python爬虫基础案例——爬取猫眼电影并保存数据到excel
好久没更新博文了,最近忙于学习scrapy框架和微信小程序开发,今天看到一个自己之前写的但是中途放弃的爬虫小案例——爬取猫眼电影TOP100榜的相关数据,现在将它写好并分享给大家。爬虫的套路就是通过url发送请求,获取数据,在解析数据,最后保存数据。一、模块根据套路,选择好要使用的模块/库,这里用的模块/库是import requestsfrom lxml import etreeimport p
好久没更新博文了,最近忙于学习scrapy框架和微信小程序开发,今天看到一个自己之前写的但是中途放弃的爬虫小案例——爬取猫眼电影TOP100榜的相关数据,现在将它写好并分享给大家。
爬虫的套路就是通过url发送请求,获取数据,在解析数据,最后保存数据。
一、模块
根据套路,选择好要使用的模块/库,这里用的模块/库是
import requests
from lxml import etree
import pandas as pd二、正文
1.比较url,比较url变化规律,从而得到base_url
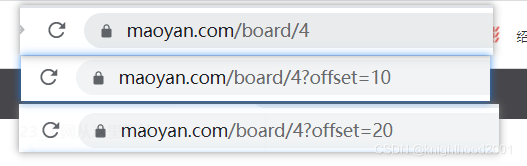
如图,根据不同的页面发现url的规律是offset的变化。因此可以得到base_url就是
https://maoyan.com/board/4?offset={},待会通过format函数构建完整的url。
2.获取headers
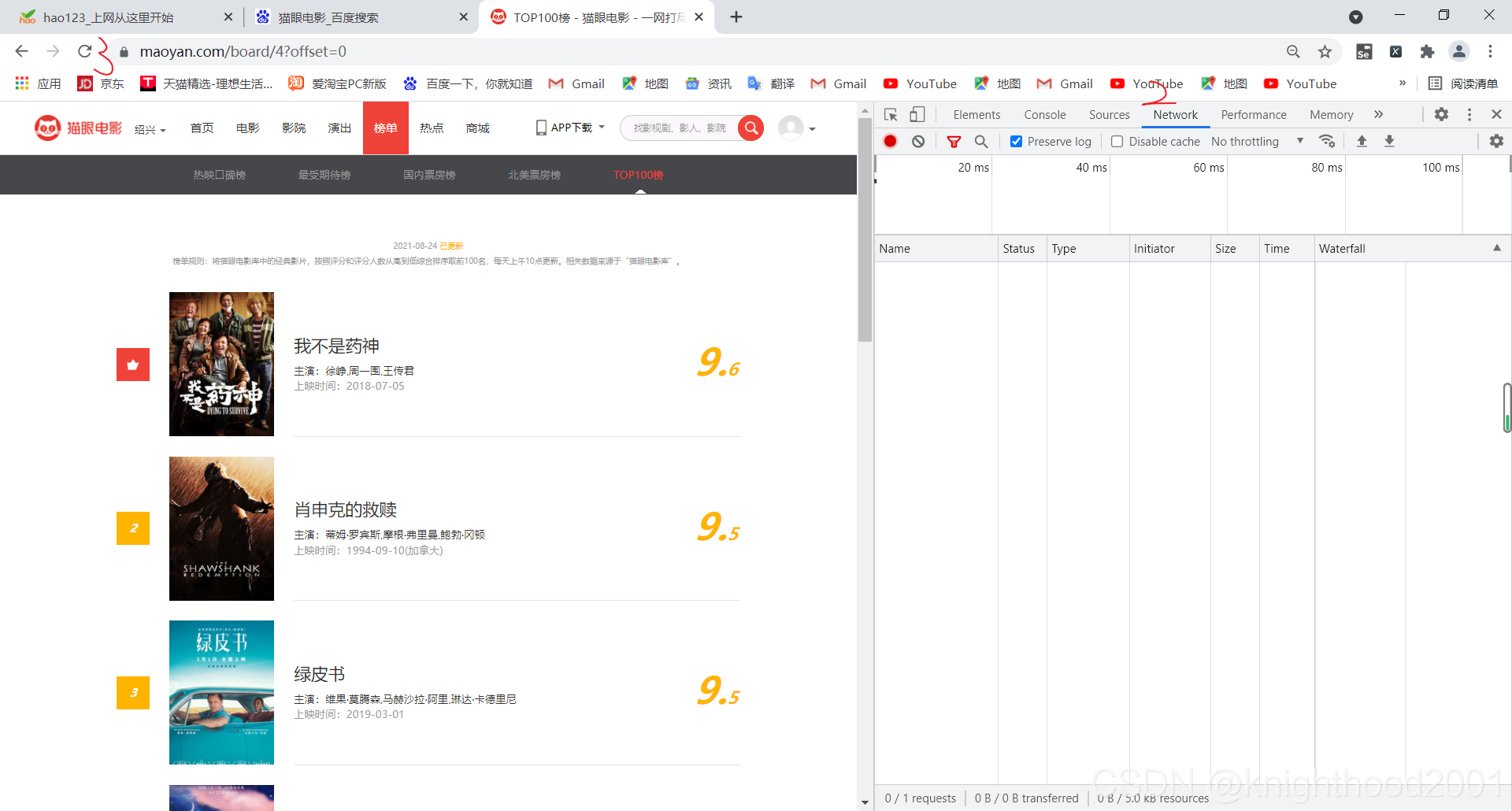
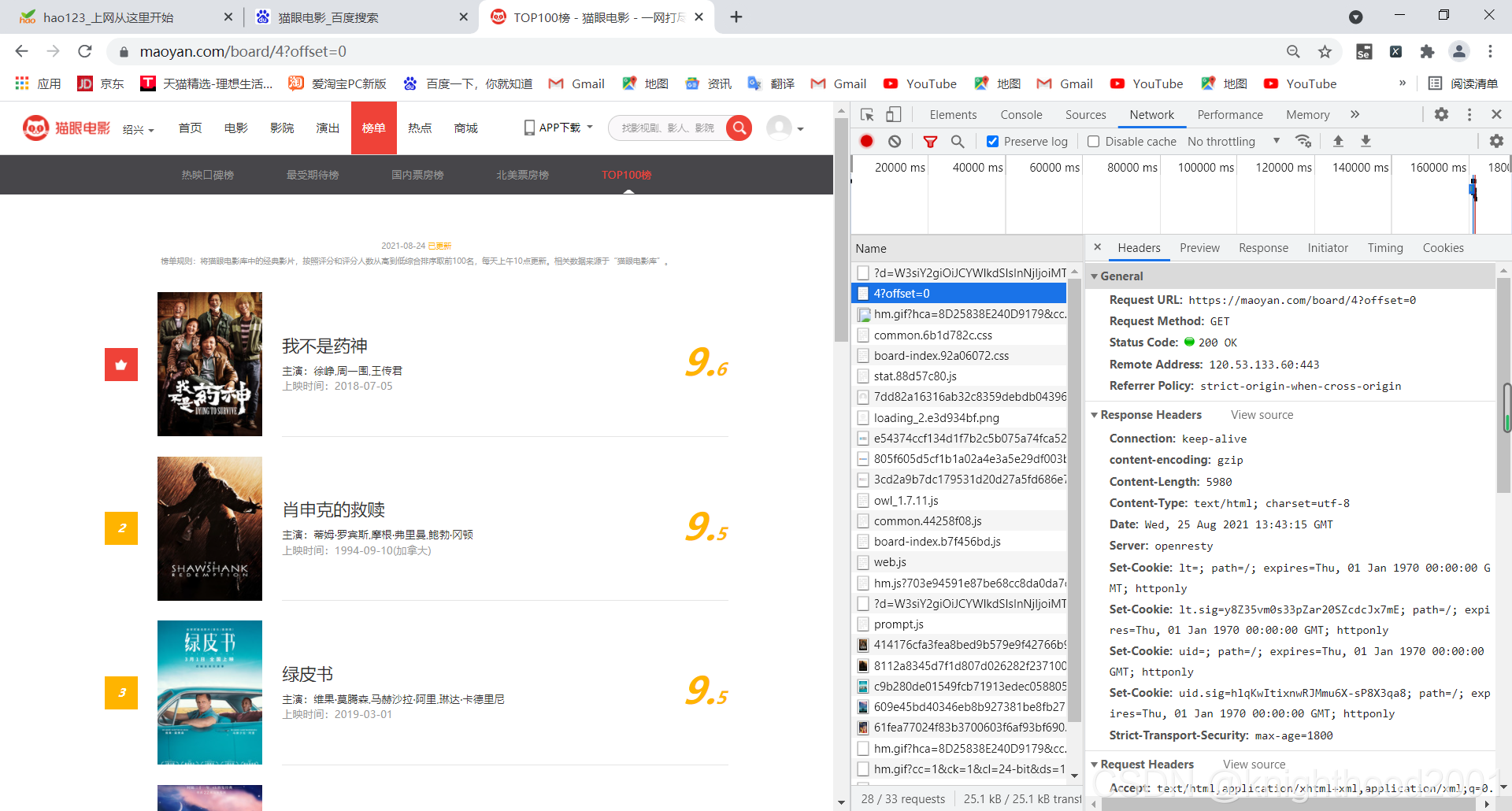
