[机器学习] XGB/LGB---自定义损失函数与评价函数
一 自定义评价函数Q: 评价函数为什么会影响模型训练?A: 评价函数会决定best_iteration、best_score在哪里取得最优解。XGBoost模型支持自定义评价函数和损失函数。只要保证损失函数二阶可导,通过评价函数的最大化既可以对模型参数进行求解。实际使用中,可以考虑根据业务目标对这两者进行调整。举个例子,假设现在有一个提额模型,用处是将分数最高的20%客户给与更高的额度。也就是期望
一 自定义评价函数
Q: 评价函数为什么会影响模型训练?
A: 评价函数会决定best_iteration、best_score在哪里取得最优解。
XGBoost模型支持自定义评价函数和损失函数。只要保证损失函数二阶可导,通过评价函数的最大化既可以对模型参数进行求解。实际使用中,可以考虑根据业务目标对这两者进行调整。
举个例子,假设现在有一个提额模型,用处是将分数最高的20%客户给与更高的额度。也就是期望分数最高的20%的客群正样本捕获率最大化。可能在保证上述前提,同时保证模型对正负样本有一定的区分能力。所以可以改写一个保证模型区分度,同时能优化局部正样本捕获率的评价函数 。
自定义XGBoost模型损失函数与评价函数
# 自定义对数损失函数
def loglikelood(preds, dtrain):
labels = dtrain.get_label()
preds = 1.0 / (1.0 + np.exp(-preds))
grad = preds - labels
hess = preds * (1.0-preds)
return grad, hess
# 评价函数:前20%正样本占比最大化
def binary_error(preds, train_data):
labels = train_data.get_label()
dct = pd.DataFrame({'pred':preds,'percent':preds,'labels':labels})
#取百分位点对应的阈值
key = dct['percent'].quantile(0.2)
#按照阈值处理成二分类任务
dct['percent']= dct['percent'].map(lambda x :1 if x <= key else 0)
#计算评价函数,权重默认0.5,可以根据情况调整
result = np.mean(dct[dct.percent== 1]['labels'] == 1)*0.5
+ np.mean((dct.labels - dct.pred)**2)*0.5
return 'error',result
watchlist = [(dtest,'eval'), (dtrain,'train')]
param = {'max_depth':3, 'eta':0.1, 'silent':1}
num_round = 100
# 自定义损失函数训练
bst = xgb.train(param, dtrain, num_round, watchlist, loglikelood, binary_error)可以看到评价函数由两部分组成,⭐️第一部分权重默认为0.5,目的是使得前20%样本中的正样本占比最大。因为正样本的标签为0,因此pandas.quantile()函数分位点参数0.2,表示预估为正样本概率最大的前20%分位点。⭐️第二部分权重同样默认设置为0.5,目的是让模型对正负样本的识别能力得到保障。
实际使用中,可以根据,对模型表现的侧重点,进行权重选择 。比如当更希望模型关注于捕获率时,可以调整第一部分权重为0.8,将第二部分权重调整为0.2。本文给出的是一种启发性的思路,读者还可以根据实际情况改写更贴合业务的损失函数。
⭐️LightGBM中也同样支持自定义损失函数和评价函数。代码上有一些细微差别。评价函数需要返回三部分,用False代替。
# 自定义二分类对数损失函数
def loglikelood(preds, train_data):
labels = train_data.get_label()
preds = 1. / (1. + np.exp(-preds))
grad = preds - labels
hess = preds * (1. - preds)
return grad, hess
# 自定义前20%正样本占比最大化的评价函数
def binary_error(preds, train_data):
labels = train_data.get_label()
dct = pd.DataFrame({'pred':preds,'percent':preds,'labels':labels})
#取百分位点对应的阈值
key = dct['percent'].quantile(0.2)
#按照阈值处理成二分类任务
dct['percent']= dct['percent'].map(lambda x :1 if x <= key else 0)
