
李宏毅ML作业笔记3: 食物分类(kaggle预测与报告题目)
任务介绍数据格式要求代码思路读取图片数据增强 及 Dataset类定义数据增强Dataset类分类模型训练训练集训练训练/验证集共同训练测试报告题目1. 模型描述2. 深度减半3. 转为DNN4. 模型比较结论
kaggle中的任务发布在: https://www.kaggle.com/c/ml2020spring-hw3
本文代码在kaggle公开: https://www.kaggle.com/laugoon/hw3-food-image-classify
查看kaggle不方便的同学也可以在CSDN下载:
https://download.csdn.net/download/lagoon_lala/20213190
目录
任务介绍
食物分类


食物照片共有11類
Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, and Vegetable/Fruit.
Training set: 9866張
Validation set: 3430張
Testing set: 3347張
数据格式
training 以及 validation 中的照片名稱格式為 [類別]_[編號].jpg如 3_100.jpg 即為類別 3 的照片(編號不重要)
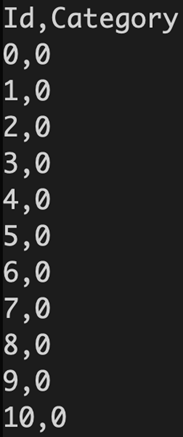
testing 中的照片名稱格式為 [編號].jpg,上傳 Kaggle 的 csv 檔預測值需依照照片編號排列。
testing set预测格式:
评价指标(Evaluation Metric)精度Accuracy
要求
請使用 CNN 實作 model
不能使用額外 dataset
禁止使用 pre-trained model(只能自己手刻CNN)
請不要上網尋找 label
代码思路
kaggle网址:
https://www.kaggle.com/c/ml2020spring-hw3
默认代码读取数据集得:
| /kaggle/input/ml2020spring-hw3/food-11/validation/8_8.jpg /kaggle/input/ml2020spring-hw3/food-11/training/10_170.jpg /kaggle/input/ml2020spring-hw3/food-11/testing/0664.jpg |
所需套件有:
| import os # import numpy as np import cv2 import torch import torch.nn as nn import torchvision.transforms as transforms # import pandas as pd from torch.utils.data import DataLoader, Dataset import time |
读取图片
利用 OpenCV (cv2) 讀入照片並存放在 numpy array 中
定义文件读取函数readfile(path, label)
输入参数path为文件夹如: /kaggle/input/ml2020spring-hw3/food-11/validation
输入参数label为boolean变量,代表是否返回 y 值
输出参数x为文件夹中图片列表. 图片形状为128*128, 彩色图片RGB, 所以有3层
输出参数y为图片类别
| for i, file in enumerate(image_dir):#遍历文件列表中文件名 img = cv2.imread(os.path.join(path, file))#cv2读入原图片 x[i, :, :] = cv2.resize(img,(128, 128))#对图片进行缩放, 存储到x的第i个中 if label: y[i] = int(file.split("_")[0])#取出文件名中的类别信息 |
相关知识:
os.listdir()返回文件夹包含的文件或文件夹的名字的列表
sort是list的方法,对已存在列表进行操作.
sorted内建函数, 可以对所有可迭代的对象进行排序操作, 返回新的 list.
resize图片缩放
读取训练, 测试, 验证集
| train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True) print("Size of training data = {}".format(len(train_x))) |
数据增强 及 Dataset类定义
数据增强
| # 训练时做数据增强(data augmentation) train_transform = transforms.Compose([ transforms.ToPILImage(), transforms.RandomHorizontalFlip(), # 随机将图片水平翻转 transforms.RandomRotation(15), # 随机选择图片 transforms.ToTensor(), # 图片转化为张量Tensor,並把數值 normalize 到 [0,1] (data normalization) ]) # 测试时不需做数据增强 test_transform = transforms.Compose([ transforms.ToPILImage(), transforms.ToTensor(), ]) |
相关知识:
torchvision.transforms图片变换,例如裁剪、旋转等;
torchvision.transforms.Compose()类: 主要作用是串联多个图片变换的操作. 会将transforms列表里面的transform操作进行遍历.
