
mobilenetv1,v2,v3简要介绍
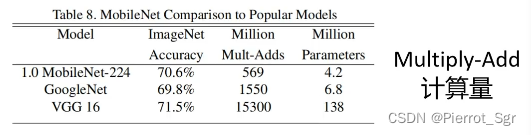
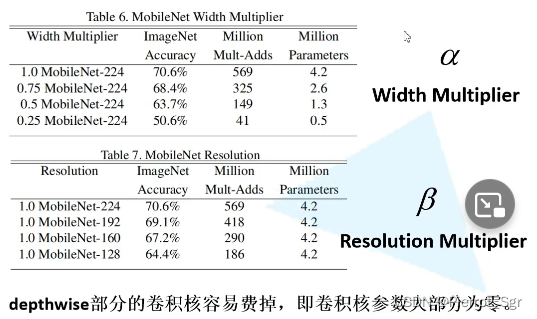
mobilenetv11.mobilenetv1的一个主要特点是网络所需要的参数很少,以至于在手机这种移动设备上都可以跑,在准确率小幅度降低的代价下,可以再次大幅度减少我们的参数量,如下图mobilenetv1和vgg16相比准确率只下降了0.9%,但是参数量从15300m和138m,下降到了569m和4.2m,大大的降低了参数量2.mobilenet使用了dw卷积大幅度减少了运算量和参数量,从输
mobilenetv1
1.mobilenetv1的一个主要特点是网络所需要的参数很少,以至于在手机这种移动设备上都可以跑,在准确率小幅度降低的代价下,可以再次大幅度减少我们的参数量,如下图mobilenetv1和vgg16相比准确率只下降了0.9%,但是参数量从15300m和138m,下降到了569m和4.2m,大大的降低了参数量
2.mobilenet使用了dw卷积大幅度减少了运算量和参数量,从输入到输出,c是不会改变的
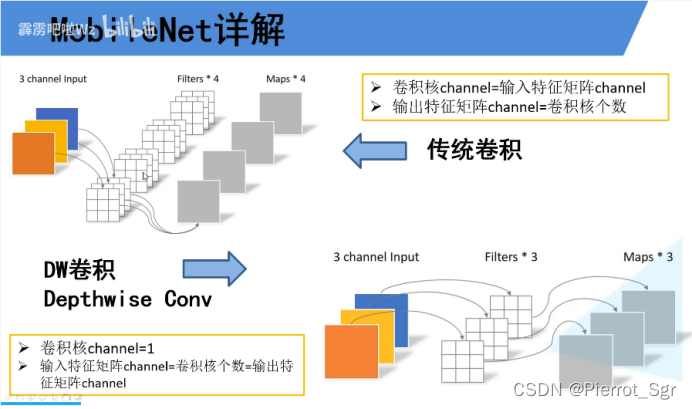
同时也使用了pw卷积
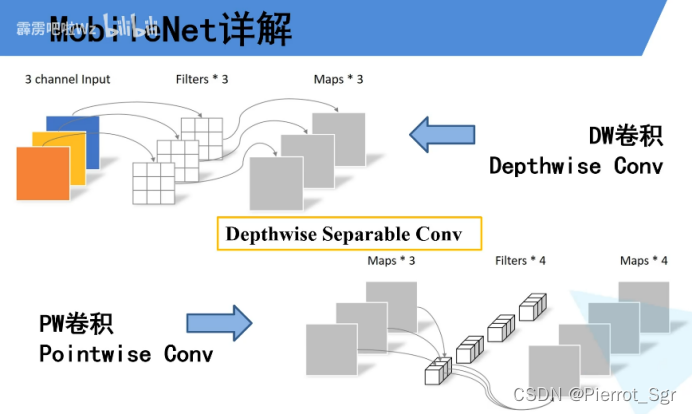
