re.match函数讲解
之前一直对re.match函数的匹配方法感到困惑,今天用具体的例子来讲解一下re.match函数匹配到的不同内容:第一组代码import reline = "Cats are smarter than dogs"matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)if matchObj:print("matchObj.group()
之前一直对re.match函数的匹配方法感到困惑,今天用具体的例子来讲解一下re.match函数匹配到的不同内容:
第一组代码
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print("matchObj.group() : ", matchObj.group())
print("matchObj.group(1) : ", matchObj.group(1))
print("matchObj.group(2) : ", matchObj.group(2))
else:
print("No match!!")
对应输出的内容为:
 可以看出来这里的matchObj.group(1)匹配的是前面括号之中的.*,而matchObj.group(2)匹配的是后面括号之中的smarter
可以看出来这里的matchObj.group(1)匹配的是前面括号之中的.*,而matchObj.group(2)匹配的是后面括号之中的smarter
将第一组代码变换一下,变换成为如下的代码
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*)( are )(.*?) .*', line, re.M|re.I)
if matchObj:
print("matchObj.group() : ", matchObj.group())
print("matchObj.group(1) : ", matchObj.group(1))
print("matchObj.group(2) : ", matchObj.group(2))
print("matchObj.group(3) : ", matchObj.group(3))
else:
print("No match!!")
可以看到输出的对应内容如下:
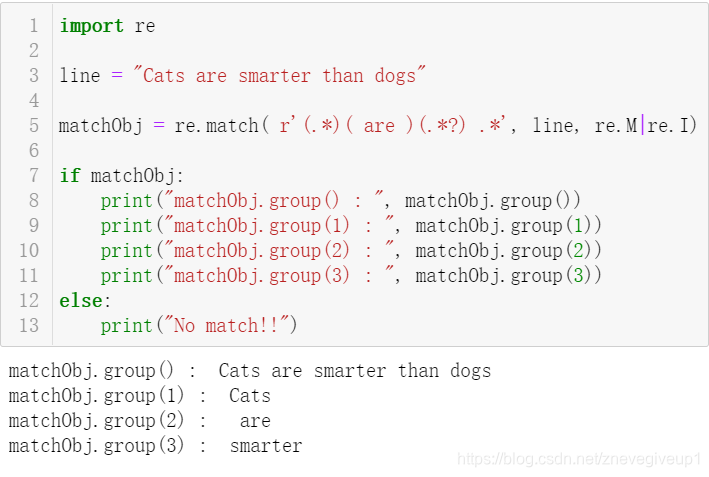 matchObj.group(1)匹配的是第一个
(
.
∗
)
(.*)
(.∗)中的内容,对应内容为Cats,matchObj.group(2)匹配的是第二个( are )中的内容,对应的输出为 are ,matchObj.group(3)匹配的是第三个
(
.
∗
?
)
(.*?)
(.∗?)中的内容,即smarter
matchObj.group(1)匹配的是第一个
(
.
∗
)
(.*)
(.∗)中的内容,对应内容为Cats,matchObj.group(2)匹配的是第二个( are )中的内容,对应的输出为 are ,matchObj.group(3)匹配的是第三个
(
.
∗
?
)
(.*?)
(.∗?)中的内容,即smarter
总结,如果想要在re.match匹配的过程中保存下来匹配完成的结果的时候,需要使用(),有几个括号,re.match出来的结果matchObj.group()的下标就从1到几,最终输出对应的匹配的结果。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)