处理三种数据tensor,numpy,PIL转换过程需要注意类型.
| # 将tensor转换为numpy x_numpy = x_tensor.numpy() #维度也不改变(1, 128, 228) |
| # numpy to PIL x_pil = T.ToPILImage()(np.uint8(x)) #注意这里的np.uint8(),为了使其满足类型需求,在这里是必须的 |
| # tensor to PIL x = x.float() # 有时候从numpy到tensor后再转化为PIL会报错,这一步就是使其满足数据类型 x_pil = T.ToPILImage()(x) |
ToPILImage实际上将CHW变成了WH,也去掉了通道这个维度.
(pytorch中tensor默认是CHW; PIL是HWC)
PyTorch 中torch.utils.data 的 Dataset 及 DataLoader, 方便训练, 测试.
Dataset类
Dataset需要自定义一个类来继承Dataset,然后实现__getitem__()方法和__len__()方法.
(重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。重写是子类根据需要实现父类的方法。)
__len__ 返回dataset的大小;
__getitem__ 定义用[ ]取值時,dataset如何返回.
使用 DataLoader 在遍历Dataset 時會使用到
| class ImgDataset(Dataset): #初始化中把所有传入内容赋给属性 def __init__(self, x, y=None, transform=None):#如果没有传入y, transform, 则默认值为0 self.x = x # label类型应为 LongTensor self.y = y if y is not None: self.y = torch.LongTensor(y) self.transform = transform # 返回dataset的大小 def __len__(self): return len(self.x) # 用[ ]取值時,dataset如何返回. 返回前先对x进行转换 def __getitem__(self, index): X = self.x[index] if self.transform is not None: X = self.transform(X) if self.y is not None: Y = self.y[index] return X, Y else: return X |
实例化一个dataset,然后用Dataloader 包起来
| batch_size = 128 train_set = ImgDataset(train_x, train_y, train_transform) val_set = ImgDataset(val_x, val_y, test_transform) train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True) val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False) |
分类模型
先CNN, 展平(view)后, 全连接FC.
| class Classifier(nn.Module): def __init__(self): super(Classifier, self).__init__() # torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding) # torch.nn.MaxPool2d(kernel_size, stride, padding) # input 維度 [3, 128, 128] #cnn网络 self.cnn = nn.Sequential( nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128] nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(2, 2, 0), # [64, 64, 64] nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64] nn.BatchNorm2d(128), nn.ReLU(), nn.MaxPool2d(2, 2, 0), # [128, 32, 32] nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32] nn.BatchNorm2d(256), nn.ReLU(), nn.MaxPool2d(2, 2, 0), # [256, 16, 16] nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16] nn.BatchNorm2d(512), nn.ReLU(), nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8] nn.BatchNorm2d(512), nn.ReLU(), nn.MaxPool2d(2, 2, 0), # [512, 4, 4] ) #全连接分类器 self.fc = nn.Sequential( nn.Linear(512*4*4, 1024), nn.ReLU(), nn.Linear(1024, 512), nn.ReLU(), nn.Linear(512, 11) ) def forward(self, x): out = self.cnn(x) out = out.view(out.size()[0], -1) return self.fc(out) |
相关知识:
BatchNorm2d
在卷积神经网络的卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
一般输入参数为batch_size*num_features*height*width,即为其中特征的数量,channel数。
nn.Linear(in_features , out_features)
out.view(out.size()[0], -1)
view为了将前面操作输出的多维度的tensor展平成一维,然后输入分类器,-1是自适应分配,指在不知道函数有多少列的情况下,根据原tensor数据自动分配列数。
作用类似于keras中的Flatten函数。只不过keras中是和卷积一起写的,而pytorch是在forward中才声明的。
训练
使用 training set 訓練,並使用 validation set 尋找好的參數
训练集训练
CUDA(Compute Unified Device Architecture),并行计算架构,使GPU能够解决复杂的计算问题.