pw卷积的特点是卷积核的维度是1*1,从输入到输出可以改变维度,dw和pw通常是一起使用的
dw和pw的使用可以大大减少参数量,通常是普通卷积参数的1/8-1/9(这里不做推理)
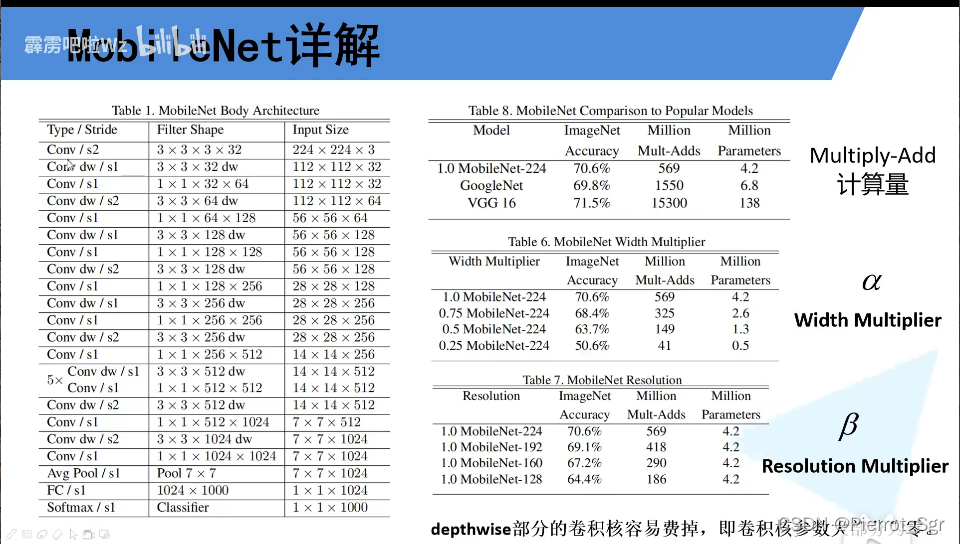
conv/s2:使用普通的卷积,stride=2
filter3*3*3*32:卷积核的尺寸为尺寸为3*3,深度为3,卷积核个数为32
conv dw/s1:使用dw卷积因为dw卷积的深度为1,第三个参数就没写,s=1,尺寸为3*3,个数为32
3.引入了超参数和
指是卷积核的倍率,值越大,则使用的卷积核数量越多,
就算大幅度降低,准确率也不会降低太多,但是参数量会大幅度降低
指的是输入的图像的尺寸图像的大小从224到128,准确率小幅度降低,但是参数量会大幅度降低
mobilenetv2
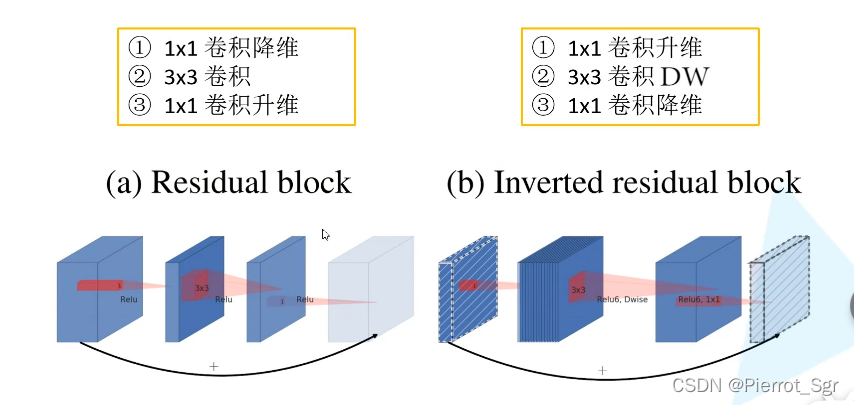
与v1相比v2的模型跟小,但准确(inverted residuals),和resnet一样,v2也有一个short cut,但resnet的是一个两边大,中间小的结构,但是v2是一个两边小,中间大的结构。
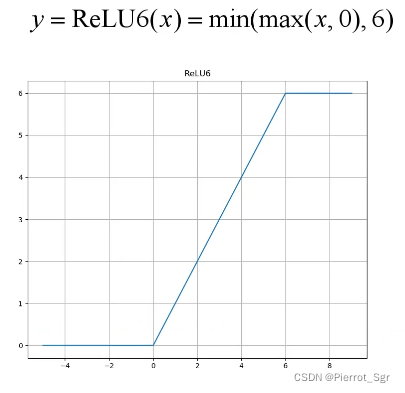
reset中采用的是relu函数,但v2中使用的是relu6激活函数,与普通的relu相比,就是给函数设置了一个上限为6,在x=6及其以后的值都为6。
特点2:linear bottleneck

