python数据分析项目之超市零售分析
文章目录一、明确需求和目的二、数据收集三、数据清洗1.列名重命名2.数据类型处理3.缺失值处理4.异常值处理5.重复值处理四、数据分析1.整体销售情况分析2.商品情况分析3.用户情况分析五、总结(附python代码)一、明确需求和目的对一家全球超市四年(2011-2014)的销售数据进行 “人、货、场”分析,并给出提升销量的针对性建议。场:整体运营情况分析,包括销售额、销量、利润、客单价、市场布局
文章目录
一、明确需求和目的
- 对一家全球超市四年(2011-2014)的销售数据进行 “人、货、场”分析,并给出提升销量的针对性建议。
- 场:整体运营情况分析,包括销售额、销量、利润、客单价、市场布局等具体情况分析。
- 货:商品结构、优势/爆款商品、劣势/待优化商品等情况分析。
- 人:客户数量、新老客户、RFM模型、复购率、回购率等用户行为分析。
二、数据收集
- 数据来源为kaggle平台,这是一份全球大型超市四年的零售数据集,数据详尽。
- 数据集为 “superstore_dataset2011-2015.csv”,共有51290条数据,共24个特征。
三、数据清洗
1.列名重命名
从数据集里面我们可以发现不符合Python的命名规范,需要对列名进行一下重命名,采用下划线命名法:
df.rename(columns = lambda x: x.replace(' ', '_').replace('-', '_'), inplace=True)
2.数据类型处理
需要进行处理 下单日期 为datetime类型:
df["Order_Date"] = pd.to_datetime(df["Order_Date"])
df['year'] = df["Order_Date"].dt.year
df['month'] = df['Order_Date'].values.astype('datetime64[M]')
3.缺失值处理
使用 df.isnull().sum(axis=0) 可以发现,邮编信息列缺失值比较多,对数据分析没有太多作用,可直接删除:
df.drop(["Postal_Code"],axis=1, inplace=True)
4.异常值处理
通过 df.describe() 简单查看一下是否有异常值,由于没有发现明显的异常值,不需要进行处理。

5.重复值处理
使用 df.duplicated().sum() 看一下是否有重复值,由于没有重复值,所以不需要进行处理。
四、数据分析

1.整体销售情况分析
- 销售额分析
构建销售表:

从上图可以看出,基本上每一年都是下半年销售额比上半年要高,而且随着年份的增大,销售额也有明显的增加,说明销售业绩增长较快,发展还是比较好的。
销售额的面积堆叠图:

从上图可以大致看出,该超市的销售季节性明显,总体上半年是淡季,下半年是旺季。上半年中6月份销售额比较高,下半年中7月份的销售额偏低。
- 销量分析
构建销量表:

从上面可以看出,2011-2014年销量变化趋势与销售额是一样的,下半年销量整体高于上半年,同时销量同比上一年均在提高。
- 利润分析
构建利润表:

从上面的结果可以看出,每年的利润和销售额一样,是在逐年增加的,说明企业经营还是比较妥善的,但是利润率总体平稳,稳定在11%-12%之间,总体利润率也还是不错的。
- 客单价分析
客单价是指商场(超市)每一个顾客平均购买商品的金额,客单价也即是平均交易金额。从某种程度上反映了企业的消费群体的许多特点以及企业的销售类目的盈利状态是否健康。
总消费次数:同一天内,同一个人发生的所有消费算作一次消费。
客单价 = 总消费金额 / 总消费次数
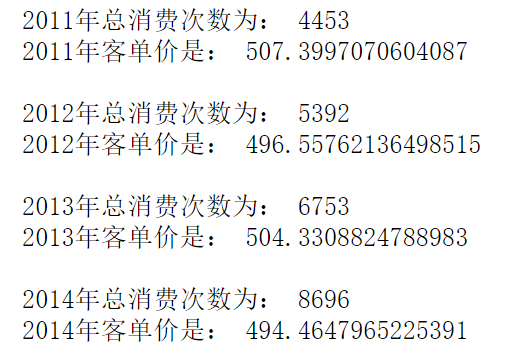
从上面结果来看,每年的消费次数呈不断上升趋势,但是客单价总体浮动范围不是很大 ,稳定在500左右。
- 市场布局分析
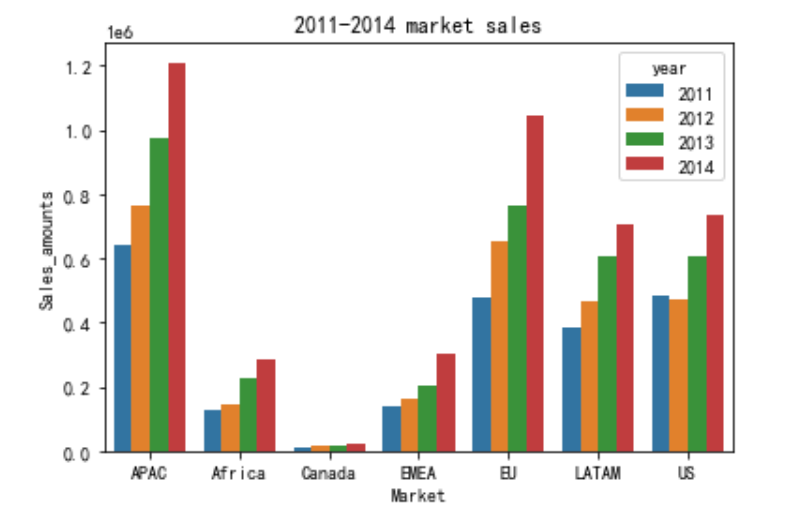
各个地区每年的销售情况:
四年来各个地区销售额占总销售额的百分比:

从以上图表可以看出,每个地区每年销售额总体处于上升趋势,其中APAC(亚太地区)、EU(欧盟)、US(美国)、LATAM(拉丁美洲)的销售额超过了总销售额的85%,总体也与地区的经济发展相匹配。其中加拿大Canada的销售额微乎其微,可以结合公司整体战略布局进行取舍。
2.商品情况分析
销量前10名的商品:

销售额前10名的商品:

利润前10的商品:

具体商品种类的销售情况:

从图表中可以很清晰的看到不同种类商品的销售额贡献对比,有将近一半的商品的总销售占比达到84%,应该是自家优势主营产品,后续经营中应继续保持,可以结合整体战略发展适当加大投入,逐渐形成自己的品牌。
同时,也可以发现,末尾占比16%的产品中大部分是办公用品中的小物件。可以考虑与其他主营产品结合,连带销售来提升销量,或者考虑对这些商品进行优化。
但是值得关注的是,Tables(桌子)的利润是负,表明这个产品目前处于亏损状态,应该是促销让利太多。但如果不是,说明这个产品在市场推广上遇到了瓶颈,或者是遇到强竞争对手,需要结合实际业务进行分析,适当改善经营策略。
3.用户情况分析
- 不同类型的客户占比

从上图可以看出,这四年来,普通消费者的客户占比最多,达到51.7%。
每一年不同类型的客户数量情况:

从上面可以看出,每类客户每年均在保持增长趋势,客户结构还是非常不错的。
不同类型的客户每年贡献的销售额:

各个类型的客户每年贡献的销售额都在稳步提升,普通消费者贡献的销售额最多,这和客户占比也有一定关系。
- 客户下单行为分析
用户的第一次购买日期分布:
用户的最后一次购买日期分布:

总体来说新客户数量是在逐年递减的,说明该企业老客户的维系不错,但新客获取率较低。如果能够在新客户获取上能够突破,会给企业带来很大的增长空间。
- RFM模型分析
RFM的含义:
R(Recency):客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
F(Frequency):客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
M(Monetary):客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
RFM分析就是根据客户活跃程度和交易金额的贡献,进行客户价值细分的一种方法。
首先构建RFM表:
接着对客户价值进行标注,将客户分为8个等级(2 x 2 x 2):
对重要价值客户和非重要价值客户进行可视化展示:
通过RFM识别不同的客户群体,能够衡量客户价值和客户利润创收能力,可以指定个性化的沟通和营销服务,为更多的营销决策提供有力支持,为企业创造更大的利益。
- 新用户、活跃用户、不活跃用户和回归用户分析
设置Customer_ID为索引,month为列名,统计每个月的购买次数:
定义状态函数并进行状态标记:
统计每月各状态客户数量:

从以上结果可以发现活跃客户、新客户和回归客户,每年呈一定的规律起伏,这可能和年终年末大促有关,需要更多数据进行佐证;同时可以发现新客数量每年均在减少,说明该商家新客获取率较低,如果能在新客户获取上取得突破,会给商家带来很大的增长空间。
- 复购率和回购率分析
复购率计算指标:用户在该月购买过一次以上算复购。