pytorch中的gpu加速运算可参考:
https://mofanpy.com/tutorials/machine-learning/torch/GPU/
| model = Classifier().cuda()#操作放在GPU loss = nn.CrossEntropyLoss() # 分类任务的loss 使用 CrossEntropyLoss optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # optimizer 使用 Adam num_epoch = 30 for epoch in range(num_epoch): epoch_start_time = time.time() train_acc = 0.0#训练 train_loss = 0.0 val_acc = 0.0#验证 val_loss = 0.0 model.train() # 在训练时启用batch normalization和drop out(测试时操作不同) for i, data in enumerate(train_loader): optimizer.zero_grad() # 用 optimizer 將 model 參數的 gradient 歸零 train_pred = model(data[0].cuda()) # 利用 model 得到預測的機率分佈 這邊實際上就是去呼叫 model 的 forward 函數 batch_loss = loss(train_pred, data[1].cuda()) # 計算 loss (注意 prediction 跟 label 必須同時在 CPU 或是 GPU 上) batch_loss.backward() # 利用 back propagation 算出每個參數的 gradient optimizer.step() # 以 optimizer 用 gradient 更新參數值 train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())#获取预测 Variable 的内部 Tensor, 转换成numpy类型. 获取第二个维度中最大值(即可能性最大)索引,与真实值对比. train_loss += batch_loss.item()#张量转值
model.eval()# 在测试时不用batch normalization和drop out with torch.no_grad():#内部不会track 梯度 for i, data in enumerate(val_loader):#val_loader之前与train_loader一起获得 val_pred = model(data[0].cuda()) batch_loss = loss(val_pred, data[1].cuda()) val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy()) val_loss += batch_loss.item() #將結果 print 出來 print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \ (epoch + 1, num_epoch, time.time()-epoch_start_time, \ train_acc/train_set.__len__(), train_loss/train_set.__len__(), val_acc/val_set.__len__(), val_loss/val_set.__len__())) |
相关知识:
model.train()
pytorch构建神经网络的时候,训练过程中会在程序上方添加一句model.train(),作用是启用batch normalization和drop out。
model.eval()
不启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。保证BN层能够用全部训练数据的均值和方差。Dropout用到所有网络连接,不进行随机舍弃神经元。
pytorch.data
tensor.data和tensor.detach(),语义是获取 Variable 的内部 Tensor,但是都不进行梯度计算和梯度跟踪,即requires_grad=False. 两者都和原数据共享同一块数据;都和原来数据的计算历史无关.
detach会进行提示,相比data更安全,在使用in-place操作后,会修改原数据的值,而如果在反向传播过程中使用到原数据会导致计算错误,而使用.detach就会报错.
numpy.argmax(array, axis)
返回一个numpy数组中最大值的索引值
x.item()
只含一个元素的张量可以用x.item()得到元素值
torch.no_grad()
一个上下文管理器,被该语句 wrap 起来的部分将不会track 梯度
如果报错:
| Torch not compiled with CUDA enabled |
参考:
https://www.kaggle.com/c/quora-insincere-questions-classification/discussion/77886
在设置中开启加速, 将会提示
Accelerator
turn on GPU will reduce the number of CPUs available and will only speed up image processing and neural networks.
Availability is limited to 30 hours per week.
然后就可以用了
训练集/验证集的精度与损失
| [001/030] 23.37 sec(s) Train Acc: 0.250862 Loss: 0.017631 | Val Acc: 0.295918 loss: 0.015972 |
| [030/030] 22.20 sec(s) Train Acc: 0.875329 Loss: 0.002861 | Val Acc: 0.624781 loss: 0.011972 |
训练/验证集共同训练
得到好的參數後,使用 training set 和 validation set 共同訓練(資料量變多,模型效果較好)
数据集处理:
| train_val_x = np.concatenate((train_x, val_x), axis=0)#两个数组拼接 train_val_y = np.concatenate((train_y, val_y), axis=0) train_val_set = ImgDataset(train_val_x, train_val_y, train_transform) train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True) #train_val_set为实例化的1个dataset,然后用Dataloader 包起来 |
相关知识:
np.concatenate
数组拼接
DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
参考: https://blog.csdn.net/zw__chen/article/details/82806900
手动加载数据的方式,在数据量小的时候,并没有太大问题,但是到了大数据量,需要使用 shuffle, 分割成mini-batch 等操作的时候,可使用PyTorch的API快速地完成.
Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。
DataLoader是一个比较重要的类,它为我们提供的常用操作有
batch_size(每个batch的大小), shuffle(是否进行shuffle操作), num_workers(加载数据的时候使用几个子进程)
继承 Dataset类(重写 len 方法; getitem 方法),即将数据处理成DataLoader的类
- dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
- 使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
- 也可以使用`for inputs, labels in dataloaders`进行可迭代对象的访问;
- 一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据;
训练
方法类似, 但这次只训练不验证, 只model.train()不用eval()
训练集+验证集共同的精度与损失:
| [001/030] 26.46 sec(s) Train Acc: 0.242103 Loss: 0.017428 |
| [030/030] 26.52 sec(s) Train Acc: 0.907040 Loss: 0.002050 |
测试
数据集, 实例化一个dataset,然后用Dataloader 包起来
| test_set = ImgDataset(test_x, transform=test_transform) test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False) |
利用训练出的 model 在测试模式下预测
| model_best.eval() prediction = [] with torch.no_grad(): for i, data in enumerate(test_loader): test_pred = model_best(data.cuda()) test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1) for y in test_label: prediction.append(y) |
保存结果:
| #將結果寫入 csv 檔 with open("predict.csv", 'w') as f: f.write('Id,Category\n') for i, y in enumerate(prediction): f.write('{},{}\n'.format(i, y)) |
报告题目
1. 模型描述
請說明你實作的 CNN 模型,其模型架構、訓練參數量和準確率為何?(1%)
(单用训练集数据训练的模型: 训练集准确率0.875, 验证集集准确率0.624. 用训练集验证集数据一起训练得训练集准确率: 0.907, 但测试集得分0.14635. 相反, 在训练集和验证集结果都很糟糕0.285的DNN模型, 却在测试集得到更高分0.231. 因为相同的代码20年的同学得分0.7+, 21年的同学出现类似得分0.08+的情况, 考虑是测试集数据或评分标准发生了变动. 看验证集好了) 验证集准确率0.624.
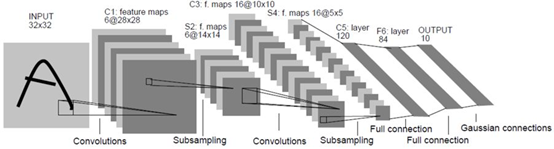
模型架构如下图

架构参考了LeNet, 1998:
参数数量参考:
https://www.zhihu.com/question/65305385
https://zhuanlan.zhihu.com/p/366184485
通常用Forward Pass计算量和参数个数(Parameters)来描述复杂度
前者描述了所需的计算力, 后者描述了所需内存.
由于使用了Batch Normalization, 则卷积层的参数量计算公式为:
$$ params=C_o\times k^2\times C_i $$
C_o: 卷积核个数=输出通道数
C_i: 输入通道数
k: 卷积核宽高
k^2*C_i表示一个卷积核的权重数量
全连接层参数量
$$ params=(I+1)\times O=I\times O+O $$
I=input neuron numbers, O=output neuron numbers.
feature map flatten而来的向量视为第一层全连接层,即此处的I.
理解1:每一个输出神经元连接着所有输入神经元,所以有I个权重,每个输出神经元还要加一个bias。
理解2:每一层神经元(O这一层)的权重数为I×O,bias数量为O。
| 网络层 | 输入 | filter | stride | padding | 输出 | 计算式 | 参数量 |
| Conv Layer1 | 3*(128*128) | 64*(3*3) | 1 | 1 | 64*(128*128) | 64*(3*3*3) | 1728 |
| Conv Layer2 | 64*(64*64) | 128*(3*3) | 1 | 1 | 128*(64*64) | 128*(3*3*64) | 73728 |
| Conv Layer3 | 128*(32*32) | 256*(3*3) | 1 | 1 | 256*(32*32) | 256*(3*3*128) | 294912 |
| Conv Layer4 | 256*(16*16) | 512*(3*3) | 1 | 1 | 512*(16*16) | 512*(3*3*256) | 1179648 |
| Conv Layer5 | 512*(8*8) | 512*(3*3) | 1 | 1 | 512*(8*8) | 512*(3*3*512) | 2359296 |
| FC1 | 512*4*4 | 1024 | (8192+1)*1024 | 8389632 | |||
| FC2 | 1024 | 512 | (1024+1)*512 | 524800 | |||
| FC3 | 512 | 11 | (512+1)*11 | 5643 |
参数总量: 12829387
也可以直接用代码获得参数量:
| def params_count(model): """ Compute the number of parameters. Args: model (model): model to count the number of parameters. """ return np.sum([p.numel() for p in model.parameters()]).item() |
| model = Classifier() print('params num:', params_count(model)) |
2. 深度减半
請實作與第一題接近的參數量,但 CNN 深度(CNN 層數)減半的模型,並說明其模型架構、訓練參數量和準確率為何?(1%)
参考:
https://mrsuncodes.github.io/2020/03/28/%E6%9D%8E%E5%AE%8F%E6%AF%85%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0-%E7%AC%AC%E4%B8%89%E8%AF%BE%E4%BD%9C%E4%B8%9A/#more
只需要替换定义模型Classifier那一步的代码.
