关于pytorch nn.KLDivLoss()损失计算loss值为负数的原因
KL散度,又叫相对熵,用于衡量两个分布(离散分布和连续分布)之间的距离。
·
原因1:预测值和标签值都需要进行softmax归一化处理
原因2:预测值还需要再进行log计算,标签值不需要
KL散度
KL散度,又叫相对熵,用于衡量两个分布(离散分布和连续分布)之间的距离。
设 p(x) 、 q(x) 是离散随机变量X的两个概率分布,则 p 对q 的KL散度是:
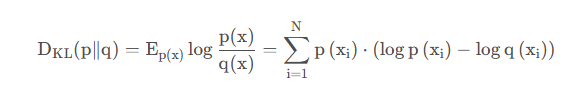
在pytorch中,nn.KLDivLoss()的计算公式如下:

上图y为标签,x为预测值,则pytorch应该以如下代码使用
lossfunc = nn.KLDivLoss()
loss = lossfunc(预测值, 标签值)
在计算公式中,预测值x的输入要是对数形式,而标签值y则不需要,所以如果我们要对预测值和标签值的softmax值求KL散度就需要如下:
temp = 1 #温度系数
probs = torch.Tensor([[2, 6, 8], [7, 1, 2], [1, 9, 2.3], [1.9, 2.8, 5.4]])
target = torch.Tensor([[0.8, 0.1, 0.1], [0.1, 0.7, 0.2], [0.5, 0.2, 0.3], [0.4, 0.3, 0.3]])
loss = lossfunc(F.log_softmax(probs / temp, dim=1), F.softmax(target / temp, dim=1))#如果probs和target已经是softmax的形式,就只需要给probs取对数输入就行了
所以,在pytorch中预测值和标签值分别做如下处理:
F.log_softmax(预测值/ temp, dim=1)
F.softmax(标签值/ temp, dim=1)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)