python数据分析之pandas设置索引
1.索引的作用索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。更方便地查询数据使用索引可以提升查询性能多维索引用于多维聚类重设索引有一个很重要的方法reindex,它的作用是创建一个适应新索引的对象。语法如下:DataFrame.reindex(labels=None,index=None,column=None,axis=None,method=None,copy=True,
·
1.索引的作用
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
- 更方便地查询数据
- 使用索引可以提升查询性能
- 多维索引用于多维聚类
重设索引有一个很重要的方法reindex,它的作用是创建一个适应新索引的对象。语法如下:
DataFrame.reindex(labels=None,index=None,column=None,axis=None,method=None,copy=True,level=None,fill_value=nan,limit=None,tolerance=None)
"""
label:标签,可以是数组
index:行索引,默认值为None
columns:列索引,默认值为None
axis:轴,0表示行;1表示列
method:默认值为None,重新设置索引,,选择填充缺失数据的方法,其值可以是None,bfill/backfill(后向填充)、fill/pad(前向填充)
fill_value:缺失值要填充的数据,如果缺失值不用NaN填充,可用fill_value=0,用0填充。
"""
import pandas as pd
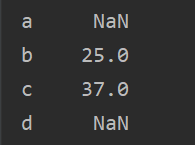
s1=pd.Series([15,23,34],index=list("abc"))
s2=pd.Series([2,3,4],index=list("bcd"))
print(s1+s2)#根据索引相加
#索引相同相加,不相同的为NaN
2.重新设置索引
2.1 Series对象重新设置索引
#重新设置索引
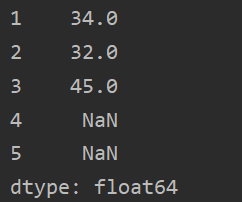
s3=pd.Series([34,32,45],index=[1,2,3])
print(s3.reindex([1,2,3,4,5]))
print(s3.reindex([1,2,3,4,5],fill_value=0))#空缺值用0填充
print(s3.reindex([1,2,3,4,5],method="ffill"))#向前填充(填充的数据和前面数据一样)
print(s3.reindex([1,2,3,4,5],method="bfill"))#向后填充(填充的数据和后面数据一样)
实验数据如下:
0填充:

向前填充:

向后填充:(因为后面没有数据,也是NaN)
2.2 Dataframe对象重新设置索引
#对Dataframe对象重新设置索引
pd.set_option("display.unicode.east_asian_width",True)
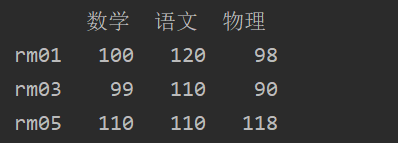
data=[[100,120,98],[99,110,90],[110,110,118]]
indexs=["rm01","rm03","rm05"]
columns=["数学","语文","物理"]
df=pd.DataFrame(data,index=indexs,columns=columns)
print(df)
数据如下所示:
设置行列索引
df.reindex(["rm01","rm02","rm03","rm04","rm05"])#重新设置行索引
df.reindex(columns=["英语","政治","历史"])#重新设置列索引
#同时重新设置行列索引
df.reindex(index=["001","002","003","004","005"],columns=["英语","政治","历史"])
3. 设置某列为索引
属性set_index为重新建立索引,方法中的drop=True,则会删除该列,只将改列作为索引列,drop=False,则会保留索引列,并保留该索引列数据。
df=pd.read_excel(r"C:\Users\Administrator\Desktop\python数据分析Code\Code\03\44\1月.xlsx")
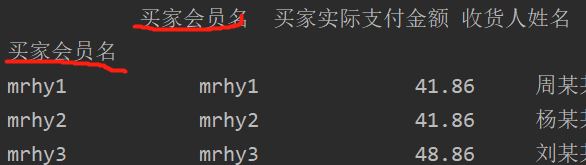
#将买家会员设置为索引,
df=df.set_index(["买家会员名"],drop=False)
这是drop=False的情况
这是drop=True的情况

4. #删除缺失值之后重新设置索引
将含有空数据的行删除,并添加新的索引。
df=df.dropna().reset_index(drop=True)
结果如下:


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)