CNN的卷积层原本层数为5,深度减半即2~3层. 参数量有关的是输入层数, 输出层数, 卷积核形状. 尽量保持整个卷积的输入(3@128*128)输出(512@4*4)形状不变.
通道数越多, 参数量越大, 影响越大
即输入3层经过3次卷积操作的卷积核变为512层; (3-64)-(64-256)-(256-512)
输入128*128的宽高经过3次池化变为4*4的宽高.(128-128/2=64)-(64-64/4=16)-(16-16/4=4)
模型架构如下图:

训练参数量:
| 网络层 | 输入 | filter | stride | padding | 输出 | 计算式 | 参数量 |
| Conv Layer1 | 3*(128*128) | 128*(3*3) | 1 | 1 | 128*(128*128) | 128*(3*3*3) | 3456 |
| Conv Layer2 | 128*(64*64) | 256*(3*3) | 1 | 1 | 256*(64*64) | 256*(3*3*128) | 294912 |
| Conv Layer3 | 256*(16*16) | 512*(3*3) | 1 | 1 | 512*(16*16) | 512*(3*3*256) | 1179648 |
| FC1 | 512*4*4 | 1024 | (8192+1)*1024 | 8389632 | |||
| FC2 | 1024 | 512 | (1024+1)*512 | 524800 | |||
| FC3 | 512 | 11 | (512+1)*11 | 5643 |
手算参数总量: 10398091 (比5层CNN少了2,431,296)
代码得参数量: 10400779
30次时得正确率:
| [030/050] 30.78 sec(s) Train Acc: 0.822927 Loss: 0.004031 | Val Acc: 0.596793 loss: 0.013568 |
50次时得正确率:
| [050/050] 30.84 sec(s) Train Acc: 0.936043 Loss: 0.001405 | Val Acc: 0.657726 loss: 0.013707 |
对比可得, 正确率有轻微下降, 但影响不是很大.
3. 转为DNN
請實作與第一題接近的參數量,簡單的 DNN 模型,同時也說明其模型架構、訓練參數和準確率為何?(1%)
模型架构:

训练参数量:
输入神经元个数3*(128*128)+1=49153
原CNN参数量约13000000
所以一层输出神经元最好不要超过256
| 网络层 | 输入 | 输出 | 计算式 | 参数量 |
| FC1 | 3*(128*128) | 256 | (3*128*128+1)*256 | 12583168 |
| FC2 | 256 | 128 | (256+1)*128 | 32896 |
| FC3 | 128 | 64 | (128+1)*64 | 8256 |
| FC4 | 64 | 11 | (64+1)*11 | 715 |
这次正确率严重受损:
| [030/050] 6.23 sec(s) Train Acc: 0.337928 Loss: 0.014742 | Val Acc: 0.306997 loss: 0.015497 |
| [050/050] 6.63 sec(s) Train Acc: 0.391749 Loss: 0.013394 | Val Acc: 0.285423 loss: 0.016252 |
4. 模型比较结论
請說明由 1 ~ 3 題的實驗中你觀察到了什麼?(1%)
由实验可以看出, 对影响处理分类时, 在参数量相似的情况下, 使用DNN比使用CNN模型训练正确率有较大的提升; 并且参数量相似情况下, CNN的深度增加, 对获得更好的训练结果也有一定帮助.