在该页面1右键检查,2点击network,3点击左上角刷新按钮,4点击图中的网址,在右边找到user-Agent,referer和cookie并组成字典形式
注:该网址可能只需要这三个中的其中一两个,可自行删除尝试是否可行。
headers = {
'Referer': 'https://maoyan.com/board/4?requestCode=e83854272b2bff27fb25137346aeb714bbj90&offset=10',
'Cookie': '__mta=247404475.1629885283786.1629887482215.1629893884124.8; uuid_n_v=v1; uuid=7868E9D0058A11ECAEE0416AA74DE6B1A0A2AC49E1604153A8082BAC6B403331; _csrf=0032460ef4cb4cbc03a01838a3100aeb3daef130e0ac4b0cd03e52ab9ff596fb; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1628220737,1628236529,1628653354,1629885284; _lxsdk_cuid=17a469fab1dc8-04e619bda8b373-3f356b-144000-17a469fab1dc8; _lxsdk=7868E9D0058A11ECAEE0416AA74DE6B1A0A2AC49E1604153A8082BAC6B403331; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1629893884; _lxsdk_s=17b7d3ef5ea-f43-47d-9b1%7C%7C3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}3.构建url,发送请求
在这里由base_url构建最终的url不止一个,所有要用到for循环,每构建一个url,就执行一次发送请求、获取数据、解析数据、保存数据。
for i in range(10):
url = base_url.format(str(i * 10))
response = requests.get(url, headers=headers)
# print(response.text)4.解析数据
这里使用的是lxml库来解析和提取HTML中的数据。
在for循环中(部分代码接上,以便更加顺畅,易懂)
response = requests.get(url, headers=headers)
# print(response.text)
html = response.text
xp = etree.HTML(html)接下来就需要用到xpath语法了,当然也可以在浏览器中直接copy xpath。
解析出网页后,我们需要获取每个电影的节点列表

从中可以发现该页面的所有电影信息都在<div class="main">...</div>中。

lis = xp.xpath('//*[@id="app"]/div/div/div[1]')这样我们就得到了电影节点列表。
接下来在电影列表中遍历每一部电影,在从每一部电影中遍历排名,片名,主演,上映时间,评分。因此需要两个for循环,
for li in lis:
for n in range(0, 10):
