条件随机场(CRF)概述
转自:原文链接条件随机场是一种判别模型,用于预测序列。他们使用来自先前标签的上下文信息,从而增加了模型做出良好预测所需的信息量。在这篇文章中,我将讨论一些将介绍 CRF 的主题。我会过去:机器学习模型有两个常见的分类,生成式和判别式。条件随机场是一种判别分类器,因此,它们对不同类之间的决策边界进行建模. 另一方面,生成模型对数据的生成方式进行建模,在学习之后,可用于进行分类任务。举个简单的例子,朴
转自:原文链接
条件随机场是一种判别模型,用于预测序列。他们使用来自先前标签的上下文信息,从而增加了模型做出良好预测所需的信息量。在这篇文章中,我将讨论一些将介绍 CRF 的主题。我会过去:
- 什么是判别分类器(以及它们与生成分类器的比较)
- 条件随机场的数学概述
- CRF 与隐马尔可夫模型有何不同
- CRF的应用
什么是判别分类器
机器学习模型有两个常见的分类,生成式和判别式。条件随机场是一种判别分类器,因此,它们对不同类之间的决策边界进行建模. 另一方面,生成模型对数据的生成方式进行建模,在学习之后,可用于进行分类任务。举个简单的例子,朴素贝叶斯是一种非常简单且流行的概率分类器,是一种生成算法,而逻辑回归是一种基于最大似然估计的分类器,是一种判别模型。让我们看看如何使用这些模型来计算标签预测:
朴素贝叶斯分类器基于贝叶斯公式:
p
(
y
∣
x
)
=
p
(
y
)
p
(
x
∣
y
)
p
(
x
)
p(y|x)=\frac{p(y)p(x|y)}{p(x)}
p(y∣x)=p(x)p(y)p(x∣y)
换成分类任务的表达式:
p
(
类
别
∣
特
征
)
=
p
(
特
征
∣
类
别
)
p
(
类
别
)
p
(
特
征
)
p(类别|特征)=\frac{p(特征|类别)p(类别)}{p(特征)}
p(类别∣特征)=p(特征)p(特征∣类别)p(类别)
通常特征
X
X
X会包含很多元素
x
i
x_i
xi,类别
Y
Y
Y也会包含很多类别
y
k
y_k
yk,所以
p
(
特
征
∣
类
别
)
→
p
(
X
∣
Y
=
y
k
)
p(特征|类别)\rightarrow p(X|Y=y_k)
p(特征∣类别)→p(X∣Y=yk)
然后我们假设所有特征之间都是相互独立的,因此公式可以转换为:
p
(
X
∣
Y
=
y
k
)
=
∏
i
n
p
(
X
=
x
i
∣
Y
=
y
k
)
p
(
X
)
=
p
(
x
1
x
2
…
x
n
)
p(X|Y=y_k) = \prod_i^np(X=x_i|Y=y_k)\\ p(X)=p(x_1x_2\dots x_n)
p(X∣Y=yk)=i∏np(X=xi∣Y=yk)p(X)=p(x1x2…xn)
比如,我们想求
p
(
皮
薄
,
红
,
脆
,
水
分
多
∣
苹
果
甜
)
p(皮薄,红,脆,水分多 | 苹果甜)
p(皮薄,红,脆,水分多∣苹果甜),则可以通过
p
(
皮
薄
∣
苹
果
甜
)
∗
p
(
红
∣
苹
果
甜
)
∗
p
(
脆
∣
苹
果
甜
)
∗
p
(
水
分
多
∣
苹
果
甜
)
p(皮薄 | 苹果甜)*p(红 | 苹果甜)*p(脆 | 苹果甜)*p(水分多 | 苹果甜)
p(皮薄∣苹果甜)∗p(红∣苹果甜)∗p(脆∣苹果甜)∗p(水分多∣苹果甜)得到。
带入到
p
(
类
别
∣
特
征
)
p(类别|特征)
p(类别∣特征)可以得到:
p
(
Y
=
y
k
∣
X
)
=
p
(
Y
=
y
k
)
∏
i
n
p
(
X
=
x
i
∣
Y
=
y
k
)
p
(
x
1
x
2
…
x
n
)
p(Y=y_k|X) = \frac{p(Y=y_k) \prod_i^np(X=x_i|Y=y_k)}{p(x_1x_2\dots x_n)}
p(Y=yk∣X)=p(x1x2…xn)p(Y=yk)∏inp(X=xi∣Y=yk)
由于分母是常数,所以可以直接省略,因为朴素贝叶斯分类器的目的是为了找到使
p
(
Y
=
y
k
∣
X
)
p(Y=y_k|X)
p(Y=yk∣X)最大的
y
k
y_k
yk。
p
(
y
k
∣
X
)
≈
p
(
y
k
)
∏
i
n
p
(
x
i
∣
y
k
)
p(y_k|X) \approx p(y_k) \prod_i^np(x_i|y_k)
p(yk∣X)≈p(yk)i∏np(xi∣yk)
所以朴素贝叶斯分类器的公式如下:
y
^
k
=
a
r
g
m