在我们倒残差的最后一个1*1的卷积层,它使用了一个线性的激活函数(个人理解是relu激活函数在低维度的信息会造成较大的损失,高维信息造成的损失很小,就使用一个线性的激活函数,防止我们损失太多的信息)
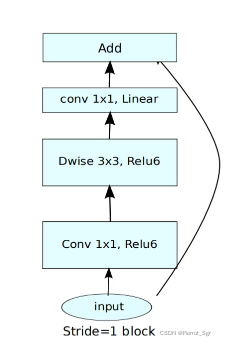
倒残差结构中先使用的是一个1*1的卷积核,使用relu6激活函数,再使用3*3的卷积核,使用dw卷积,最后使用一个1*1的卷积核,使用的是一个linear线性函数并不是每一个结构中都有short cut,只有当s=1,且输入矩阵和输出矩阵的shape相同的时候才会有short cut
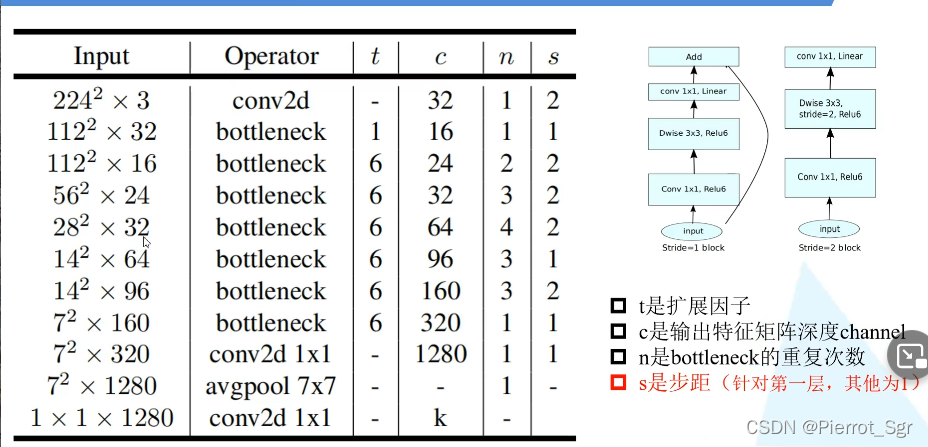

t是我们的扩展因子如第一层我们的深度是k,我们的扩展因子为t,则我们的输出因子的深度为tk
(最后一层实现的是一个降维的处理,从tk到)
c:输出特征矩阵的深度channel
n:linear bottleneck重复的次数
s:指的是每一个block它的第一个bottleneck的步距,其他情况下s都为1
![]()
这里的最后一层是一个卷积层,但是是1*1的会起到和全连接层一样的作用效果
mobilenetv3
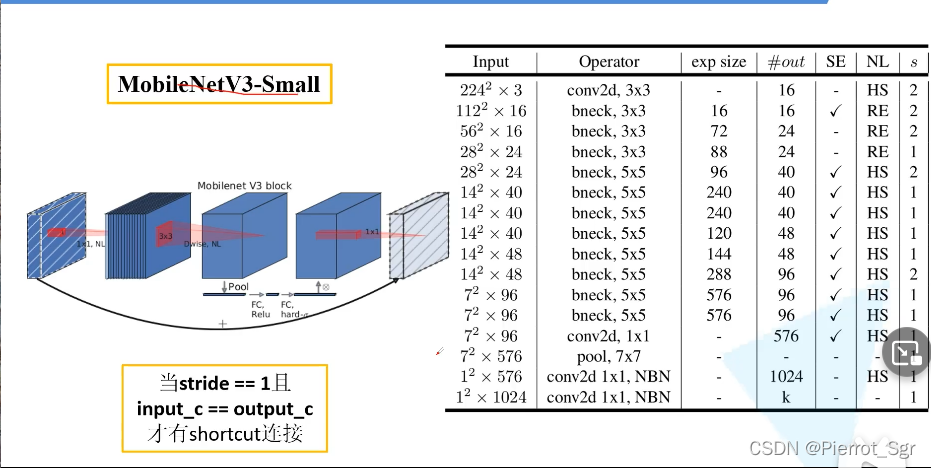
mobilenetv3有large和small两种版本
large版本