paiming = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/i/text()')[n]
pianming = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a/text()')[n]
zhuyan = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[2]/text()')[n].strip().replace("主演:", "")
shijian = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[3]/text()')[n].replace("上映时间:", "")这段代码需重点关注,1要获取文本内容,则需要在xpath语法最后加/text(),2如下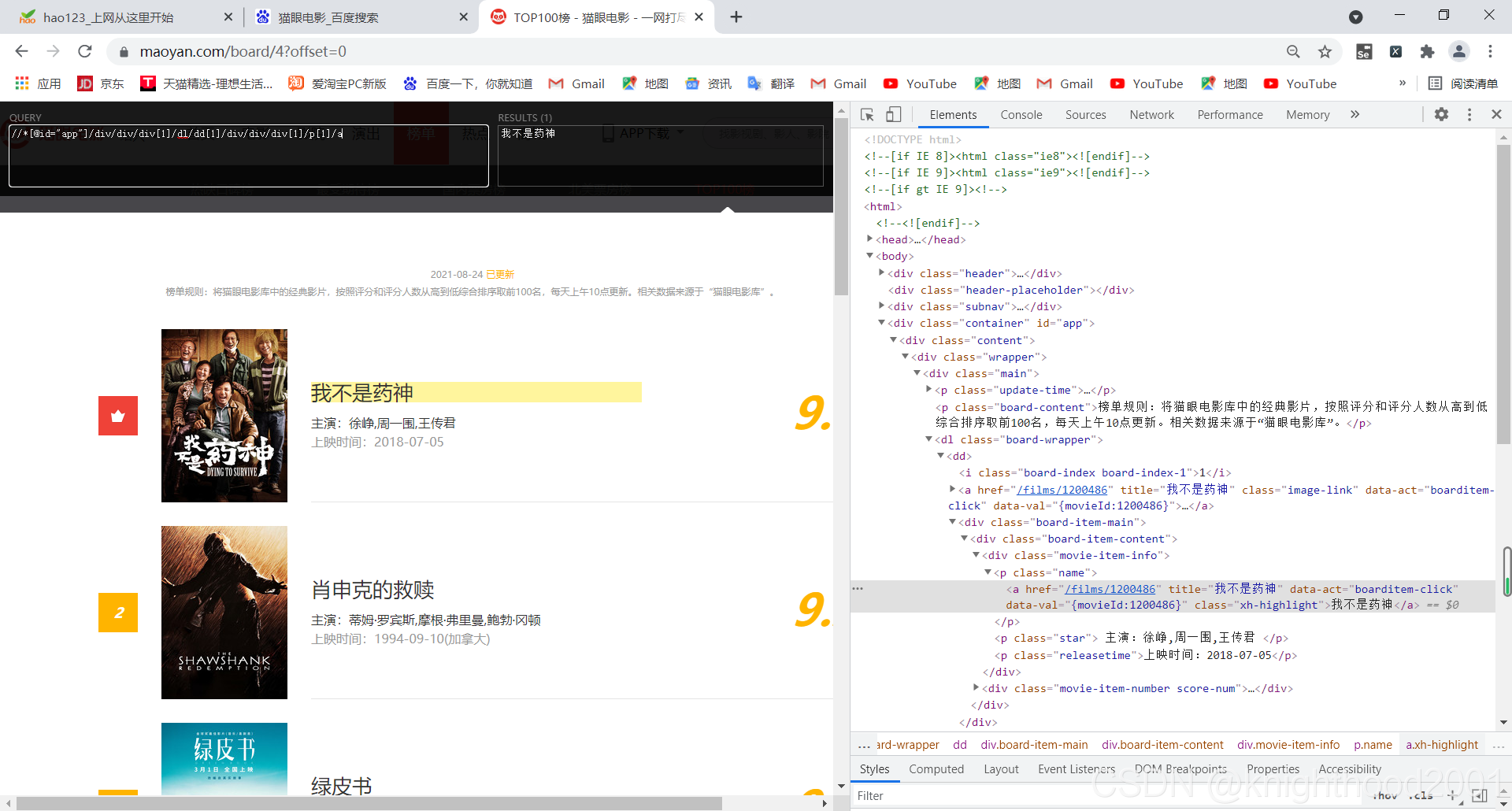
可以将xpath在浏览器中试试看,例://*[@id="app"]/div/div/div[1]/dl/dd[1]/div/div/div[1]/p[1]/a的结果为 我不是药神,分析节点,若删除dd后的[1],最终结果就是该页面所有片名,
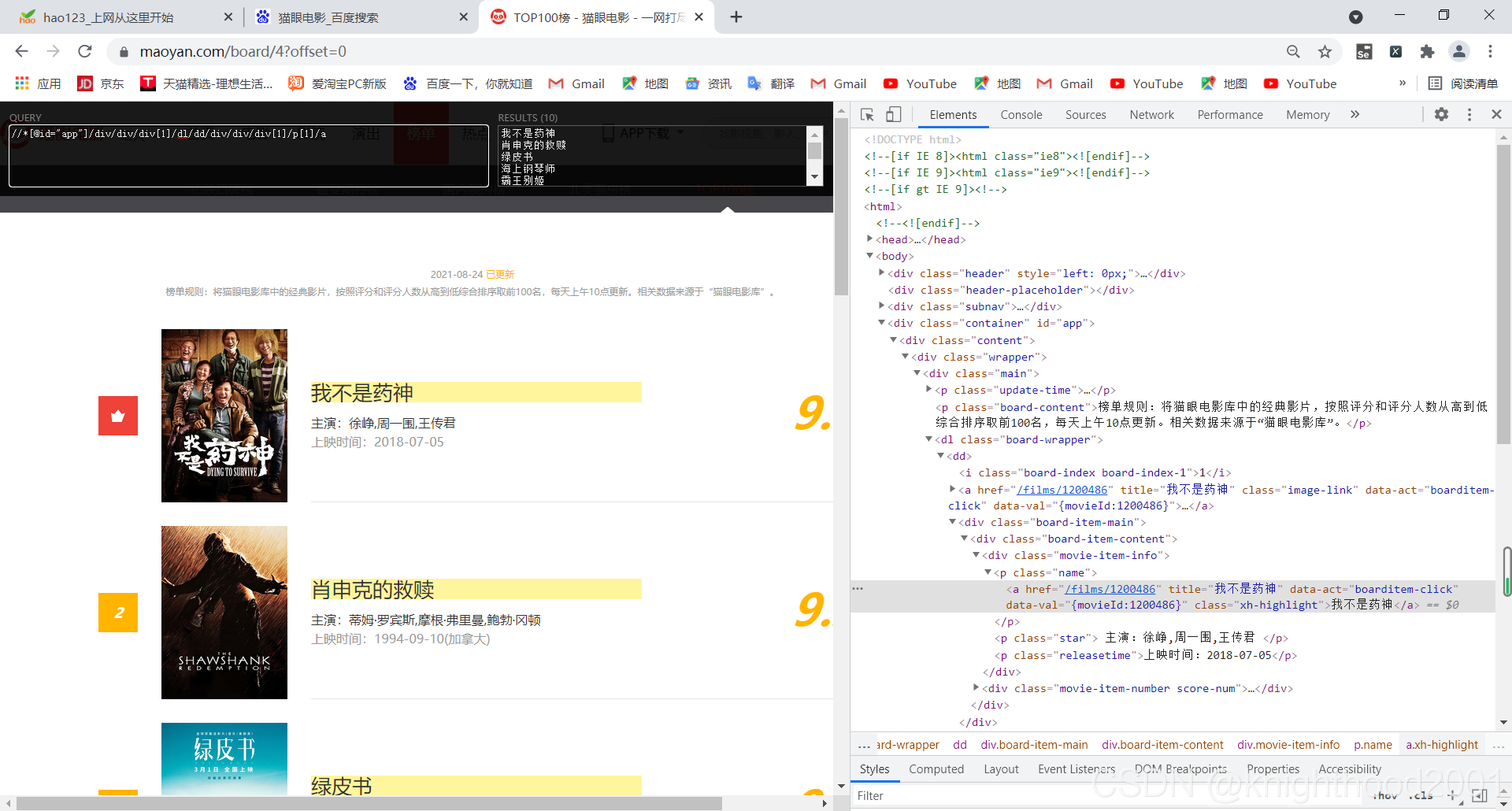 改变dd[]中的值,结果也不同,所有我们只需要dd就行,每个xpath后面的[n]表示获取第n个数据。3由于主演和上映时间爬出来的数据中有“主演:”和“上映时间:”,具有重复性,并且影响美观。因此用replace()函数将其替换为空(删除)。