#计算评价函数,权重默认0.5,可以根据情况调整
result = np.mean(dct[dct.percent== 1]['labels'] == 1)*0.9 + np.mean((dct.labels - dct.pred)**2)*0.5
return 'error',result, False
gbm = lgb.train(params,
lgb_train,
num_boost_round=100,
init_model=gbm,
fobj=loglikelood,
feval=binary_error,
valid_sets=lgb_eval)反欺诈自定义评估函数
评估指标有2:1是 ks, 2是头部 lift。 KS 反映整体排序能力,头部 lift 反映分段排序性。之前反欺诈模型迭代时主要更新训练时间窗口,模型方法上改变很小。由于反欺诈模型实际应用于砍刀,即按照某一分数 cutoff。反欺诈模型目标其实是提升头部抓坏率,不关心整体排序。所以在想是否可以改变模型训练目标,让模型训练时不用追求全局排序最优,只需要头部最优。尝试了改变 xgb 训练的评估函数和损失函数,有一点效果。
# 自定义对数损失函数
def loglikelood(preds, dtrain):
labels = dtrain.get_label()
preds = 1.0 / (1.0 + np.exp(-preds))
grad = preds - labels
hess = preds * (1.0-preds)
return grad, hess
# 评价函数
watchlist = [(dtest,'eval'), (dtrain,'train')]
param = {'max_depth':3, 'eta':0.1, 'silent':1}
num_round = 100
# 自定义损失函数训练
bst = xgb.train(params=params, dtrain=dtrain, num_boost_round=900, evals=watchlist, early_stoppingrounds=30,obj=loglikelood, feval=mse_top)自定义损失函数是交叉熵,评估函数 mse_top 包含两个部分mse和 gap, mse 只计算头部10%的 均方误差,gap 是头部的平均分与剩下部分平均分的比值,mse * gap 目的是让头部误差小,同时尽量让坏人排到头部。
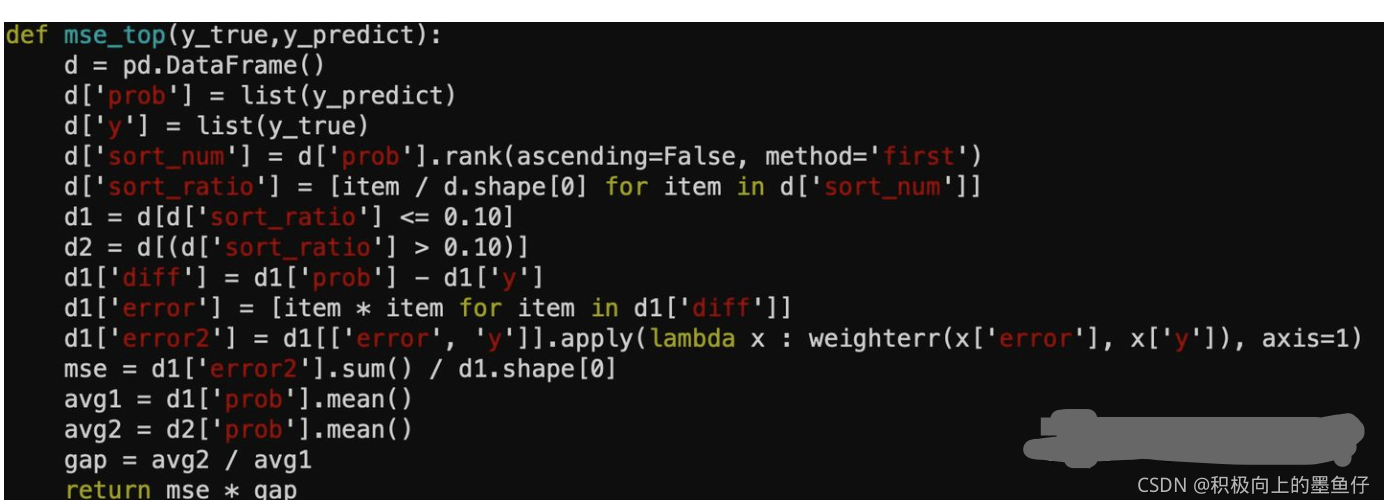
来源:反欺诈自定义损失函数和评估函数 - 知乎 (zhihu.com)
二 自定义损失函数
XGBoost损失函数的预备知识
- 损失函数:损失函数描述了预测值和真实标签的差异,通过对损失函数的优化来获得对学习任务的一个近似求解方法
- boosting类算法的损失函数的作用: Boosting的框架, 无论是GBDT还是Adaboost, 其在每一轮迭代中, 根本没有理会损失函数具体是什么, 仅仅用到了损失函数的一阶导数通过随机梯度下降来参数更新
- 二阶导数:GBDT在模型训练时只使用了代价函数的一阶导数信息,XGBoost对代价函数进行二阶泰勒展开,可以同时使用一阶和二阶导数
- 牛顿法梯度更新:XGBoost是用了牛顿法进行的梯度更新。通过对损失进行分解得到一阶导数和二阶导数并通过牛顿法来迭代更新梯度。
基于XGBoost的损失函数的分解求导,可以知道XGBoost的除正则项以外的核心影响因子是损失函数的1阶导和2阶导,所以对于任意的学习任务的损失函数,可以对其求一阶导数和二阶导数带入到XGBoost的自定义损失函数范式里面进行处理。
def custom_obj(pred, dtrain):#pred 和dtrain 的顺序不能弄反
# STEP1 获得label
label = dtrain.get_label()
# STEP2 如果是二分类任务,需要让预测值通过sigmoid函数获得0~1之间的预测值
# 如果是回归任务则下述任务不需要通过sigmoid
#分类任务sigmoid化
def sigmoid(x):
return 1/(1+np.exp(-x))
sigmoid_pred = sigmoid(-原始预测值)
#回归任务
pred = 原始预测值
# STEP3 一阶导和二阶导
grad = 一阶导
hess = 二阶导
return grad, hess常见的损失函数
分类问题
非平衡分类学习任务,例如首笔首期30+的风险建模任务,首期30+的逾期率比例相对ever30+的逾期率为1/3左右,通过修正占比少的正样本权重来对影响正样本对损失函数的贡献度,可以进一步提升模型的
- 加权损失函数
def weighted_binary_cross_entropy(pred, dtrain,imbalance_alpha=10):
