python requests实现登录
requests+cookie实现登录爬虫
·
登录爬虫案例
基于requests模块的登录
使用requests模块发送登录请求,并将响应后的cookie添加在后续需要登录的数据请求中,实现登录。
案例1
scrape2 url:https://login2.scrape.center/login
登录接口解析
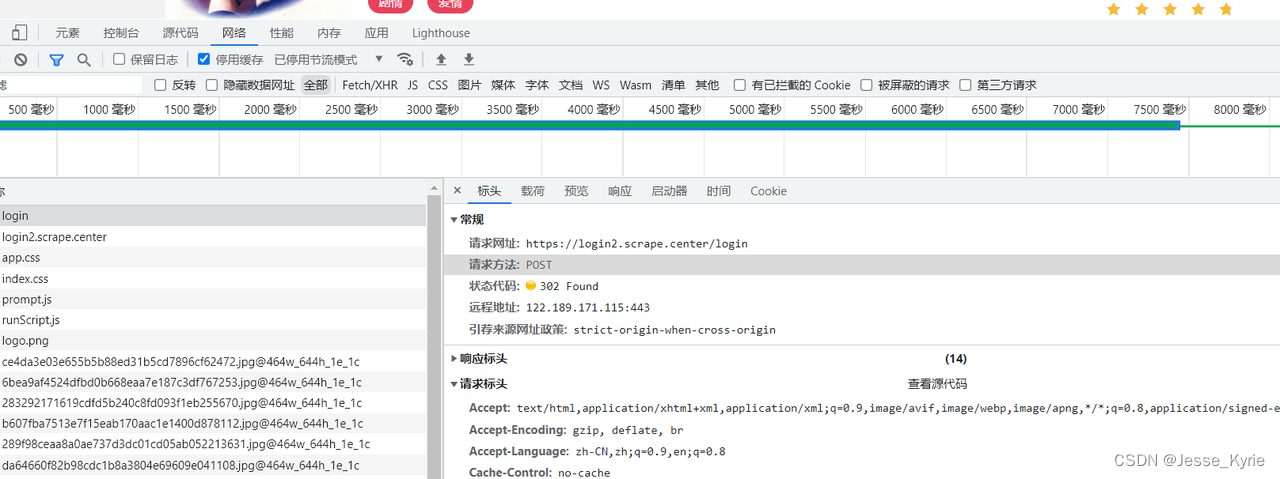
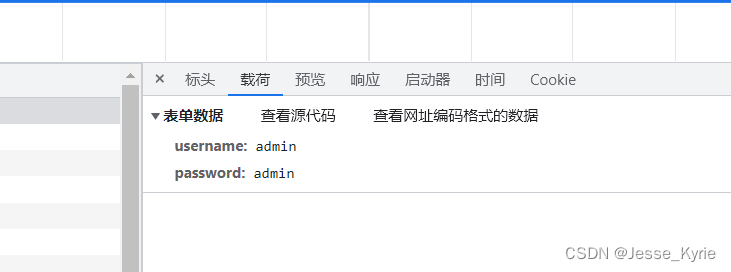
无参数加密情况
# coding=utf-8
base_url = 'https://login2.scrape.center/'
index_url = 'https://login2.scrape.center/'
import requests
login_data = {
'username': '', # 用户名
'password': '', # 密码
} # 默认都为admin
# 登录的核心为获取到登录后的cookies
# 可根据加密的困难成度选择浏览器模拟登录或者代码登录
# 本例中使用代码登录,按照登录页面的提示,使用post请求登录
# 通过观察登录页面的源代码,发现登录的url为https://login2.scrape.center/login
# 通过观察登录页面的源代码,发现登录的表单数据为username和password
# 构建普通登录请求,注意需要将登录时将requests的允许重定向allow_redirects设置为False
response = requests.post(base_url + 'login', data=login_data, allow_redirects=False)
stauts = response.status_code
resp_html = response.text
logined_cookies = response.cookies
print(stauts)
print(logined_cookies)
# 将cookies输出为字典
print(dict(logined_cookies))
# 结果===>登录成功
# 302
# <RequestsCookieJar[<Cookie sessionid=m97f80sv0s9kd80o25g9t3iomxa30gdk for login2.scrape.center/>]>
# {'sessionid': 'm97f80sv0s9kd80o25g9t3iomxa30gdk'}
# 登录后获取详情页
data_response = requests.get(index_url, cookies=logined_cookies)
data_status = data_response.status_code
data_html = data_response.text
print(data_status)
print(data_html)
# 结果===>数据获取成功
# 200
# <html lang="en">...</html>
# 以上代码可优化,使用requests.Session()方法,将cookies保存在session中,后续请求直接使用session即可
# 需要注意的是,因为后的cookies会有过期时间,所以需要定时更新cookies
# 使用session优化代码
session = requests.Session()
session.post(base_url + 'login', data=login_data)
data_response = session.get(index_url)
data_status = data_response.status_code
data_html = data_response.text
print(data_status)
print(data_html)
# 结果===>数据获取成功
直接通过response.cookies获取到登录后的cookie,并将其放在后续的数据请求中,即可实现登录请求。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)