Pandas 异常值处理
利用Pandas实现空值、重复值、经验异常数据等的删除或替换
常见的数据异常值有空值、重复值、经验异常值、分布异常值等。下面分别讨论通过Pandas的一般处理方式。
1.空值处理
df
Out[1]:
商品名称 地区 销量
0 李老吉 北京 10.0
1 娃啥啥 上海 13.0
2 康帅傅 广州 NaN
(1)判断空值
df.isna()
Out[2]:
商品名称 地区 销量
0 False False False
1 False False False
2 False False True(2)判断一列是否全为空
df
Out[1]:
name age
0 bob NaN
1 tim NaN
2 lucy NaN默认是对所有列进行判断,也可先选择列再进行判断
df.isna().all()
Out[2]:
name age
False True(3)df.isna和df.isnull
有说这个设计是借鉴R语言,na和null是两个不同对象。而再python里,pandas是基于numpy实现的。numpy的空值就只有一个np.nan,因此这两个是一样的,因为两个方法也是一样的。查看源码也可验证
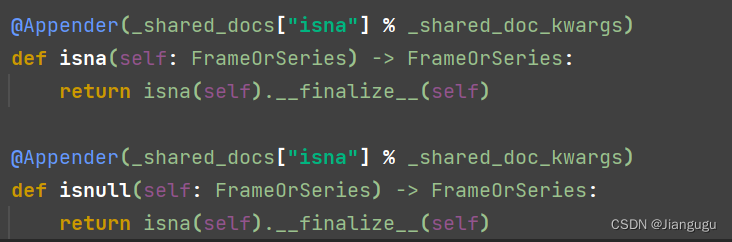
(4)丢弃空值
参数解释:表示在行的方向上,只要有一个空值则舍弃这一行数据。如果只想删除全为空的行,则传入how='all'。默认原df不会改变,可使用新的变量接收返回值。inplace=True表示原df改变。
df.dropna(axis=0, how='any', inplace=True)
Out[3]:
商品名称 地区 销量
0 李老吉 北京 10.0
1 娃啥啥 上海 13.0(5)填充空值
①使用一个固定值填充
# 空值填充为0
df.fillna(0)
Out[4]:
商品名称 地区 销量
0 李老吉 北京 10.0
1 娃啥啥 上海 13.0
2 康帅傅 广州 0.0②向前或向后填充
一般针对时序数据,且某一刻数据和前后时刻差别不大
df
ut[1]:
时间 温度
0 00:00 5.0
1 00:10 4.9
2 00:20 NaN
3 00:30 4.7
# 向前填充,即复制上一个数据;bfill为向后填充;也可以直接使用df.ffill()
# limit=1表示只填充一个空值
df.fillna(method='ffill', limit=1)
Out[2]:
时间 温度
0 00:00 5.0
1 00:10 4.9
2 00:20 4.9
3 00:30 4.7③使用整体数据的均值、最值等填充
df.fillna(df['温度'].mean())
Out[3]:
时间 温度
0 00:00 5.000000
1 00:10 4.900000
2 00:20 4.866667
3 00:30 4.7000002.重复值处理
(1)判断重复行
可以看到,第二次出现的重复行会被标记为True
df
Out[1]:
商品名称 地区 销量
0 李老吉 北京 15
1 娃啥啥 上海 13
2 康帅傅 广州 28
3 娃啥啥 上海 13
df.duplicated()
Out[2]:
0 False
1 False
2 False
3 True(2)删除重复行
df.drop_duplicates()
Out[1]:
商品名称 地区 销量
0 李老吉 北京 15
1 娃啥啥 上海 13
2 康帅傅 广州 28
默认是,当这一行与前面某一行所有元素都重复才删除。否则,需要指定判断重复的标志列。默认保留第一行重复值,也可指定保留最后一行。
df.drop_duplicates(['商品名称'], keep='last')
Out[2]:
商品名称 地区 销量
0 李老吉 北京 15
2 康帅傅 广州 28
3 娃啥啥 上海 133.经验异常值处理
经验指的是行业经验,即要结合具体业务。还是以气温为例子。放在全球来讲,气温最高也就50左右。那么可以简单认为超过60的气温数据就是异常。结合上一章讲的数据过滤即可实现。
df
Out[1]:
城市 温度
0 北京 -5
1 上海 5
2 广州 15
3 基加利 75
# 只选择温度小于60的
df[df['温度']<60]
Out[2]:
城市 温度
0 北京 -5
1 上海 5
2 广州 154.分布异常
这是我自己定义的一个概念,类似离群点的概念。即某几个数据和整体数据距离较远。且往往这几个数据没有明显偏离经验值。所以不能通过上面的方法筛选。实现方法:针对高维数据,可以使用离群算法;针对某一维数据,可以直接使用四分位数的概念。
# 温度整体在-5℃左右,因此5℃将会被剔除
df = pd.DataFrame({'时间': ['00:00', '00:10', '00:20', '00:30', '00:40', '00:50', '01:00', '01:20'],
'温度': [-5, -6, -7, -6, -5, -4, 5, -4]})
# 上四分位数
up_q = df['温度'].quantile(0.75)
# 下四分位数
low_q = df['温度'].quantile(0.25)
# k=1.5是个经验值,根据整体数据的离散程度调节。一般范围[1.5, 3)
dis = 1.5*(up_q - low_q)
# 上边界
up_limit = up_q + dis
# 下边界
low_limit = low_q - dis
print(df[df['温度'] < up_limit][df['温度'] > low_limit])
# 输出:
时间 温度
0 00:00 -5
1 00:10 -6
2 00:20 -7
3 00:30 -6
4 00:40 -5
5 00:50 -4
7 01:20 -45.替换异常值
其实,前面讲的向前、向后填充也算是一种替换。不过,Pandas还提供了其他替换方式。
(1)通过df.replace
df
Out[1]:
商品名称 地区 销量
0 李老吉 北京 15.0
1 娃啥啥 上海 13.0
2 康帅傅 广州 28.0
3 娃啥啥 上海 NaN
# 空值替换为0
df.replace(np.nan, 0)
Out[2]:
商品名称 地区 销量
0 李老吉 北京 15.0
1 娃啥啥 上海 13.0
2 康帅傅 广州 28.0
3 娃啥啥 上海 0.0如果想对不同的异常值进行不同的替换,只需传入两个列表,替换前后元素做好对应
df
Out[1]:
商品名称 地区 销量
0 李老吉 北京 0.0
1 娃啥啥 上海 13.0
2 康帅傅 广州 28.0
3 娃啥啥 上海 NaN
# 0替换为-1;空值替换为-2
df.replace([0, np.nan], [-1, -2])
Out[2]:
商品名称 地区 销量
0 李老吉 北京 -1.0
1 娃啥啥 上海 13.0
2 康帅傅 广州 28.0
3 娃啥啥 上海 -2.0(2) 通过筛选赋值
df = pd.DataFrame({'商品名称': ['李老吉', '娃啥啥', '康帅傅', '娃啥啥'],
'地区': ['北京', '上海', '广州', '上海'],
'销量': [28, 13, 28, 99]})
# 将销量大于50的替换为50
df['销量'][df['销量']>50] = 50
df
Out[2]:
商品名称 地区 销量
0 李老吉 北京 28
1 娃啥啥 上海 13
2 康帅傅 广州 28
3 娃啥啥 上海 50
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)