特点1:更新了block(在倒残差的结构上进行了轻微的改动)
加入了se机制(注意力机制),以及激活函数的更新
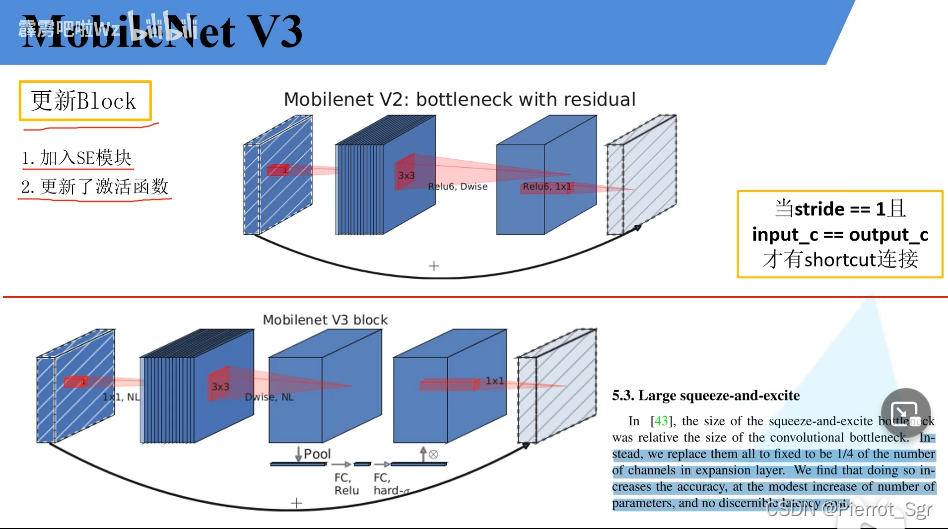
最明显的改变还是我们的注意力机制

我们得到的特征矩阵,我们对它每一个channel进行一个池化处理,我们有多少个channel,我们池化后得到的一维向量就会有多少个元素,之后通过两个全连接层,第一个全连接的节点个数是我们channel的1/4,第二个全连接层节点个数和我们的一维向量节点个数是相等的

如图是一个se机制的示意图,我们 特诊矩阵的c为2,我们会经过一个平均池化的操作,得到一个一维向量,c为2,则元素个数也为2,第一个fc的节点个数是c的1/4,我们这里举的例子不太正确,但实际情况下,我们的c是一个很大的数,第一个fc我们使用的是一个relu激活函数,第二个fc节点个数和c是相等的,则节点个数为2,使用的激活函数为hard-sigmoid函数(后面会讲到),最后我们得到一个两个元素的向量,两个值一一对应的是我们两个矩阵的权重,例如我们第一个矩阵的权重是0.5,则我们将其这个权重0.5和我们矩阵中的每一个元素进行相乘,得到我们新的矩阵,第二个权重0.6也是如此
![]()
这里的两个地方写了nl,nl指的就是我们的非线性激活函数,不用的层之间使用的非线性激活函数是不一样的,我们这里统称为nl
特点2:nas搜索参数(这里不做讲解)
特点3:重新设计耗时层结构
1.