改变dd[]中的值,结果也不同,所有我们只需要dd就行,每个xpath后面的[n]表示获取第n个数据。3由于主演和上映时间爬出来的数据中有“主演:”和“上映时间:”,具有重复性,并且影响美观。因此用replace()函数将其替换为空(删除)。
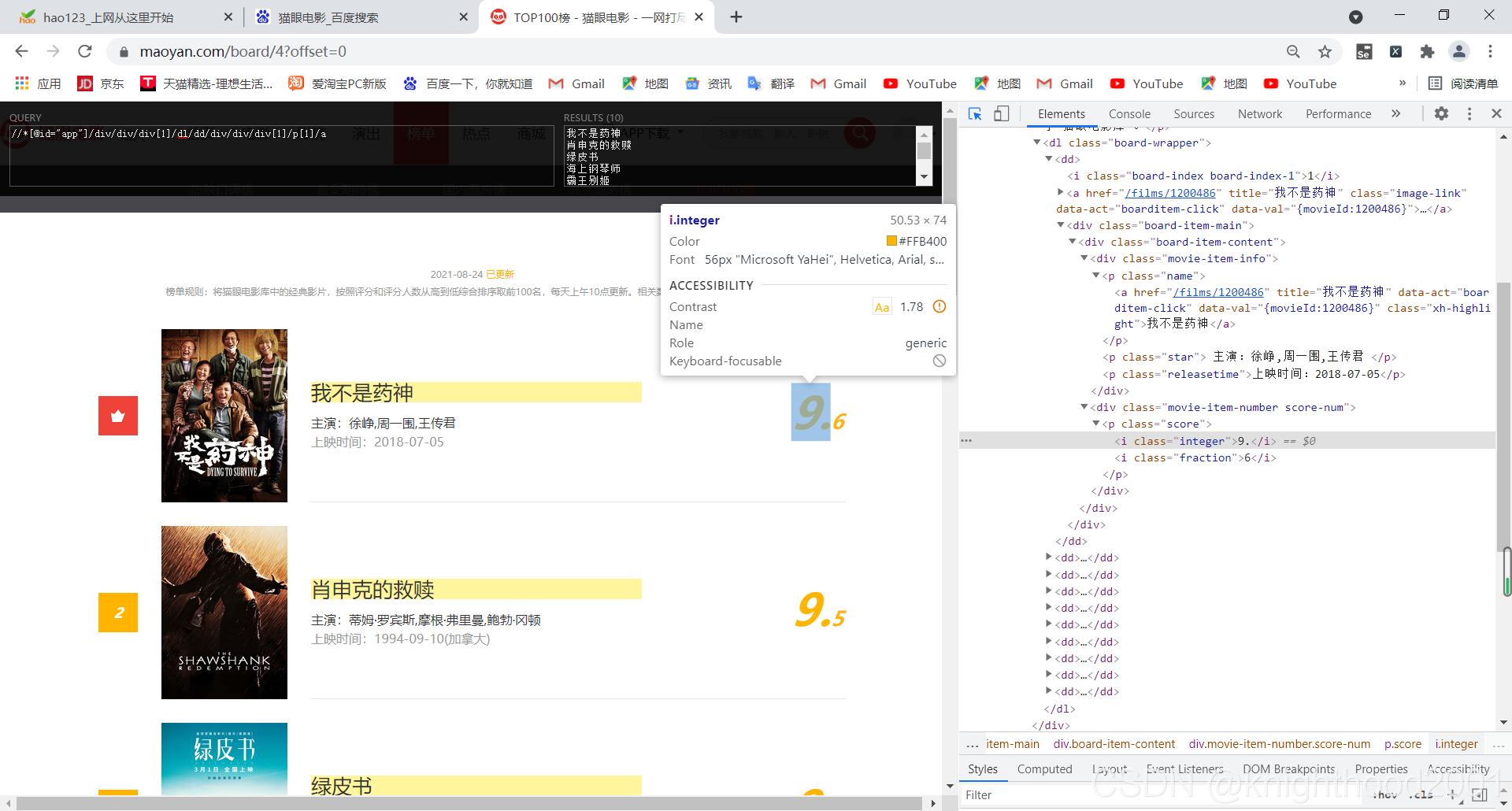
如图,由于评分被拆开了,所有要进行拼接,拼接出来的为str类型,你也可以将它转变一下类型。
# 由于分数被拆成了两个i节点,所有要分别获取并进行拼接
score1 = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[1]/text()')[n]
score2 = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[2]/text()')[n]
score = score1 + score25.保存数据到excel
df = []
columns = ['排名', '片名', '主演', '上映时间', '评分']
b = df.append([paiming, pianming, zhuyan, shijian, score])
# dataframe是二维数组,columns将上面的标题行插入到二维数组中
d = pd.DataFrame(df, columns=columns)
# index=False表示输出不显示索引值
d.to_excel("猫眼电影.xlsx", index=False)这其实是一个模板,首先定义一个空的列表,然后将解析的数据以列表形式添加,接着dataframe表示二维数组,将这些数据以二维数组形式保存。
三、所有代码及结果展示
import requests