回购率计算指标:在该月购买过,且在下月也购买时计入回购。

五、总结(附python代码)
本文分别通过“场、货、人”三个不同的角度去分析一家全球超市的销售、商品、用户情况,并根据分析结果给出一些有利于拓展用户、提升销量的办法。当然,这份数据集包含信息很多,还可以进行其它一些方面的分析,来给出更好的建议。
# 项目代码如下:
# 加载数据分析需要使用的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
# 使图形中的中文正常编码显示 SimHei是指黑体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 过滤掉一些没必要的警告
warnings.filterwarnings('ignore')
# 使用'ISO-8859-1'编码方式
df = pd.read_csv('superstore_dataset2011-2015.csv',encoding='ISO-8859-1')
df.head()
## 转换 datetime 类型
df['Order_Date'] = pd.to_datetime(df['Order_Date'])
## 增加年份列和月份列
df['year'] = df['Order_Date'].dt.year
df['month'] = df['Order_Date'].values.astype('datetime64[M]')
## 发现有一列缺失值比较多,此列表示邮编信息,对我们的分析没有太多作用,可直接删除
df.drop(['Postal_Code'],axis = 1,inplace = True)
# 整体销售情况分析
sales_data = df[['Order_Date','Sales','Quantity','Profit','year','month']]
## 按照年份、月份对销售子数据集进行分组求和
sales_year = sales_data.groupby(['year','month']).sum()
## slice(None) 是指不切任何东西,选择全部行数据,类似于填充
year_2011 = sales_year.loc[(2011,slice(None)),:].reset_index()
year_2011 = sales_year.loc[(2011,slice(None)),:].reset_index()
year_2012 = sales_year.loc[(2012,slice(None)),:].reset_index()
year_2013 = sales_year.loc[(2013,slice(None)),:].reset_index()
year_2014 = sales_year.loc[(2014,slice(None)),:].reset_index()
## 构建销售表
sales = pd.concat([year_2011['Sales'],year_2012['Sales'],
year_2013['Sales'],year_2014['Sales']],axis=1)
## 重新命名行列
sales.index = ['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
sales.columns = ['Sales-2011','Sales-2012','Sales-2013','Sales-2014']
## 颜色越深,销售额越高
sales.style.background_gradient()
## 绘制年度销售额的柱形图
sales_sum = sales.sum()
sales_sum.plot(kind = 'bar', alpha = 0.5)
plt.grid()
## 计算增长率
rise1 = sales_sum[1]/sales_sum[0] - 1
rise2 = sales_sum[2]/sales_sum[1] - 1
rise3 = sales_sum[3]/sales_sum[2] - 1
rise = [0,rise1,rise2,rise3]
## 制作 增长率和销售额 的 dataframe ____ DateFrame 字母大小写不要写错了
sales_table = pd.DataFrame({'sales_sum':sales_sum, 'rise_rate':rise})
## 年销售额堆积图
sales.plot.area()
# 销量分析
## 制作销售表
quantity = pd.concat([year_2011['Quantity'],year_2012['Quantity'], year_2013['Quantity'],year_2014['Quantity']],axis=1)
## 重新命名行列
quantity.index = ['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
quantity.columns = ['Quantity-2011','Quantity-2012','Quantity-2013','Quantity-2014']
## 颜色越深,销售额越高
quantity.style.background_gradient()
# 计算年度销量并图表展示
quantity_sum = quantity.sum()
quantity_sum.plot(kind='bar',alpha=0.5)
plt.grid()
## 计算增长率
rise11 = quantity_sum[1]/quantity_sum[0] - 1
rise22 = quantity_sum[2]/quantity_sum[1] - 1
rise33 = quantity_sum[3]/quantity_sum[2] - 1
rise = [0,rise11,rise22,rise33]
## 制作 增长率和销售额 的 DateFrame
quantity_table = pd.DataFrame({'quantity_sum':quantity_sum, 'rise_rate':rise})
# 利润分析
profit=pd.concat([year_2011['Profit'],year_2012['Profit'],
year_2013['Profit'],year_2014['Profit']],axis=1)
profit.columns=['Profit-2011','Profit-2012','Profit-2013','Profit-2014']
profit.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
profit.style.background_gradient()
profit_sum=profit.sum()
profit_sum.plot(kind='bar',alpha=0.5)
plt.grid()
