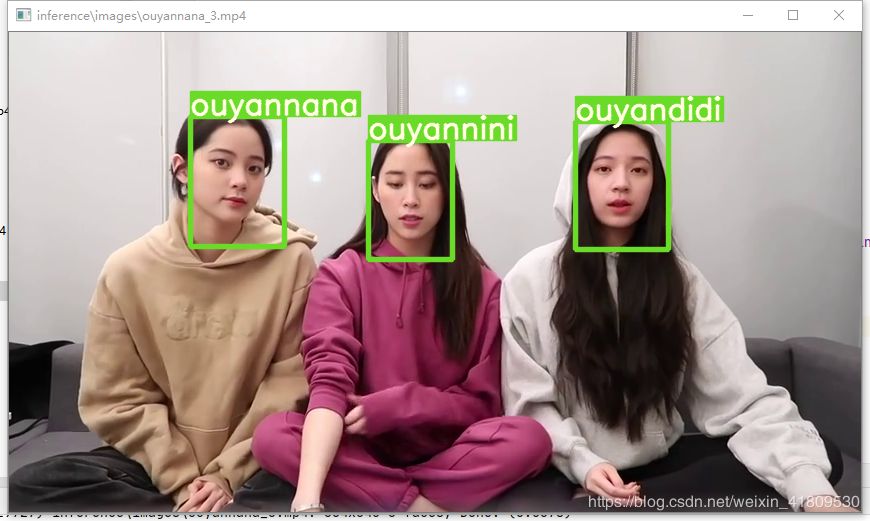
YOLOv5 输出目标检测物的坐标信息和类别(可结合flask或者fastapi开发成目标检测接口)
YOLOv5 输出目标检测物的坐标信息和类别(可结合flask或者fastapi开发成目标检测接口)直接上代码import ioimport numpy as npimport cv2import torchfrom PIL import Imagefrom numpy import random'''代码:由YOLOv5自带的detect.py 改编实现:输入图片进行检测,输出图片的类别和坐标和
·
YOLOv5 输出目标检测物的坐标信息和类别(可结合flask或者fastapi开发成目标检测接口)
直接上代码
import io
import numpy as np
import cv2
import torch
from PIL import Image
from numpy import random
'''
代码:由YOLOv5自带的detect.py 改编
实现:输入图片进行检测,输出图片的类别和坐标和对应的分数
autor:小帆芽芽
date:2021/12/21
'''
from YOLO.models.experimental import attempt_load
from YOLO.utils.general import check_img_size, non_max_suppression, scale_coords, \
set_logging
from YOLO.utils.torch_utils import select_device, time_synchronized
def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True):
# Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, 32), np.mod(dh, 32) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return img, ratio, (dw, dh)
weights = 'YOLO/weights/best.pt' # 训练好的模型位置
opt_device = '' # device = 'cpu' or '0' or '0,1,2,3'
imgsz = 640
opt_conf_thres = 0.25
opt_iou_thres = 0.5
# Initialize
set_logging()
device = select_device(opt_device)
half = device.type != 'cpu' # half precision only supported on CUDA
# 加载模型
model = attempt_load(weights, map_location=device) # load FP32 model
imgsz = check_img_size(imgsz, s=model.stride.max()) # check img_size
if half:
model.half() # to FP16
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names # 获取标签
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# def transform_image(image_bytes):
# image = Image.open(io.BytesIO(image_bytes))
# # img = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
# # img = cv2.cvtColor(np.asarray(image), cv2.COLOR_BGR)
# # print(img)
# return image
# (接口中传输的二进制流)将二进制用cv2 读取流并转换成yolov5 可接受的图片
def bytes_img(image_bytes):
# 二进制数据流转np.ndarray [np.uint8: 8位像素]
img = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return rgb_img
# '''
# [[[ 60 65 68]
# [202 205 213]
# [207 208 228]
# '''
# 上传图片
def predict_(pic_):
# Run inference
img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img
_ = model(img.half() if half else img) if device.type != 'cpu' else None # run once
# Set Dataloader & Run inference
im0s = pic_ # BGR # 蓝绿红
img = letterbox(im0s, new_shape=imgsz)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
# pred = model(img, augment=opt.augment)[0]
pred = model(img)[0]
# Apply NMS
pred = non_max_suppression(pred, opt_conf_thres, opt_iou_thres)
# Process detections
detect_info = []
for i, det in enumerate(pred): # detections per image
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0s.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
dic ={
'class':f'{names[int(cls)]}', # 检测目标对应的类别名
'location':torch.tensor(xyxy).view(1, 4).view(-1).tolist(), # 坐标信息
'score': round(float(conf) * 100, 2) # 目标检测分数
}
detect_info.append(dic)
return detect_info

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)