5. 数据归一化与数据增强
請嘗試 data normalization 及 data augmentation,說明實作方法並且說明實行前後對準確率有什麼樣的影響?(1%)
归一化
两种方法:
1. 直接transforms.ToTensor()
ToTensor()将shape为(H, W, C)的nump.ndarray或img转为shape为(C, H, W)的tensor,其将每一个数值归一化到[0,1],其归一化方法比较简单,直接除以255.
2. ToTensor 后加Normalize()
transforms.Compose([transforms.ToTensor(),transforms.Normalize(std=(0.5,0.5,0.5),mean=(0.5,0.5,0.5))]),则其作用就是先将输入归一化到(0,1),再使用公式"(x-mean)/std",将每个元素分布到(-1,1)
数据增强
数据增强有翻转(flips)、移位(translations)、旋转(rotations)、缩放比例(Scale)、裁剪(Crop)、高斯噪声(Gaussian Noise)等微小的改变.
在使用增强技术时,需确保不增加不相关的数据。比如现实中不可能出现的图片方向.
归一化与数据增强对应的代码分别为:
| transforms.ToTensor() # 图片转化为张量Tensor,並把數值 normalize 到 [0,1] (data normalization) |
| transforms.RandomHorizontalFlip() # 随机将图片水平翻转 transforms.RandomRotation(15) # 随机选择图片 |
转tensor不归一化
参考: https://blog.csdn.net/giganticpower/article/details/108195052
PILImage->numpy->tensor
需要考虑tensor默认是CHW; PIL是HWC, 应该进行维度转换.
| #法1 #image = Image.open(image_path) # 读取图片 image = np.array(image, dtype=np.float32) # PILImage->numpy 输出(h,w,c) image = np.transpose(image, (2, 0, 1)) # np下维度转换使用transpose,类似矩阵转置 #image /= 255.0 image = torch.from_numpy(image) # numpy->tensor, 张量和ndarray共享同一内存, 不能调整大小 |
| #法2 image = cv2.imread(image_path) # 使用cv读直接为numpy格式 image = image.astype(np.float32) image /= 255.0 image = np.transpose(image, (2, 0, 1)) image = torch.from_numpy(image) |
其中, numpy->tensor过程中:
使用torch.from_numpy更加安全,使用tensor.Tensor在非float类型下会与预期不符。
torch.Tensor就如同c的int,torch.from_numpy就如同c++的static_cast
报错:
| float() argument must be a string or a number, not 'Compose' |
不能直接对transform进行转换, 可以放在ImgDataset中对X处理
| X = np.array(X, dtype=np.float32) # PILImage->numpy 输出(h,w,c) X = np.transpose(X, (2, 0, 1)) # np下维度转换使用transpose,类似矩阵转置 X = torch.from_numpy(X) # numpy->tensor, 张量和ndarray共享同一内存, 不能调整大小 |
如果不用transforms会报错
| forward函数处 out = self.cnn(x)处 Given groups=1, weight of size [64, 3, 3, 3], expected input[128, 128, 128, 3] to have 3 channels, but got 128 channels instead |
即cnn喂入input 維度应该是 [3, 128, 128], 所以还是需要transform把维度转置一下
结果比较
进行归一化, 数据增强的准确率:
| [030/030] 22.20 sec(s) Train Acc: 0.875329 Loss: 0.002861 | Val Acc: 0.624781 loss: 0.011972 |
未进行归一化, 有数据增强的准确率:
| [030/050] 20.69 sec(s) Train Acc: 0.848976 Loss: 0.003441 | Val Acc: 0.632945 loss: 0.011078 [050/050] 20.78 sec(s) Train Acc: 0.966552 Loss: 0.000791 | Val Acc: 0.627697 loss: 0.018501 |
不进行归一化有一点微微下降, 但是不明显.
未进行归一化, 未数据增强的正确率:
| [030/050] 18.74 sec(s) Train Acc: 0.978208 Loss: 0.000575 | Val Acc: 0.588338 loss: 0.018233 [050/050] 19.02 sec(s) Train Acc: 0.988648 Loss: 0.000283 | Val Acc: 0.607289 loss: 0.024831 |
不进行数据增强后, 明显看到训练集收敛速度变快, 但是验证集表现更差.