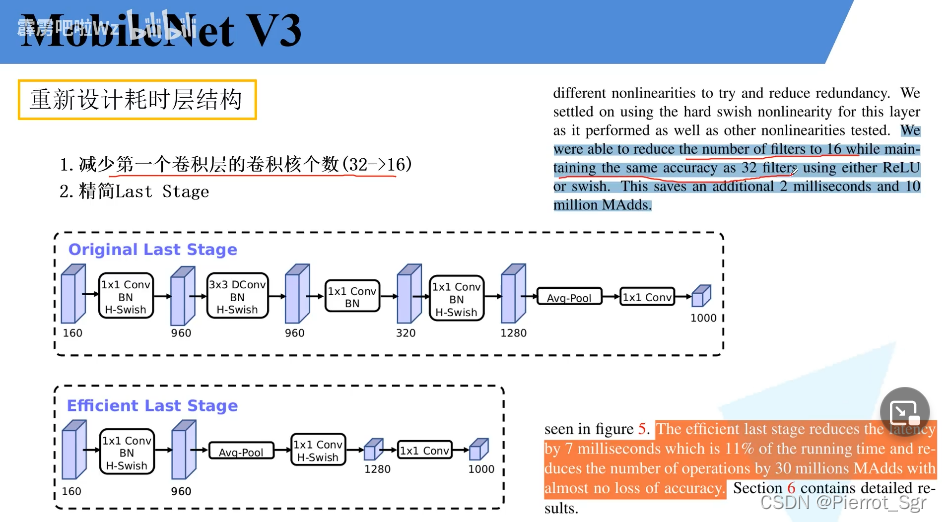
第一层卷积核的个数我们从32降为了16,v3的作者发现,用16和32的准确率是一样的,就减少了卷积核的数量
2.精简了last stage
在nas搜索出来的最后一个网络结构我们称之为last stage,大致流程如下

作者发现这个original last stage是一个比较耗时的结构,就将其进行了改变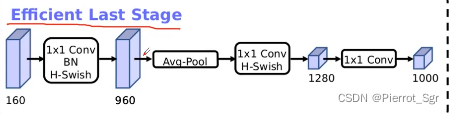
减少了很多层的结构,但准确率并没有太大的变化、
激活函数
hard-sigmoid函数
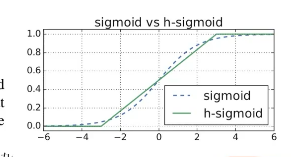
hard-sigmoid函数的图像和我们的sigmoid函数图像十分相似,有些时候我们会用hard-sigmoid来代替sigmoid函数
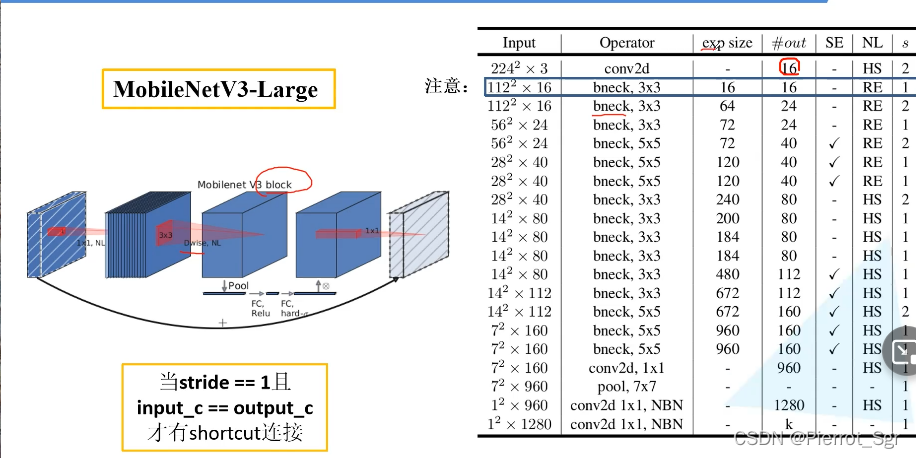
如图是我们v3 large的结构图
swish激活函数![]()
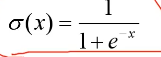
hard-swish激活函数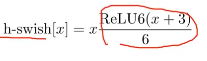
exp size:指的就是我们需要升的维度exp size为16时我们就要用1*1的卷积核将我们的矩阵升到多少维
#out:我们经过se之后我们需要降的维度,#out为16时,我们就要用1*1的卷积核将其降为到16
SE:打勾就是要使用我们的注意力机制,不打勾就不使用
HS:hard-swish函数
RE:relu激活函数
s:步距stride
NBN:有NBN的卷积层不使用bn层结构![]()
这两层就相当于一个fc结构
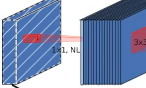
bneck就是我们更新的block结构
这里有一点需要注意,第一个bneck结构的input和out都是16![]()
故它一开始没有1*1的卷积,其他结构都有
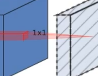
small版本的结构图如下,不做过多解释,内容和large版本差不多
small版本也是如此,第一个bneck结构没有1*1的卷积
![]()

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)