from lxml import etree
import pandas as pd
df = []
# 注:猫眼电影有时要滑块验证,所以print打印出来为猫眼验证中心,要先登录网址通过滑块验证
base_url = 'https://maoyan.com/board/4?offset={}'
headers = {
'Referer': 'https://maoyan.com/board/4?requestCode=e83854272b2bff27fb25137346aeb714bbj90&offset=10',
'Cookie': '__mta=247404475.1629885283786.1629887482215.1629893884124.8; uuid_n_v=v1; uuid=7868E9D0058A11ECAEE0416AA74DE6B1A0A2AC49E1604153A8082BAC6B403331; _csrf=0032460ef4cb4cbc03a01838a3100aeb3daef130e0ac4b0cd03e52ab9ff596fb; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1628220737,1628236529,1628653354,1629885284; _lxsdk_cuid=17a469fab1dc8-04e619bda8b373-3f356b-144000-17a469fab1dc8; _lxsdk=7868E9D0058A11ECAEE0416AA74DE6B1A0A2AC49E1604153A8082BAC6B403331; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1629893884; _lxsdk_s=17b7d3ef5ea-f43-47d-9b1%7C%7C3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
columns = ['排名', '片名', '主演', '上映时间', '评分']
for i in range(10):
url = base_url.format(str(i * 10))
response = requests.get(url, headers=headers)
print(response.text)
html = response.text
xp = etree.HTML(html)
# print(xp)
lis = xp.xpath('//*[@id="app"]/div/div/div[1]')
# print(lis)
for li in lis:
for n in range(0, 10):
paiming = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/i/text()')[n]
pianming = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[1]/a/text()')[n]
zhuyan = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[2]/text()')[n].strip().replace("主演:", "")