a
x
y
k
p
(
y
k
)
∏
i
n
p
(
x
i
∣
y
k
)
\hat y_k = argmax_{y_k}p(y_k)\prod_i^np(x_i|y_k)
y^k=argmaxykp(yk)i∏np(xi∣yk)
逻辑回归分类器是基于Logistic函数的,已知如下:
f
(
x
)
=
1
1
+
e
−
x
=
e
x
1
+
e
x
f(x) = \frac{1}{1+e^{-x}} = \frac{e^x}{1+e^x}
f(x)=1+e−x1=1+exex
上述也是逻辑分布在
μ
=
0
,
γ
=
1
μ=0, γ=1
μ=0,γ=1的分布函数。回想一下朴素贝叶斯是通过贝叶斯公式从
p
(
X
∣
y
k
)
p(X|y_k)
p(X∣yk)推出的
p
(
y
k
∣
X
)
p(y_k|X)
p(yk∣X),然而我们可以利用逻辑回归直接建模
p
(
y
k
∣
X
)
p(y_k|X)
p(yk∣X),同时也避免了线性回归的输出不在0-1之间(通过对线性输出进行对数odds)。
为了学习逻辑回归中两个类之间的决策边界,分类器学习与每个数据点相关的权重(θ值),写法如下:
二
元
分
类
时
,
p
(
y
k
∣
X
;
θ
)
=
1
1
+
e
x
p
(
−
(
θ
0
+
∑
f
=
1
F
θ
f
x
f
)
)
=
1
1
+
e
x
p
(
θ
T
X
)
多
元
分
类
时
,
使
用
s
o
f
t
m
a
x
:
p
(
y
k
∣
X
;
θ
)
=
e
x
p
(
θ
c
T
X
)
∑
f
e
x
p
(
θ
f
T
X
)
二元分类时,p(y_k|X;\theta) = \frac{1}{1+exp(-(\theta_0+\sum_{f=1}^F\theta_fx_f))}=\frac{1}{1+exp(\theta^TX)} \\ 多元分类时,使用softmax:p(y_k|X;\theta) = \frac{exp(\theta_c^TX)}{\sum_fexp(\theta^T_fX)}
二元分类时,p(yk∣X;θ)=1+exp(−(θ0+∑f=1Fθfxf))1=1+exp(θTX)1多元分类时,使用softmax:p(yk∣X;θ)=∑fexp(θfTX)exp(θcTX)
此时我们最后得到的分类
y
k
y_k
yk也是通过寻找最大概率得到的。
y
^
=
a
r
g
m
a
x
y
k
p
(
y
k
∣
X
)
\hat y = argmax_{y_k}p(y_k|X)
y^=argmaxykp(yk∣X)
如果把
p
(
y
k
∣
X
)
p(y_k|X)
p(yk∣X)又通过贝叶斯转换得到
p
(
X
∣
y
k
)
p
(
y
k
)
p(X|y_k)p(y_k)
p(X∣yk)p(yk),就又得到了先前的朴素贝叶斯生成分类器。然而
p
(
X
∣
y
k
)
p
(
y
k
)
p(X|y_k)p(y_k)
p(X∣yk)p(yk)又等于
p
(
X
∣
y
k
)
p(X|y_k)
p(X∣yk),即
X
,
y
k
X,y_k
X,yk的联合分布。这一观察结果支持了生成分类器的早期定义。通过对类之间的联合概率分布进行建模,在给定标签 Y 和联合概率分布的情况下,生成模型可用于获取和“生成”输入点 X。类似地,判别模型通过学习条件概率分布,学习了分隔数据点的决策边界。因此,给定一个输入点,它可以使用条件概率分布来计算它的类别。
这些定义如何应用于条件随机场(Conditional Random Field, CRF)?条件随机场是一种判别模型,其基本原理是将逻辑回归应用于序列输入。如果熟悉隐马尔可夫模型(HMM),就会发现它们与 CRF 有一些相似之处,其中之一是它们也用于序列输入。HMM 使用状态转移矩阵和输入向量来学习发射(观测)矩阵,并且在概念上类似于朴素贝叶斯。HMM 是一种生成模型。
条件随机场的数学概述
讨论了上述定义后,我们现在将讨论条件随机场,以及如何使用它们来学习序列数据。
正如我们在上一节中所展示的,我们对条件分布建模如下:
y
^
=
a
r
g
m
a
x
y
p
(
y
∣
x
)
\hat y = argmax_{y}p(y|x)
y^=argmaxyp(y∣x)
在 CRF 中,我们的输入数据是连续的,在对数据点进行预测时,我们必须考虑先前的上下文。为了建模这种行为,我们将使用特征函数,它有多个输入值,它们将是:
- 输入向量集合 X