# retrieve data from dtrain matrix
label = dtrain.get_label()
# compute the prediction with sigmoid
sigmoid_pred = 1.0 / (1.0 + np.exp(-pred))
# gradient
grad = -(imbalance_alpha ** label) * (label - sigmoid_pred)
hess = (imbalance_alpha ** label) * sigmoid_pred * (1.0 - sigmoid_pred)
return grad, hess - Focal loss
#focal 损失
# LGB+Focal Loss 其中alpha:为不能让容易分类类别的损失函数太小, 默认值0.25;
#gamma:更加关注困难样本 即关注y=1的样本 默认值2
from scipy.misc import derivative
def focal_loss_lgb_sk( y_pred,dtrain, alpha=0.25, gamma=2):
label = dtrain.get_label()
a,g = alpha, gamma
def fl(x,t):
p = 1/(1+np.exp(-x))
return -( a*t + (1-a)*(1-t) ) * (( 1 - ( t*p + (1-t)*(1-p)) )**g) * ( t*np.log(p)+(1-t)*np.log(1-p) )
partial_fl = lambda x: fl(x, label)
grad = derivative(partial_fl, y_pred, n=1, dx=1e-6)
hess = derivative(partial_fl, y_pred, n=2, dx=1e-6)
return grad, hess回归问题
应用场景
美团的ETA预估
通过对损失函数进行修正大幅度提高了业务预测效果(使得结果倾向于提前到达)
1.带惩罚的最小二乘损失函数
def custom_normal_train( y_pred,dtrain):
label = dtrain.get_label()
residual = (label - y_pred).astype("float")
grad = np.where(residual<0, -2*(residual)/(label+1), -10*2*(residual)/(label+1))#对预估里程低于实际里程的情况加大惩罚
hess = np.where(residual<0, 2/(label+1), 10*2/(label+1))#对预估里程低于实际里程的情况加大惩罚
return grad, hesshttps://www.kaggle.com/c/allstate-claims-severity/discussion/24520#140255
kaggle 的保险定价竞赛中评价函数为MAE(存在不可导区域),通过使用下述的损失函数来获得MAE的近似损失函数来求解该问题
1.fair loss
def fair_obj( preds,dtrain):
labels = dtrain.get_label()
con = 2
residual = preds-labels
grad = con*residual / (abs(residual)+con)
hess = con**2 / (abs(residual)+con)**2
return grad,hess
https://www.kaggle.com/c/allstate-claims-severity/discussion/24520#140255 提供了非常高质量的近似MAE损失函数优化的讨论
2.mae的近似损失函数- Pseudo Huber loss
def huber_approx_obj( preds,dtrain):
d = preds -dtrain.get_label()
h = 1 #h is delta in the formula
scale = 1 + (d / h) ** 2
scale_sqrt = np.sqrt(scale)
grad = d / scale_sqrt
hess = 1 / scale / scale_sqrt
return grad, hess 3.mae的近似损失函数 ln(cosh) loss
def logcoshobj( preds,dtrain):
label = dtrain.get_label()
d = preds - label
grad = np.tanh(d)/label
hess = (1.0 - grad*grad)/label
return grad, hess
XGBoost损失函数优化 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/278060736
