【自然语言处理NLP】三句半自动生成器
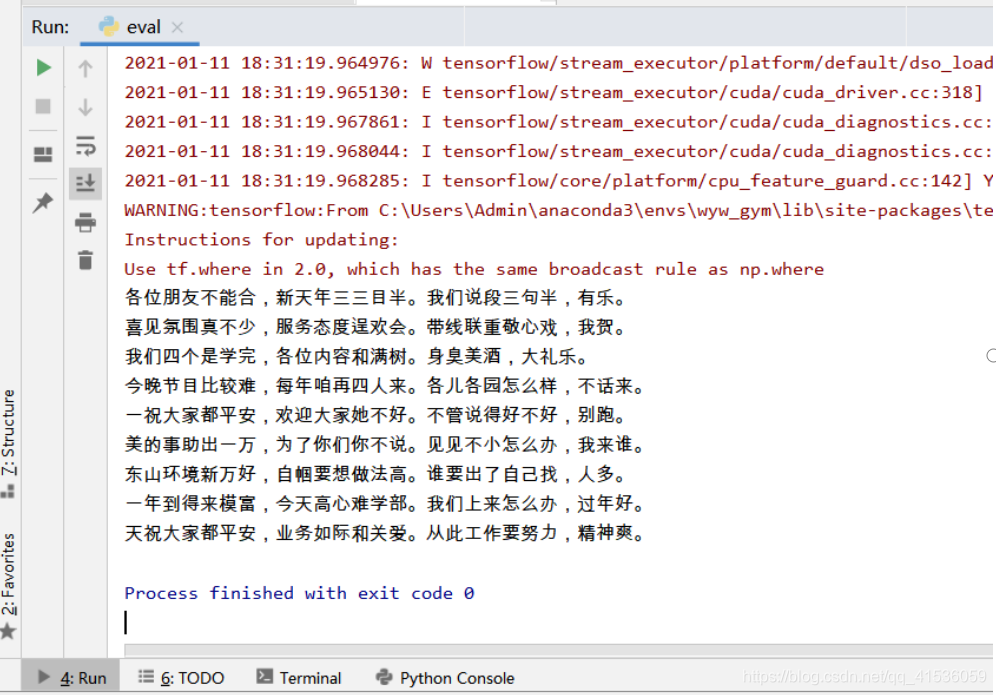
NLP课程期末项目:基于LSTM的三句半生成器训练语料数据集:三句半语料数据集实现模型:双层LSTM模型参考:LSTM古诗生成训练结果如下,由于三句半的资源比较少,现有的样本是在爬取了多个网站后能获得到的最大样本,数据集数量较少,因此网络表现结果一般,还不能很好的生成三句半,只有部分词语是合理。不过令人可喜的是,有些位置的预测可以根据训练集中的内容压到韵脚,我们相信,如果有更丰富全面的数据,网络的
·
基于LSTM的三句半生成器
- 训练语料数据集:三句半语料数据集
- 实现模型:双层LSTM
运行环境:Windows+pycharm+python3.6+tensorflow2.0
模型参考:LSTM古诗生成
数据集:【python爬虫】爬取网站数据,整理三句半语料数据集
整个项目已上传到github:https://github.com/VivianW-Happy/crosstalk_generator
训练结果如下,由于三句半的资源比较少,现有的样本是在爬取了多个网站后能获得到的最大样本,数据集数量较少,因此网络表现结果一般,还不能很好的生成三句半,只有部分词语是合理。不过令人可喜的是,有些位置的预测可以根据训练集中的内容压到韵脚,我们相信,如果有更丰富全面的数据,网络的训练结果会更好。:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)