新冠肺炎预测模型-代码详解(比赛项目)
新冠肺炎预测模型(比赛项目)赛题介绍数据预处理数据分析与可视化模型搭建以及训练模型预测赛题介绍随着2020年的疫情爆发数据预处理数据分析与可视化模型搭建以及训练模型预测
新冠肺炎预测模型-代码详解(比赛项目)
本人于重庆某普通大学刚毕业大学生一枚,第一次写文章,有不足之处请各位大佬指出,望各位大佬李姐李姐。
1. 数据集介绍
本文章使用的是2020年本人参加的一个中国大学生计算机设计大赛-人工智能挑战赛的一个比赛,该比赛的题目是基于新冠病毒的,由于当时处于新冠病毒爆发后开始逐渐控制的时期,对人工智能这块也是刚接触所以去参加了这个比赛。
数据集指标描述:
本次数据集由中国大学生计算机设计大赛官方给出,共有一个excel文件,其中包括中国各地区各城市的迁入和迁出的规模,其单位是迁徙规模指数=>反映迁入或迁出人口规模,城市间可横向对比;从武汉到其他各个城市的迁出比例,即迁徙人口与户籍人口的百分比(#N/A为缺失值);各个地区的累计感染人数。
训练集与测试集:
该数据集中迁徙规模指数和武汉迁出比例包括2020年1月10日至2020年1月24日的数据,训练的 X将使用1月10日至1月16日数据作为训练集,1月17日至1月24日作为训练集。使用各地区累计感染人数,1月24日和1月30日作为训练集,1月31日和2月6日作为测试集的 Y。
图示:



2. 数据预处理
经过数据特征分析发现提供的数据存在缺失值、异常值,地区名称口径、格式不统一等问题。
2.1 读取数据
读取训练集的数据
# 导入相关库
import pandas as pd
import numpy as np
from math import isnan
# 读取训练数据(迁入、迁出、武汉迁出比例)
qr=pd.read_excel('./AI 2020 04 data01.xlsx', sheet_name='迁入', index_col=[0,1])
qc=pd.read_excel('./AI 2020 04 data01.xlsx', sheet_name='迁出', index_col=[0,1])
qc_bili = pd.read_excel('./AI 2020 04 data01.xlsx', sheet_name='1.10-1.16武汉迁出比例', index_col=0)
qc_train = qc.iloc[:,:7]
qr_train = qr.iloc[:,:7]
2.2 缺失值处理
查看数据缺失情况
qr_train.info()
qc_train.info()

