Tensor及基本数据操作
在Pytorch中torch.Tensor是存储和变换数据的主要工具,Tensor一般译作张量,可以看做是一个多维数组。标量可以看作0维张量,向量可以看做1维张量,矩阵可以看做2维张量。Pytorch中函数的操作对象基本都是Tensor。根据存储类型的不同有FloatTensor(32位)和LongTensor(64位)。一、基本函数:1.查看Pytorch的版本:import torchprin
在Pytorch中torch.Tensor是存储和变换数据的主要工具,Tensor一般译作张量,可以看做是一个多维数组。标量可以看作0维张量,向量可以看做1维张量,矩阵可以看做2维张量。Pytorch中函数的操作对象基本都是Tensor。根据存储类型的不同有FloatTensor(32位)和LongTensor(64位)。
一、基本函数:1.查看Pytorch的版本:
import torch
print(torch.__version__)
![]()
创建一个随机未初始化的5x3的Tensor:
import torch
x=torch.empty(5,3)
print(x)
print(type(x))
创建一个5x3随机初始化的Tensor:
import torch
b=torch.rand(5,3)
print(b)
torch.randn(5,3)是随机初始化的服从正态分布的Tensor: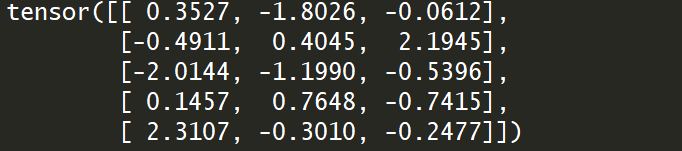
2.创建一个5x3全0的Tensor:
import torch
y=torch.zeros(5,3,dtype=torch.long)
print(y)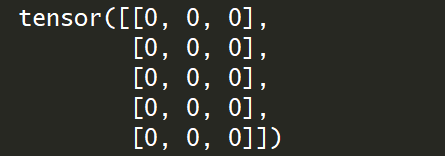
创建一个2x3的全1型的float型的Tensor:
import torch
z=torch.ones(2,3,dtype=torch.float)
print(z)
3. 创建一个主对角线为1,其余元素全为0的Tensor:
import torch
w=torch.eye(5,3)
4.创建一个从0到5步长为1的Tensor:
import torch
w=torch.arange(0,5,1)
print(w) 
5.创建一个从0到5均匀分成4份的Tensor:
import torch
a=torch.linspace(0,5,4)
print(a)![]()
关于torch.empty()和torch.Tensor()的区别:
empty()返回一个不含初始化数据的Tensor,使用参数可以指定形状、类型等。而Tensor()算是empty()的一个特例,如torch.FloatTensor()返回的是一个未初始化的float型的Tensor。
二、基本运算:
1.加法操作:
import torch
x=torch.Tensor([1,1])
y=torch.Tensor([2,2])
print(x+y)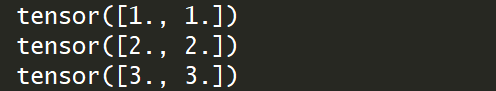
还可以使用torch.add(x,y)进行两个Tensor的相加,此时两个相加的Tensor必须是相同形状的。
2.索引操作:
创建一个3x5的Tensor
import torch
z=torch.rand(3,5)
print(z)
可以通过z.size()或z.shape获取Tensor的形状:
print(z.size()) print(z.shape)

(1)取第一行:
print(z[0])#第1行
![]()
(2)取第1列:
print(z[:,0])#第1列
![]()
(3)取第1行第2个元素:
print(z[0][1])等价于print(z[0,1])
![]()
(4)取前2行,第0,1列元素:
print(z[:2,:2])#前2行第0,1两列元素

(5)以下两个形状不同:
print(z[0:1,:2])#tensor([[0.8497, 0.8785]]),第1行前两列 print(z[0,:2])#tensor([0.8497, 0.8785]),二者形状不同

(6)print(z<1)

使用索引操作须注意索引出来的结果与原数据共享内存,修改一个另一个也会随之改变。
b=torch.ones(3,3)
print(b)
c_index=b[0,:]#取第1行的所有元素
print("索引出来的结果",c_index)
c_index+=1
print("索引出来的结果作加法结果是:",c_index)
print("原Tensor为:",b[0,:])

view()来重构Tensor的维度:
import torch
a=torch.ones(3,5)
b=a.view(5,3)#将一个3x5的Tensor变成5x3的Tensor
print(a)
print(b)

view(-1,5)中的-1是什么意思:以上面的Tensor为例,3x5总共长度为15,-1就是让计算机自己计算15/5=3,则变成3x5的Tensor。
b=torch.ones(3,5)
print(b)
y=b.view(-1,3)
print(y)
view()返回的Tensor和原传入的Tensor共享内存,即修改一个另一个也会改变。
Numpy和Tensor的互相转化:numpy()和from_numpy()将二者互相转化,并且共享内存
1.将numpy转化为Tensor:
import torch as t
import numpy as np
#将numpy的ndArray转换为tensor,相当于重新复制了一份
a=np.ones(5)
x_copy=t.from_numpy(a)
print(a,x_copy)
a+=1
print(a,x_copy)
x_copy+=1
print(a,x_copy)

2.将Tensor转化为numpy:
#将Tensor数组转换为numpy
b=t.ones(5)
y_copy=b.numpy()
print(b,y_copy)
b+=1
print(b,y_copy)
y_copy+=1
print(b,y_copy)

3.
'''
Tensor数据的存储:
.data:存储数据
.grad:存储梯度
'''
import torch
z_float=torch.FloatTensor([2,2])
print(z_float)#默认返回的就是.data类型的数据
print(z_float.grad)#grad目前还没有
x=torch.Tensor([1,])#只能有一个
print(x)
print(x.item())#item()函数将一个Tensor变成python中float类型的数字
print(type(x.item()))
4.广播机制:先适当复制元素使这两个Tensor相同后再按元素进行运算。
import torch
#广播机制:先适当复制元素使这两个Tensor相同后再按元素进行运算
x=torch.arange(1,3).view(1,2)
print(x)#x是一个1行2列的矩阵
y=torch.arange(1,4).view(3,1)
print(y)#y是一个3行1列的矩阵
'''
由于x和y不是同型的,需要将x中第1行的2个元素(广播)复制到第2行和第3行,
而y中第1列的3个元素被复制到了第2列,如此就可对2个3行2列的矩阵按元素相加计算。
'''
print(x+y)
5.运算的内存开销:
索引和view是不会开辟内存的,但是像b=a+b这种运算是会开辟新的内存的。
import torch
a=torch.tensor([1,2])
b=torch.tensor([3,4])
print(id(b))
b=b+a
print(id(b))

如果想要b指定到原来的内存,可以使用索引:
a=torch.tensor([1,2])
b=torch.tensor([3,4])
print(id(b))
b[:]=b+a
print(id(b))


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)