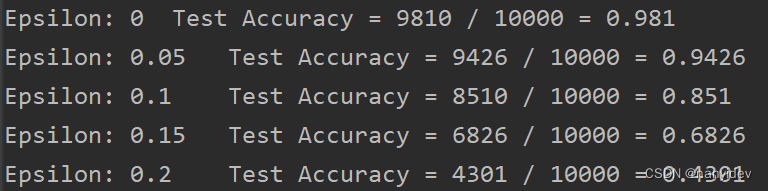
print("Epsilon: {}\tTest Accuracy = {} / {} = {}".format(epsilon, correct, len(test_loader), final_acc))
# 返回准确性和对抗性示例
return final_acc, adv_examples
输出:
6.可视化测试
# 对每个epsilon运行测试
for eps in epsilons:
acc, ex = test(model, device, test_loader, eps)
accuracies.append(acc)
examples.append(ex)
plt.figure(figsize=(5,5))
plt.plot(epsilons, accuracies, "*-")
plt.yticks(np.arange(0, 1.1, step=0.1))
plt.xticks(np.arange(0, .35, step=0.05))
plt.title("Accuracy vs Epsilon")
plt.xlabel("Epsilon")
plt.ylabel("Accuracy")
plt.show()
# 在每个epsilon上绘制几个对抗样本的例子
cnt = 0
plt.figure(figsize=(8,10))
for i in range(len(epsilons)):
for j in range(len(examples[i])):
cnt += 1
plt.subplot(len(epsilons),len(examples[0]),cnt)
plt.xticks([], [])
plt.yticks([], [])
if j == 0:
plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14)
orig,adv,ex = examples[i][j]
plt.title("{} -> {}".format(orig, adv))
plt.imshow(ex, cmap="gray")
plt.tight_layout()
plt.show()

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容
 免费领云主机
免费领云主机


 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)