用python实现英文字符的词频统计,忽略大小写,以降序的形式输出
一、实现代码如下'''构造一个词频统计系统,不区分大小写,并将之按照词频由高到低进行排序'''#输入需要统计的英文字符结构english = input('请输入一串英文字符,无需区分大小写:')#统一大小写english = english.lower()#构建统计字典counts = {}for letter in english:counts[letter] = counts.get(let
·
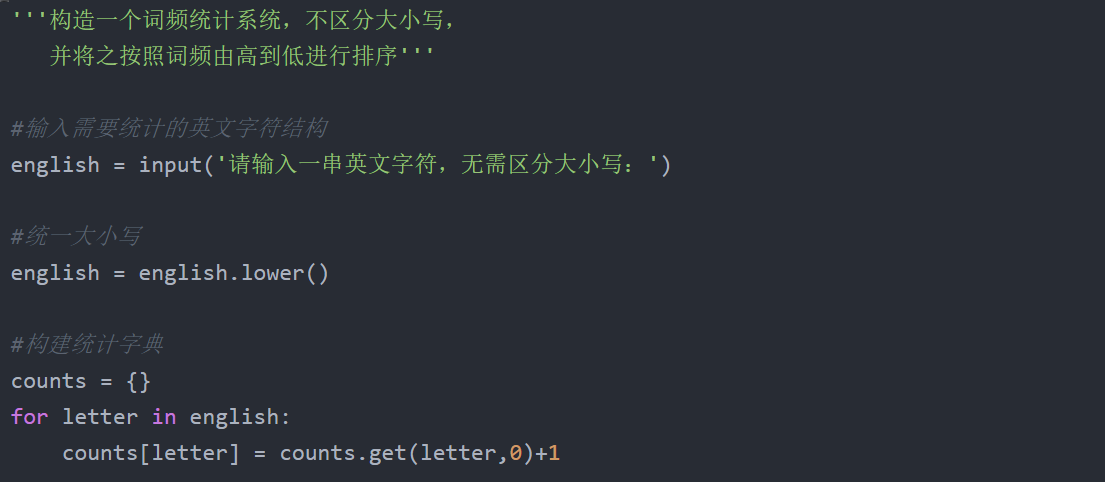
一、实现代码如下
'''构造一个词频统计系统,不区分大小写,
并将之按照词频由高到低进行排序'''
#输入需要统计的英文字符结构
english = input('请输入一串英文字符,无需区分大小写:')
#统一大小写
english = english.lower()
#构建统计字典
counts = {}
for letter in english:
counts[letter] = counts.get(letter,0)+1
#排序
ls = list(counts.items())
print('还未排序的统计数据:'+str(ls))
ls.sort(key=lambda x:x[1],reverse=True)
print('按从高到低排序后的数据:'+str(ls))二、代码结果展示

三、代码分析
要实现这个小程序的要求,需要掌握几个要点:
1、大小写转换:
变量.lower() #全变小写
变量.upper() #全变大写2、遍历循环结构for的使用:
counts = {} #因为有统计需求,我们构造一个字典
for letter in english:
#letter是作为我们定义的一个变量进行遍历注意默认返回的字典的键,即上面定义的变量letter(字母)等于字典中的key(键)。
3、利用字典进行键值统计,注意分清键值对应:
counts[letter] = counts.get(letter,0)+1
#当原来字典中没有字母对应的键时,构造键,值返回0,并+1
#当字典中原来有对应的键时,返回原来键的值,并+14、降序排列:
因为涉及顺序问题,所以由字典的映射类型,想到转换为列表的序列类型。
ls = list(counts.items())注意对字典采用的操作方法为.items(),抓取键值对全部信息。
5、用sort方法进行排列:
ls.sort(key=lambada x:x[1],reverse=True)注意我们是按照字符出现的次数,也就是值进行排序,所以key设定到x[1]。sort方法默认为升序排列,采用reverse可以反转。
结:这是小白阿爻第一篇CSDN博文分享,以后会在这上面分享更多的经验,与大家一同实现编程算法能力的提升。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)