https://zhuanlan.zhihu.com/p/278060736
风控模型有2个基本问题:
1)模型用历史数据训练预测未来样本表现。这里有个假设是未来样本分布和历史基本相似。但这个假设可能是不成立的,特别是对非银机构,模型策略迭代比较频繁时,从申请到授信到用信漏斗下来的人群各月已经发生了改变,另外宏观环境也可能改变申请人群。所以如何选择与未来样本最相似的样本训练是一个基本问题。
2)风控模型特别是 A 卡一般在固定时间点打分(比如授信时),但预测评估则是全生命周期的。既模型上线后,既要看短周期表现也要看长周期表现。而模型训练的 label则是固定一个时间点,比如 dpd30+ @mob12。所以会看到当 label对应观察时间窗口较短训练模型时(比如 dpd30+@mob2),短期的模型排序能力略强长期较弱,若 label 对应时间窗口较长(dpd30+@mob12)时长周期表现略好,短期可能比较弱。如何训练一个模型能对未来全生命周期都有较好排序能力是另一个基本问题。
自定义损失函数--提升模型全周期排序能力
无论是用逻辑回归还是树模型训练,都是将目标看成一个分类问题(是否逾期)。模型损失函数为交叉熵,如下式:
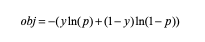
从交叉熵的公式可以看出模型训练迭代时,是将正样本预测概率逼近1,负样本逼近0。但同样是1的正样本之间是没有区分的。早期坏的人理论上分数理想情况下应该比晚期坏的人更高。如果目标函数能体现不同周期(mob)坏的人的分数高低,那岂不是完美解决问题了。所以尝试在目标函数加上另外一项损失,即排序损失。损失函数定义如下
![]()
第一项就是交叉熵,第二项是ranking 损失。ranking 损失定义是: 把好人,不同周期的坏人(mob2, mob3....)分组,然后理想情况下各组分数从高到低排序应该是:...mob12坏人,mob11坏人...mob3坏人,mob2坏人,好人,ranking 损失就是以上各组乱序的损失,同一组不比较。好的,到这里已经比较好的把业务问题转化为数学问题了,现在要做的是定义 Ranking 损失。Learning to ranking 是一个比较成熟的领域,常用于搜索排序。比较常用的方法有 pointwise, pairwise, listwise 等。贴上知乎上Ranking 的基本介绍:
我们尝试了用poitwise 和 pairwise 两种方式来计算 ranking 损失,pointwise 用的损失函数NDCG定义如下,j 对应各个坏的周期。
![]()
叠加 ndcg 的 自定义函数代码如下。
def logloss_ndcg(preds, train_data):
alpha = 0.5
beta = 10
mobs = train_data.get_label()
# preds = 1. / (1. + np.exp(-preds))
labels = [1 if int(item) != 13 else 0 for item in list(mobs)]
grad_rank = np.exp(preds) * preds * (1. - preds) / np.log(1 + mobs * beta)
hess_rank = (np.exp(preds) * preds ** 2 * (1. - preds) ** 2 + np.exp(preds) * preds * (1. - preds) ** 2 - np.exp(
preds) * preds ** 2 * (1. - preds)) / np.log(1 + mobs * beta)
grad = (1 - alpha) * (preds - labels) + alpha * grad_rank
hess = (1 - alpha) * (preds * (1 - preds)) + alpha * hess_rank
return grad, hessmobs = train_data.get_label()拿到的是各样本坏的周期[13,13,2,3..12],13表示好人。y2将 labels 转为0,1。grad_rank, hess_rank是 ndcg 推导的一阶导数和二阶导数。最后返回的为交叉熵叠加 ndcg 损失。
此处提醒一下:xgb1.1之后 obj 接口传过来的preds是 sigmoid 之前的,而0.9是sigmoid 之后的。使用低版本 xgb 时preds = 1. / (1. + np.exp(-preds))要注掉。
pairwise 稍微复杂点,对应的损失函数为 max(0, y1-y2),即如果y1和y2不逆序则损失为0,逆序为 y1-y2。函数的一阶导数g和二阶导数 h 如下。
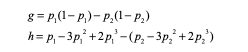
