torch.optim.lr_scheduler.OneCycleLR用法
代码:import cv2import torch.nn as nnimport torchfrom torchvision.models import AlexNetimport matplotlib.pyplot as plt#定义2分类网络steps = []lrs = []model = AlexNet(num_classes=2)lr = 0.9optimizer = torch.opt
·
环境:pytorch1.7
代码:
import cv2
import torch.nn as nn
import torch
from torchvision.models import AlexNet
import matplotlib.pyplot as plt
#定义2分类网络
steps = []
lrs = []
model = AlexNet(num_classes=2)
lr = 0.1
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.9)
#total_steps:总的batch数,这个参数设置后就不用设置epochs和steps_per_epoch,anneal_strategy 默认是"cos"方式,当然也可以选择"linear"
#注意这里的max_lr和你优化器中的lr并不是同一个
scheduler =torch.optim.lr_scheduler.OneCycleLR(optimizer,max_lr=0.9,total_steps=100, verbose=True)
for epoch in range(10):
for batch in range(10):
scheduler.step()
lrs.append(scheduler.get_lr()[0])
steps.append(epoch*10+batch)
plt.figure()
plt.legend()
plt.plot(steps, lrs, label='OneCycle')
plt.savefig("dd.png")
#注意,无论你optim中的lr设置是啥,最后起作用的还是max_lr图:

在目前的pytorch1.9版本中新添加了一个three_phase参数,当这个three_phase=True
scheduler =torch.optim.lr_scheduler.OneCycleLR(optimizer,total_steps=100,max_lr=0.9,three_phase=True)得到的学习率变成下图:对称+陡降


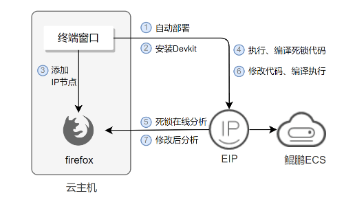
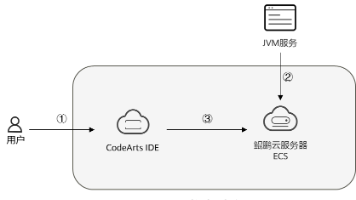
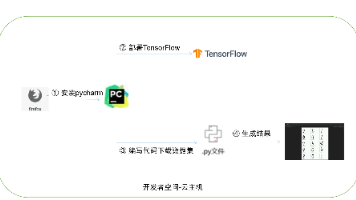
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)