6.混淆矩阵
觀察答錯的圖片中,哪些 class 彼此間容易用混?[繪出 confusion matrix 分析](1%)

matplotlib绘制混淆矩阵, 参考:
https://www.jianshu.com/p/cd59aed787cf
cm - 混淆矩阵的数值, 是一个二维numpy数组
classes - 各个类别的标签(label)
title - 图片标题
cmap - 颜色图
| def plot_confusion_matrix(cm, savename, title='Confusion Matrix'): plt.figure(figsize=(12, 8), dpi=100) np.set_printoptions(precision=2) # 在混淆矩阵中每格的概率值 ind_array = np.arange(len(classes)) x, y = np.meshgrid(ind_array, ind_array) for x_val, y_val in zip(x.flatten(), y.flatten()): c = cm[y_val][x_val] if c > 0.001: plt.text(x_val, y_val, "%0.2f" % (c,), color='red', fontsize=15, va='center', ha='center')
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.binary) plt.title(title) plt.colorbar() xlocations = np.array(range(len(classes))) plt.xticks(xlocations, classes, rotation=90) plt.yticks(xlocations, classes) plt.ylabel('Actual label') plt.xlabel('Predict label')
# offset the tick tick_marks = np.array(range(len(classes))) + 0.5 plt.gca().set_xticks(tick_marks, minor=True) plt.gca().set_yticks(tick_marks, minor=True) plt.gca().xaxis.set_ticks_position('none') plt.gca().yaxis.set_ticks_position('none') plt.grid(True, which='minor', linestyle='-') plt.gcf().subplots_adjust(bottom=0.15)
# show confusion matrix plt.savefig(savename, format='png') plt.show() |
参考多篇教程, 这个cm的二维数组都是用sklearn实现, 参考:
https://zhuanlan.zhihu.com/p/73558315
| from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt |
| # classes表示不同类别的名称,比如这有6个类别 classes = ['A', 'B', 'C', 'D', 'E', 'F'] random_numbers = np.random.randint(6, size=50) # 6个类别,随机生成50个样本 y_true = random_numbers.copy() # 样本实际标签 random_numbers[:10] = np.random.randint(6, size=10) # 将前10个样本的值进行随机更改 y_pred = random_numbers # 样本预测标签 # 获取混淆矩阵 cm = confusion_matrix(y_true, y_pred) plot_confusion_matrix(cm, 'confusion_matrix.png', title='confusion matrix') |
数据准备
classes - 各个类别的标签(label)
Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, and Vegetable/Fruit.
| 0 | Bread |
| 1 | Dairy product |
| 2 | Dessert |
| 3 | Egg |
| 4 | Fried food |
| 5 | Meat |
| 6 | Noodles/Pasta |
| 7 | Rice |
| 8 | Seafood |
| 9 | Soup |
| 10 | Vegetable/Fruit |
从验证集看图片确认.
y_true样本实际标签
| val_y |
y_pred样本预测标签
| val_pred.cpu().copy() |
参照测试时保存y的方法:
| prediction = [] with torch.no_grad(): for i, data in enumerate(test_loader): test_pred = model_best(data.cuda()) test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1) for y in test_label: prediction.append(y) |
| for i, y in enumerate(prediction): f.write('{},{}\n'.format(i, y)) |
改造验证集的y保存:
| model.eval() with torch.no_grad(): for i, data in enumerate(val_loader): val_pred = model(data[0].cuda()) val_label = np.argmax(val_pred.cpu().data.numpy(), axis=1) for y in val_label: prediction_val.append(y) |
剩下部分与参考代码相似, 不再赘述.
最后获得混淆矩阵图:
观察发现, 米饭分类正确的数值低, 但没有明显的易混淆类别, 可能是不同类别的样本数目不同导致, 做一下归一也许会更好.
在绘图前对混淆矩阵按行做一个标准化处理,即得到的是概率值,每行所有的概率之和为1,所以对角线就代表每个类别的查全率(召回率).
| # Normalize by row cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] print(cm_normalized) |
其中, np.newaxis的功能:插入新维度. [: , np.newaxis]则在列上增加一维, [np.newaxis,:]则在行增加一维. 可将一维的数据转变成一个矩阵.
标准化后的混淆矩阵为:

从上图可以看出, 最易混淆的类别:
奶制品易被认作甜点, 海鲜易被认作果蔬, 米饭易被认作面条.

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)