发现迁入迁出数据有9条缺失值,采用填补法进行缺失值处理,具体填补方法采用均值填补(利用缺失数据的城市找到其地区,使用该地区的平均值进行填补);又发现台湾、澳门、香港是独立的城市,并没有能够填补的数据,所以我们将这三个地区的数据填充为0。
2.3 分割省市
由于迁入迁出数据和武汉迁出比例城市地区格式、口径不一致,为了将多个表通过索引连接在一起,需要统一其格式。
# 提取武汉迁出比例数据中的地区城市数据
# 分割出地区与城市
areas=[]
for i in qc_bili.iloc[:,0].values:
if '市' in i:
w=i.split('市')
areas.append([w[1][:2],w[0]])
elif '州' in i:
z=i.split('州')
areas.append([z[1][:2],z[0]])
areas_df = pd.DataFrame(areas,columns=['省份','地区'])
areas_df.iloc[94,0] = '贵州'
areas_df.iloc[94,1] = '黔东南州'
areas_df.iloc[11,1] = '恩施州'
areas_df.iloc[61][0] = '黑龙江'
areas_df
清洗好的地区格式如下图
将清洗好的地区-城市替换之前的地区城市,并设置为索引。
qc_bili.drop(qc_bili.columns[0],axis=1,inplace=True)
qc_bili[['省份','地区']] = areas_df[['省份','地区']]
qc_bili.set_index(['省份','地区'],inplace=True)
2.4 武汉迁出比例缺失值处理
qc_bili_nan = qc_bili[qc_bili.isna().values==True].drop_duplicates()
index_nan=qc_bili_nan.index
# 将武汉迁出比例缺失值补为平均值
k=0
for i in index_nan:
for j in range(len(qc_bili.loc[i])):
qc_bili.loc[i].iloc[j]=qc_bili_nan.mean(axis=1).values[k]
k=k+1
qc_train.reset_index(inplace=True)
qc_bili.reset_index(inplace=True)
qr_train.reset_index(inplace=True)
qc_bili.set_index(['省份','地区'],inplace=True)
qc_train.rename(columns={'迁徙规模指数(单位):反映迁入或迁出人口规模,城市间可横向对比':'省份'},inplace=True)
qc_train.set_index(['省份','地区'],inplace=True)
qr_train.rename(columns={'迁徙规模指数(单位):反映迁入或迁出人口规模,城市间可横向对比':'省份'},inplace=True)
qr_train.set_index(['省份','地区'],inplace=True)
2.5 将迁入、迁出和比例连接到一起,最终形成训练集
train1 = pd.merge(qr_train, qc_train, right_index=True, left_index=True, how='outer')
train2 = pd.merge(train1, qc_bili, right_index=True, left_index=True, how='outer')
a = {
'1.1_x' : '1.10迁入指数',
'1.11_x' : '1.11迁入指数',
'1.12_x' : '1.12迁入指数',
'1.13_x' : '1.13迁入指数',
'1.14_x' : '1.14迁入指数',
'1.15_x' : '1.15迁入指数',
'1.16_x' : '1.16迁入指数',
'1.1_y' : '1.10迁出指数',
'1.11_y' : '1.11迁出指数',
'1.12_y' : '1.12迁出指数',
'1.13_y' : '1.13迁出指数',
'1.14_y' : '1.14迁出指数',
'1.15_y' : '1.15迁出指数',
'1.16_y' : '1.16迁出指数',
1.1 : '1.10比例',
1.11 : '1.11比例',
1.12 : '1.12比例',
1.13 : '1.13比例',
1.14 : '1.14比例',
1.15 : '1.15比例',
1.16 : '1.16比例',
}
train2.rename(columns=a, inplace=True)
train2.fillna(0, inplace=True) # 把比例中武汉人没去的地区补为0
2.6 测试数据预处理
测试数据预处理与训练数据预处理步骤基本一致,这里不做冗余的解释了哈
2.7 导出excel
# 读取y(累计感染人数),并重新构造y
ys = pd.read_excel('./AI 2020 04 data01.xlsx',sheet_name='疫情数据(累计)',index_col=[0,1])
ys.fillna(0,inplace=True)
# 将累计感染人数转化为7天新增感染人数
ys['y_训练集'] = ys['2020-01-30']-ys['2020-01-24']
ys['y_测试集'] = ys.iloc[:,-2]-ys.iloc[:,-3]
# 合并训练集和测试集的X和y
finaly_train = pd.merge(train2,ys['y_训练集'],right_index=True,left_index=True).reset_index().drop(columns='单位:人(空白为该时间点数据没有记录)').set_index(['省份','地区'])
finaly_test = pd.merge(test888,ys['y_测试集'],right_index=True,left_index=True).reset_index().drop(columns='单位:人(空白为该时间点数据没有记录)').set_index(['省份','地区'])
# 导出为excel
finaly_train.to_excel(r'./训练集.xlsx')
finaly_test.to_excel(r'./测试集.xlsx')
3. 数据分析与可视化
导入相关库,并读取相关所有数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pyecharts.charts import Map
from pyecharts.charts import Bar
from pyecharts import options as opts
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
Train=pd.read_excel(r'./训练集.xlsx',index_col=[0,1])
Test=pd.read_excel(r'./测试集.xlsx',index_col=[0,1])
Movein=pd.read_excel(r'./AI 2020 04 data01.xlsx',sheet_name='迁入',index_col=[0,1])
Moveout=pd.read_excel(r'./AI 2020 04 data01.xlsx',sheet_name='迁出',index_col=[0,1])
WH_move_bili=pd.read_excel(r'./AI 2020 04 data01.xlsx',sheet_name='1.17-1.23武汉迁出比例',index_col=[0,1])
Disease_data=pd.read_excel(r'./AI 2020 04 data01.xlsx',sheet_name='疫情数据(累计)',index_col=[0,1])
3.1 画出各地区疫情严重程度(截至2.6累计确诊)
使用matplotlib以及pyecharts进行数据可视化展示
# 构造可视化所需数据
disase_provence=(pd.DataFrame(Disease_data.iloc[:,-1]).reset_index()).groupby(by='单位:人(空白为该时间点数据没有记录)').sum()
keys=disase_provence.index.tolist()
values=disase_provence.values.reshape(34,).tolist()
map=Map()
map.set_global_opts(
title_opts=opts.TitleOpts(title="20200206各地区疫情"),
visualmap_opts=opts.VisualMapOpts(max_=22112, is_piecewise=True,
pieces=[
{"max": 23000, "min": 2000, "label": ">2000", "color": "#8A0808"},
{"max": 2000, "min": 1000, "label": "1000-2000", "color": "#B40404"},
{"max": 1000, "min": 100, "label": "100-1000", "color": "#DF0101"},
{"max": 100, "min": 10, "label": "10-100", "color": "#F78181"},
{"max": 10, "min": 0, "label": "0-10", "color": "#F5A9A9"},
{"max": 0, "min": 0, "label": "0", "color": "#fff"},
]) #最大数据范围,分段
)
map.add('20200206各地区疫情',data_pair=list(dict(zip(keys,values)).items()),maptype='china',is_roam=True)
map.render_notebook()
展示结果:

结论:
1.从图可看出,疫情的走势从发源地开始,依次向外传播
2.疫情严重程度跟人口密度有很大的关系
3.跟地区人口流动也有关系
湖北省的疫情数据(2.6累计新增)
# 规范地区-城市名称
area_hubei=[]
for i in Disease_data.loc['湖北'].index.tolist():
i=i+'市'
area_hubei.append(i)
area_hubei[-3]='恩施土家族苗族自治州'
area_hubei[-1]='神农架林区'
# 绘图
people_hubei=dict(zip(area_hubei,Disease_data.loc['湖北'].iloc[:,-1].values.tolist()))
hubeimap=Map()
hubeimap.set_global_opts(
title_opts=opts.TitleOpts(title="湖北各地区疫情"),
visualmap_opts=opts.VisualMapOpts(max_=11618, is_piecewise=True,
pieces=[
{"max": 15000, "min": 2000, "label": ">2000", "color": "#8A0808"},
{"max": 2000, "min": 1000, "label": "1000-2000", "color": "#B40404"},
{"max": 1000, "min": 500, "label": "500-1000", "color": "#DF0101"},
{"max": 500, "min": 100, "label": "100-500", "color": "#F78181"},
{"max": 100, "min": 10, "label": "10-100", "color": "#F5A9A9"},
], ) #最大数据范围,分段
)
hubeimap.add('湖北各地区累计人数(2020206)',
data_pair=list(people_hubei.items())
,maptype='湖北',is_roam=True)
hubeimap.render_notebook()
展示结果:

结论:
1.湖北省内,越靠近发源地(武汉)的越严重
2.武汉迁入孝感,黄冈的人数较多
对疫情较严重的地区进行分析(春节期间,春运)
武汉,孝感,黄冈(迁入)
Movein_Bad_areas = Movein.iloc[:3]
plt.figure(figsize=(9,5))
plt.plot(Movein_Bad_areas.columns,Movein_Bad_areas.iloc[0],label='武汉')
plt.plot(Movein_Bad_areas.columns,Movein_Bad_areas.iloc[1],label='孝感')
plt.plot(Movein_Bad_areas.columns,Movein_Bad_areas.iloc[2],label='黄冈')
plt.xlabel('日期')
plt.ylabel('迁入指数')
plt.xticks(Movein_Bad_areas.columns)
plt.legend()
plt.show()
展示结果:

结论:
1.在22号前(春节之前),各地方迁入呈上升趋势
2.在21后过后疫情爆发后,这三个地区的迁入指数明显下降
3.在23号,武汉宣布封城之后,武汉的迁入达到最低
主要地区迁出(武汉,北上广深)
MajorAreas=Moveout.loc[[('湖北','武汉'),('北京','北京'),('上海','上海'),('广东','广州'),('广东','深圳')]]
plt.figure(figsize=(9,5))
plt.plot(MajorAreas.columns,MajorAreas.iloc[0],label='武汉')
plt.plot(MajorAreas.columns,MajorAreas.iloc[1],label='北京')
plt.plot(MajorAreas.columns,MajorAreas.iloc[2],label='上海')
plt.plot(MajorAreas.columns,MajorAreas.iloc[3],label='广州')
plt.plot(MajorAreas.columns,MajorAreas.iloc[4],label='深圳')
plt.xlabel('日期')
plt.ylabel('迁出指数')
plt.xticks(MajorAreas.columns)
plt.legend()
plt.show()
展示结果:

结论:
1.在21号之前为返程高峰期(春运),21号为返程顶峰
2.21号后过后受疫情影响,返程收到较大影响
3.23号为武汉封城,在22号武汉迁出达到顶峰
二十个城市(新增感染人数)
Total_add_people = pd.DataFrame(Test.iloc[:,-1]+Train.iloc[:,-1]).sort_values(by = 0,ascending=False)
Total_add_people.reset_index(inplace=True)
Top_20_x=Total_add_people.iloc[1:21]['地区']
Top_20_y1=Train.loc[[tuple(i) for i in Total_add_people.iloc[1:21][['省份','地区']].values]].iloc[:,-1]
Top_20_y2=Test.loc[[tuple(i) for i in Total_add_people.iloc[1:21][['省份','地区']].values]].iloc[:,-1]
bar=(
Bar()
.add_xaxis(Top_20_x.values.tolist())
.add_yaxis("1.24—1.30新增人数", Top_20_y1.tolist())
.add_yaxis("1.31—2.6新增人数",Top_20_y2.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="二十个城市(新增感染人数)"))
)
bar.render_notebook()
展示结果:
 疫情严重二十个城市(迁徙指数)
疫情严重二十个城市(迁徙指数)
Top20_qianxi_y1=Train.loc[[tuple(i) for i in Total_add_people.iloc[1:21][['省份','地区']].values]].iloc[:,:14].sum(axis=1)
Top20_qianxi_y2=Test.loc[[tuple(i) for i in Total_add_people.iloc[1:21][['省份','地区']].values]].iloc[:,:14].sum(axis=1)
bar2=(
Bar()
.add_xaxis(Top_20_x.values.tolist(),)
.add_yaxis("1.10—1.16迁徙规模指数", Top20_qianxi_y1.round(decimals=0).tolist())
.add_yaxis("1.17—1.23迁徙规模指数",Top20_qianxi_y2.round(decimals=0).tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="疫情严重二十个城市(迁徙指数)"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
)
bar2.render_notebook()
展示结果:

武汉迁入地区比例
Top20_bili_y1=Train.loc[[tuple(i) for i in Total_add_people.iloc[1:21][['省份','地区']].values]].iloc[:,14:21].sum(axis=1)
Top20_bili_y2=Test.loc[[tuple(i) for i in Total_add_people.iloc[1:21][['省份','地区']].values]].iloc[:,14:21].sum(axis=1)
bar3=(
Bar()
.add_xaxis(Top_20_x.values.tolist(),)
.add_yaxis("1.10—1.16武汉迁入地区比例", Top20_bili_y1.tolist())
.add_yaxis("1.17—1.23武汉迁入地区比例",Top20_bili_y2.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="二十个城市(比例)"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
bar3.render_notebook()
展示结果:

结论:
1.通过柱状图分析,武汉人迁出比例与各地新增人数趋势相似
2.各地新增人数与各地迁徙指数相关性不强
4. 模型搭建以及训练
4.1 导入相关包和数据集
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler,PolynomialFeatures
from sklearn.neural_network import MLPRegressor
from sklearn.linear_model import LinearRegression as LR
from sklearn.metrics import r2_score
Train=pd.read_excel(r'./训练集.xlsx',index_col=[0,1])
Test=pd.read_excel(r'./测试集.xlsx',index_col=[0,1])
由于武汉为疫情爆发城市其各项数据都比较偏大,因此将武汉数据作为异常数据删除。
Train.drop(index=('湖北','武汉'),inplace=True)
Test.drop(index=('湖北','武汉'),inplace=True)
将迁入迁出求和和比例求和,作为2个X
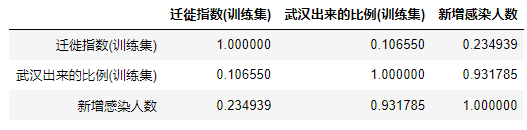
New_train=pd.DataFrame(Train.iloc[:,0:14].sum(axis=1),columns=['迁徙指数(训练集)'])
New_train['武汉出来的比例(训练集)']=Train.iloc[:,14:21].sum(axis=1).values
New_train['新增感染人数']=Train.iloc[:,-1].values
New_train.corr() # 相关系数分析 - 新增感染人数跟比例的相关性最大
将测试集做同样的处理,就不用多解释了。
4.2 建模(多层感知机)
定义标准化方法
sc_X = StandardScaler()
sc_Y = StandardScaler()
模型搭建和训练
# 模型创建
mlp_model = MLPRegressor(verbose=True,
learning_rate_init=0.01,
max_iter=1000,
hidden_layer_sizes=(10,2),
alpha=0.001,
random_state=94
)
# 标准化
sc_X_stder = sc_X.fit_transform(New_train.iloc[:,[0,1]].values)
sc_Y_stder = sc_Y.fit_transform(New_train.iloc[:,2].values.reshape(-1,1))
# 多项化
poly_feat = PolynomialFeatures()
poly_feat_X = poly_feat.fit_transform(sc_X_stder)
# 训练
mlp_model.fit(poly_feat_X,sc_Y_stder.reshape(368))
# 测试
y_test = New_test.iloc[:,2].values.reshape(-1,1) #y_test为测试集真实值
mlp_model.score(poly_feat_X,sc_Y_stder) # MLP模型训练集上的R2:0.9119120262411091
sc_X_stder_test = sc_X.transform(New_test.iloc[:,[0,1]].values) # 测试集X归一化
poly_feat_X_test = poly_feat.transform(sc_X_stder_test) # 多项式化
y_test_pred = mlp_model.predict(poly_feat_X_test)
sc_Y_true = sc_Y.inverse_transform(y_test_pred) #将预测结果反归一化
r2_score(y_test,sc_Y_true) # 测试集上的R2:0.7352483160384201
4.3 建模(多项线性回归)
模型搭建和训练
# 定义模型
lr_model = LR()
# 标准化
sc_X_stder = sc_X.fit_transform(New_train.iloc[:,[0,1]].values)
sc_Y_stder = sc_Y.fit_transform(New_train.iloc[:,2].values.reshape(-1,1))
# 多项式化
poly_feat = PolynomialFeatures()
poly_feat_X = poly_feat.fit_transform(sc_X_stder)
# 训练
lr_model.fit(poly_feat_X,sc_Y_stder)
# 训练集测试
lr_model.score(poly_feat_X,sc_Y_stder) # 训练集上的R2:0.8914934227244807
# 测试集预测
sc_X_stder_test = sc_X.transform(New_test.iloc[:,[0,1]].values) # 归一化
poly_feat_X_test = poly_feat.transform(sc_X_stder_test) # 多项化
y_test_pred = lr_model.predict(poly_feat_X_test)
sc_Y_true = sc_Y.inverse_transform(y_test_pred) # 将预测结果反归一化
r2_score(y_test,sc_Y_true) # 测试集R2:0.641249665958082
好了,以上就是本次分享的所有内容了,如果大家有更好的想法或者建议可以多多评论和转发。
如果以上内容有涉及侵权请联系我删除:
邮箱:190514284@qq.com
qq:190514284
如有借鉴或者转载请加上文章链接:https://blog.csdn.net/Mr_Xuyunxin/article/details/118539052
本文github源码链接:https://github.com/cherishxyx/COVID-19_predict_model

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)