理论上需要将各个样本两两配对计算逆序损失,暴力配对方法时间复杂度为 O(n2),速度太慢。我们做了优化:首先把每个分组的一阶导和二阶导先求和并存好。然后单样本y1和其他组的样本y2比较时只有两种情况:样本y1 mob 比y2 mob 低,则损失为 y1-y2。如果高则 y2-y1;所以单样本 g如下:
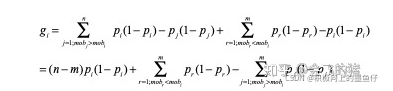
上式中gi分解为三个部分:(n-m)×自身 g, +比自己 mob 高的样本 g求和,-比自己 mob 低的样本 g求和。第二项和第三项以及 n,m都可以先算好并保存,后面遍历所有样本拿过来直接用。时间复杂度降低为 O(n)。代码如下
def obj3(predt, dtrain):
l1 = alpha
l2 = beta
y_true = list(dtrain.get_label())
y_01 = [0 if item ==0 else 1 for item in y_true]
infodic_c= {}
infodic_g= {}
infodic_h= {}
predt_label = [item for item in zip(predt, y_true)]
for p,y in predt_label:
if y > 0:
y2 = 1
else:
y2 = 0
y = 999
g = p * (1 - p)
h = p - 3 * p * p + 2 * p * p * p
if not y in infodic_c:
infodic_c[y] = 1
infodic_g[y] = g
infodic_h[y] = h
else:
infodic_c[y] += 1
infodic_g[y] += g
infodic_h[y] += h
gra = []
hra = []
for p,y in predt_label:
sumg = 0.0
sumh = 0.0
count = 0.0
for mob in infodic_c:
if y == 0:
y == 999
y2 = 0
else:
y2 = 1
if y < mob:
count += infodic_c[mob]
sumg += infodic_c[mob] * p * (1 - p) - infodic_g[mob]
sumh += infodic_c[mob] * (p - 3 * p * p + 2 * p * p * p) - infodic_h[mob]
elif y > mob:
count += infodic_c[mob]
sumg += -infodic_c[mob] * p * (1 - p) + infodic_g[mob]
sumh += -infodic_c[mob] * (p - 3 * p * p + 2 * p * p * p) + infodic_h[mob]
sumg = sumg / (count + 0.0001)
sumh = sumh / (count + 0.0001)
gra.append(-sumg)
hra.append(-sumh)
g = alpha * np.asarray(gra) + beta * (predt - y_01)
h = alpha * np.asarray(hra) + beta * predt * (1 - predt)
return g, h因为传入的 y_true 是周期 mob 作为 label,所以评估函数的 auc 稍作修改,代码如下
def custom_feval(y_prob, train):
mobs = list(train.get_label())
y_true = [1 if int(item) != 13 else 0 for item in mobs]
y_prob = list(y_prob)
return 'feval', roc_auc_score(y_true, y_prob) 使用自定义损失函数后,我们在不同场景的模型上收益各有不同,有的有明显增益,有的基本没啥变化,取决于场景和数据。这里不做延伸解释,只是一种方法学的介绍。
提升训练样本与预测样本分布相似度
1.对抗样本,基本思想步骤如下:
1)把历史样本和预测样本作为负样本和正样本,构造一个分类模型预测样本是训练集或预测集的概率。概率越高,则说明和预测集越相似。
2)有了样本概率,接下来两种做法:1)把概率作为样本权重代入模型训练; 2)选择 top n%的样本训练模型。
某些场景下此方法比较有效。知乎上关于对抗样本的链接如下
某些场景下此方法比较有效。知乎上关于对抗样本的链接如下
刘秋言:还在用交叉验证?试试Kaggle大牛们常用的方法——对抗验证88 赞同 · 7 评论文章正在上传…重新上传取消https://zhuanlan.zhihu.com/p/93842847

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)