shijian = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[1]/p[3]/text()')[n].replace("上映时间:", "")
# 由于评分被拆成了两个i节点,所有要分别获取并进行拼接
score1 = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[1]/text()')[n]
score2 = li.xpath('//*[@id="app"]/div/div/div[1]/dl/dd/div/div/div[2]/p/i[2]/text()')[n]
score = score1 + score2
b = df.append([paiming, pianming, zhuyan, shijian, score])
# dataframe是二维数组,columns将上面的标题行插入到二维数组中
d = pd.DataFrame(df, columns=columns)
# index=False表示输出不显示索引值
d.to_excel("猫眼电影.xlsx", index=False)
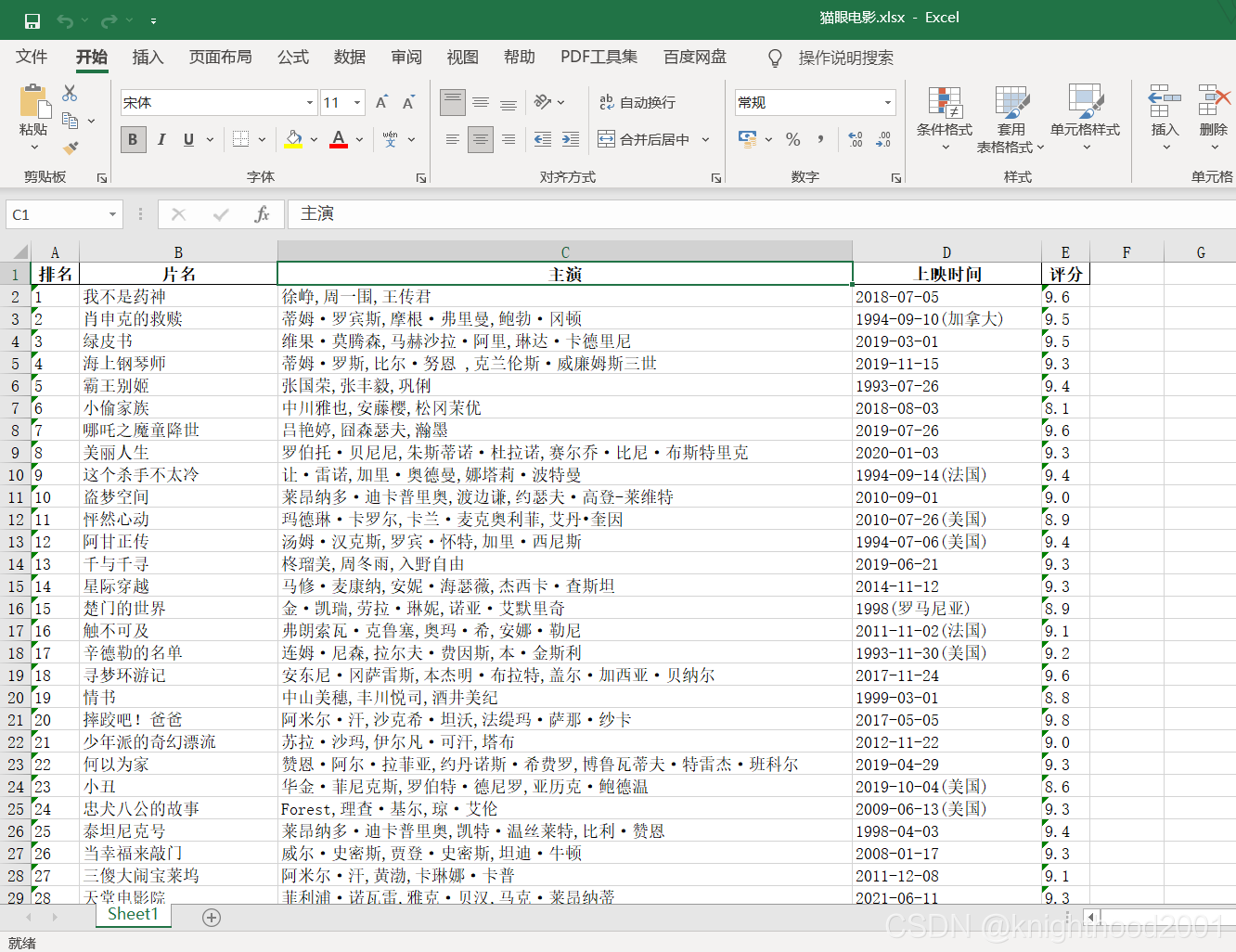
四、总结
这个爬虫案例是今天刚发现之前还没完成的,所有就将它完成了,难点应该就在xpath那块。
这也给我们一个启发:当时做不出的案例可以先放一放,到后面再会过去写完程序,但是要记得不要忘记之前没写出来的案例!!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 15
15 1
1- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)