## 计算利润率 ____ np.array 数组类型才具有广播性; pd.Series的对象是np.array 不然会出现NaN
profit_rate = np.array(profit_sum)/ np.array(sales_sum)
profit_rate1 = pd.Series(profit_rate,index = [2011, 2012, 2013, 2014])
profit_sum1 = pd.Series(np.array(profit_sum),index = [2011, 2012, 2013, 2014])
sales_sum1 = pd.Series(np.array(sales_sum),index = [2011, 2012, 2013, 2014])
## 合并 Series 数组
profit_table = pd.concat([profit_sum1,sales_sum1,profit_rate1],axis = 1)
profit_table.columns = ['profit_sum','sales_sum','profit_rate']
profit_table
# 客单价分析
## 2011 - 2014 年客单价
for i in range(2011,2015):
df2 = df[df['year'] == i]
price = df2[['Order_Date','Customer_ID','Sales']]
## 计算总消费次数
price_dr = price.drop_duplicates(subset = ['Order_Date','Customer_ID'])
total_num = price_dr.shape[0]
print('{}年总消费次数为:'.format(i),total_num)
## 客单价
unit_price = price['Sales'].sum()/total_num
print('{}年客单价是:'.format(i),unit_price,'\n')
# 市场布局分析 ____ agg是aggregate的别名,
Market_Year_Sales = df.groupby(['Market', 'year']).agg({'Sales':'sum'}).reset_index().rename(columns={'Sales':'Sales_amounts'})
Market_Year_Sales.head()
## 各个地区每年的销售情况
sns.barplot(x='Market', y='Sales_amounts', hue='year', data = Market_Year_Sales)
plt.title('2011-2014 market sales')
## 四年来各个地区销售额占总销售额的百分比
Market_Sales = df.groupby(['Market']).agg({'Sales':'sum'})
Market_Sales["percent"] = Market_Sales["Sales"] / df["Sales"].sum()
Market_Sales.style.background_gradient()
## 先看一下销量前10名的商品
productId_count = df.groupby('Product_ID').count()['Customer_ID'].sort_values(ascending=False)
print(productId_count.head(10))
## 销售额前10名的商品
productId_amount = df.groupby('Product_ID').sum()['Sales'].sort_values(ascending=False)
print(productId_amount.head(10))
## 利润前10的商品
productId_Profit= df.groupby('Product_ID').sum()['Profit'].sort_values(ascending=False)
print(productId_Profit.head(10))
# 根据商品种类和子种类,重新重合成一个新的种类
df['Category_Sub_Category'] = df[['Category','Sub_Category']].apply(lambda x:str(x[0])+'_'+str(x[1]),axis=1)
# 按照新的种类进行分组,统计销售额和利润
df_Category_Sub_Category=df.groupby("Category_Sub_Category").agg({"Profit":"sum","Sales":"sum"}).reset_index()
# 按照销售额倒序排序
df_Category_Sub_Category.sort_values(by=["Sales"],ascending=False, inplace=True)
# 每个种类商品的销售额累计占比 ____ cumsum()实现了累计百分比
df_Category_Sub_Category['cum_percent'] = df_Category_Sub_Category['Sales'].cumsum()/df_Category_Sub_Category['Sales'].sum()
df_Category_Sub_Category
## 不同类型的客户占比
df["Segment"].value_counts().plot(kind='pie', autopct='%.2f%%', shadow=False, figsize=(14, 6))
## 每一年不同类型的客户数量情况
Segment_Year = df.groupby(["Segment", 'year']).agg({'Customer_ID':'count'}).reset_index()
sns.barplot(x='Segment', y='Customer_ID', hue='year', data = Segment_Year)
plt.title('2011-2014 Segment Customer')
## 不同类型的客户每年贡献的销售额
Segment_sales = df.groupby(["Segment", 'year']).agg({'Sales':'sum'}).reset_index()
sns.barplot(x='Segment', y='Sales', hue='year', data = Segment_sales)
plt.title('2011-2014 Segment Sales')
# 客户下单行为分析
grouped_Customer = df[['Customer_ID','Order_Date',
'Quantity', 'Sales', 'month']].sort_values(['Order_Date']).groupby('Customer_ID')
grouped_Customer.head()
