
解决多元线性回归的多重共线性问题
在上一章我们提到多重共线性的影响以及产生的原因,因为在解释变量存在多重共线性的情况下,使用普通最小二乘法估计参数会导致参数估计方差太大,使普通最小二乘法的效果很不理想。在这篇文章中我们将讨论如何解决多元线性回归中的多重共线性问题。一、岭回归(Ridge Regression)岭回归是一种专门用于共线性数据分析的有偏估计回归方法,是一种改良的最小二乘法。通过放弃最小二乘的无偏性,以损失部分信息、降低
在上一章我们提到多重共线性的影响以及产生的原因,因为在解释变量存在多重共线性的情况下,使用普通最小二乘法估计参数会导致参数估计方差太大,使普通最小二乘法的效果很不理想。在这篇文章中我们将讨论如何解决多元线性回归中的多重共线性问题。

一、岭回归(Ridge Regression)
岭回归是一种专门用于共线性数据分析的有偏估计回归方法,是一种改良的最小二乘法。通过放弃最小二乘的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际的回归方法。它可以缓解多重共线问题,以及过拟合问题。
当解释变量之间存在多重共线性时,矩阵
是一个非满秩矩阵,也即矩阵
(为什么非满秩方阵的行列式等于 0 呢?)。而由公式
可知,参数
无意义。为了解决这个问题,我们很自然地想到给矩阵
加上一个正数矩阵
,我们一般称该正数矩阵为扰动项。那么
接近奇异解的可能性较以前要小得多,于是参数
可以用
来进行估计。
在线性回归中,我们选用来选择训练模型。对于岭回归而言,我们采用在
的基础上加上对系数的惩罚,即

1.1 岭回归的定义
设,满足式子
的
称为
的岭估计。由
的岭估计建立的回归方程称为岭回归方程。其中
称为岭参数。对于回归系数
的分量
来说,在直角坐标系
的图像是
条曲线,称为岭迹。当
时,
即为原来的最小二乘估计。
1.2 岭估计的一些性质
- 岭估计不再是无偏估计,即
- 岭估计是压缩估计,即
,即有偏估计回归系数向量长度<无偏估计回归系数向量长度
1.3 岭参数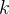 的选择
的选择
- 岭迹法:观察岭迹曲线,原则上取使得
稳定的最小的
- 均方误差法:岭估计的均方误差
是
,开始它下降,达到最小值后它开始上升,取它最小处的
1.4 岭迹图

岭迹图的横轴是岭参数,纵坐标是岭估计
。在
很小时,通常各
系数取值较大;而如果
,则跟普通意义的多元线性回归的最小二乘解完全一样;当
略有增大,则各
系数取值迅速减小,即从不稳定趋于稳定。 上图类似喇叭形状的岭迹图,一般都存在多重共线性。
根据岭迹图选择岭参数,选取喇叭口附近的值,此时各
值已趋于稳定,但总的
又不是很大。

根据岭迹图选择变量,删除那些β取值一直趋于0的变量。
但是根据岭迹图筛选变量不是十分靠谱。
二、岭回归的代码实现(Python)
咱们依旧以上篇学生计量经济学成绩分析的例子。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression as LM
import statsmodels.api as sm
from sklearn.linear_model import Ridge,RidgeCV
from scipy.stats import zscore
import sklearn.preprocessing as pp
data=pd.read_csv("eg2.1.csv")
data.head()
data=pp.scale(data) #对数据进行0-1标准化
data
X=data[:,1:]
Y=data[:,0]
K=np.arange(2,50) #设置岭参数
coefs=[]
for k in K:
ridge = Ridge(alpha=k, fit_intercept=False)
ridge.fit(X, Y)
coefs.append(ridge.coef_)
fig,axes=plt.subplots(figsize=(12,5))
axes.grid(True,linestyle='-.')
axes.plot(K,coefs)
plt.savefig("RidgeRegression.jpg")
plt.show()
mdcv=RidgeCV(alphas=np.logspace(-4,0,100)).fit(X,Y)
print("最优的alpha:\n",mdcv.alpha_)
md0=Ridge(mdcv.alpha_).fit(X,Y)
md0=Ridge(20).fit(X,Y)
cs0=md0.coef_
print("标准化数据的所有回归系数为:",cs0)
print("拟合优度:\n",md0.score(X,Y))

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)