- 我们正在预测的数据点的位置 i
- X中数据点i-1的标签
- X中数据点i的标签
我们将特征函数定义为:
f
(
X
,
i
,
l
i
−
1
,
l
i
)
f(X,i,l_{i-1},l_i)
f(X,i,li−1,li)
特征函数的目的是表达数据点所代表的序列的某种特征。例如,如果我们使用 CRF 进行词性标注,那么:
如果
l
i
−
1
l_{i - 1}
li−1 是名词,
l
i
l_{i}
li 是动词,那我们认为
f
(
X
,
i
,
l
i
−
1
,
l
i
)
=
1
f (X, i, l_{i - 1}, l_{i} ) = 1
f(X,i,li−1,li)=1,也可以理解为这种顺序是合理的。否则为 0 。
类似地,如果
l
i
−
1
l_{i - 1}
li−1 是动词且
l
i
l_{i}
li是副词,则
f
(
X
,
i
,
l
i
−
1
,
l
i
)
=
1
f (X, i, l_{i - 1}, l_{i} ) = 1
f(X,i,li−1,li)=1 。否则为 0 。
每个特征函数都基于前一个词和当前词的标签,并且是 0 或 1。为了构建条件字段,我们接下来为每个特征函数分配一组权重(λ值),公式如下(回想一下逻辑回归,记得CRF基本原理是将逻辑回归应用于序列输入):
P
(
y
∣
X
,
λ
)
=
1
Z
(
X
)
e
x
p
∑
i
=
1
n
∑
j
λ
j
f
i
(
X
,
i
,
y
i
−
1
,
y
i
)
其
中
:
Z
(
X
)
=
∑
y
′
∈
y
∑
i
=
1
n
∑
j
λ
j
f
i
(
X
,
i
,
y
i
−
1
′
,
y
i
′
)
P(y | X,\lambda) = \frac{1}{Z(X)}exp{\sum_{i=1}^n\sum_j\lambda_jf_i(X,i,y_{i-1},y_i)}\\ 其中:Z(X)=\sum_{y'\in y}\sum^n_{i=1}\sum_j \lambda_jf_i(X,i,y'_{i-1},y'_i)
P(y∣X,λ)=Z(X)1expi=1∑nj∑λjfi(X,i,yi−1,yi)其中:Z(X)=y′∈y∑i=1∑nj∑λjfi(X,i,yi−1′,yi′)
为了估计参数 (λ),我们将使用最大似然估计。我们首先取分布的负对数(softmax通常和它搭配),以使偏导数更易于计算:

为了在负对数函数上应用最大似然,我们将采用argmin(因为最小化负数将产生最大值)。为了找到最小值,我们可以对 lambda 进行偏导,并得到:
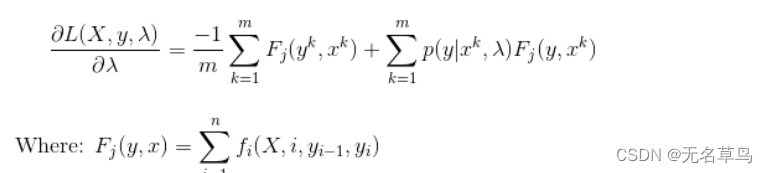
我们使用偏导作为梯度下降的一个步骤。梯度下降迭代地更新参数值,步长很小,直到值收敛。我们最终的 CRF 梯度下降更新方程是:
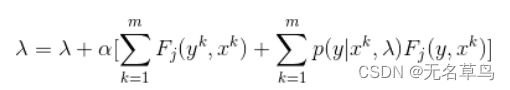
总而言之,我们使用条件随机场首先定义所需的特征函数,将权重初始化为随机值,然后迭代地应用梯度下降,直到参数值(在本例中为 lambda)收敛。我们可以看到 CRF 类似于 Logistic 回归,因为它们使用条件概率分布,但是我们通过将特征函数作为我们的顺序输入来扩展算法。
CRF 与隐马尔可夫模型有何不同
从前面的部分可以看出,条件随机场与隐马尔可夫模型有何不同。尽管两者都用于对顺序数据进行建模,但它们是不同的算法。
隐马尔可夫模型是生成的,并通过对联合概率分布建模来给出输出。另一方面,条件随机场具有判别性,并对条件概率分布进行建模。CRF 不依赖独立性假设(标签相互独立),并避免标签偏差。一种看待它的方法是,隐马尔可夫模型是条件随机场的一种非常特殊的情况,而是使用恒定的转移概率。HMMs 基于朴素贝叶斯,我们说它可以从逻辑回归中推导出来,而 CRF 就是从其中推导出来的。
CRF的应用
鉴于 CRF 能够对序列数据进行建模,CRF 通常用于自然语言处理,并且在该领域有很多应用。我们讨论的一个这样的应用是词性标注。句子的词性依赖于先前的单词,通过使用利用这一点的特征函数,我们可以使用 CRF 来学习如何区分句子中的哪些词对应于哪个 POS。另一个类似的应用是命名实体识别,或从句子中提取专有名词。条件随机场可用于预测多个变量相互依赖的任何序列。其他应用包括图像中的部分识别和基因预测。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)