## 看一下用户的第一次购买日期分布 ____ grouped_Customer.min().Order_Date 留下最小值的日期
grouped_Customer.min().Order_Date.value_counts().plot()
## 看一下用户的最后一次购买日期分布
grouped_Customer.max().Order_Date.value_counts().plot()
### 可以是这种形式: grouped_Customer.max()['Order_Date'].value_counts().plot()
# 看看只购买过一次的客户数量 :
## 统计每个客户第一次和最后一次购买记录
Customer_life = grouped_Customer.Order_Date.agg(['min','max'])
## 查看只有一次购买记录的顾客数量,第一次和最后一次是同一条记录,则说明购买只有一次
(Customer_life['min'] == Customer_life['max']).value_counts()
# 首先构建RFM表 ---- 注意:逗号不要丢;花括号方括号区别开来;values别拼错
rfm = df.pivot_table(index='Customer_ID',
values = ["Order_ID","Sales","Order_Date"],
aggfunc={"Order_ID":"count","Sales":"sum","Order_Date":"max"})
## 所有用户最大的交易日期为标准,求每笔交易的时间间隔即为R
rfm['R'] = (rfm.Order_Date.max() - rfm.Order_Date)/np.timedelta64(1,'D')
## 每个客户的订单数即为F,总销售额即为M
rfm.rename(columns={'Order_ID':'F','Sales':'M'},inplace = True)
## 基于平均值做比较,超过均值为1,否则为0
rfm[['R','F','M']].apply(lambda x:x-x.mean())
def rfm_func(x):
level =x.apply(lambda x:'1'if x>0 else '0')
level =level.R +level.F +level.M
d = {
"111":"重要价值客户",
"011":"重要保持客户",
"101":"重要挽留客户",
"001":"重要发展客户",
"110":"一般价值客户",
"010":"一般保持客户",
"100":"一般挽留客户",
"000":"一般发展客户"
}
result = d[level]
return result
## ---- apply(___,axis =1) 列方向的应用,所以函数的输入值是原有数据的 每一行
rfm['label']= rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis =1)
## 可视化展示 ---- ~:否定符号;loc除了可以切片还可以进行 行列 赋值
## 先筛选出 '重要价值客户' 然后进行 color 赋值
rfm.loc[rfm.label=='重要价值客户','color']='g'
rfm.loc[~(rfm.label=='重要价值客户'),'color']='r'
rfm.plot.scatter('F','R',c= rfm.color)
# 新用户、活跃用户、不活跃用户和回归用户分析
## pivot_table 统计 顾客id 每个月 的购买次数
pivoted_counts = df.pivot_table(index= 'Customer_ID',
columns= 'month',
values= 'Order_Date',
aggfunc= 'count').fillna(0)
# 大于一次的全部设为1
df_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0)
df_purchase.head()
## 对每天进行 状态标记
def active_status(data):
status = []
for i in range(48):
if data[i] == 0:
if len(status)>0:
if status[i-1] == "unreg":
# 未注册客户
status.append("unreg")
else:
# 不活跃用户
status.append("unactive")
else:
status.append("unreg")
# 若本月消费了
else:
if len(status) == 0:
# 新用户
status.append("new")
else:
if status[i-1] == "unactive":
# 回归用户
status.append("return")
elif status[i-1] == "unreg":
status.append("new")
else:
status.append("active")
return pd.Series(status)
## ---- 函数应用的输出是列向,所以函数的输入是 原有data 的每一行
purchase_stats = df_purchase.apply(active_status,axis =1)
purchase_stats.head()
## 用NaN替代 “unreg”,统计每月各状态客户数量 ---- 横轴表示 48 个月份
purchase_stats_ct = purchase_stats.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x))
## 用0填充NaN
purchase_stats_ct.fillna(0).T.plot.area()
## 复购率计算
purchase_r = pivoted_counts.applymap(lambda x :1 if x>1 else np.NaN if x==0 else 0)
## ____ sum()默认输出行方向的,那么对应字段就是日期
(purchase_r.sum()/purchase_r.count()).plot(figsize=(10,4))
## 回购率计算
def purchase_back(data):
status=[]
for i in range(47):
if data[i] ==1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return status
purchase_b = df_purchase.apply(purchase_back,axis =1,result_type='expand')
(purchase_b.sum()/purchase_b.count()).plot(figsize=(10,4))

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)