Python 3sigma检测异常数据
前言3sigma:又称为拉依达准则数据需要服从正态分布。在3sigma原则下,异常值如超过3倍标准差,那么可以将其视为异常值。3σ原则为数值分布在(μ-σ,μ+σ)中的概率为0.6827数值分布在(μ-2σ,μ+2σ)中的概率为0.9545数值分布在(μ-3σ,μ+3σ)中的概率为0.9973取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到0.3%.实例采用3sigma
·
前言
3sigma:又称为拉依达准则
数据需要服从正态分布。在3sigma原则下,异常值如超过3倍标准差,那么可以将其视为异常值。
3σ原则为
数值分布在(μ-σ,μ+σ)中的概率为0.6827
数值分布在(μ-2σ,μ+2σ)中的概率为0.9545
数值分布在(μ-3σ,μ+3σ)中的概率为0.9973
取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到0.3%.
实例
采用3sigma对数据进行异常检测分析。
私聊数据集。
链接: https://pan.baidu.com/s/1eOt6eKtVuhThOamB5QQsnQ
提取码: 178j
#基于3sigma的异常值检测
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt #导入绘图库
n = 3 # n*sigma
catering_sale = r'catering_sale.xls' #数据路径
data = pd.read_excel(r'sale.xls', index_col = False) #读取数据
data_y = data[u'销量']
data_x = data[u'日期']
def three_sigma(df_col):
"""
df_col:DataFrame数据的某一列
"""
rule = (df_col.mean() - 3 * df_col.std() > df_col) | (df_col.mean() + 3 * df_col.std() < df_col)
index = np.arange(df_col.shape[0])[rule]
outrange = df_col.iloc[index]
return outrange
# data[u'销量'] = data['销量'].apply(lambda x: np.log(x))
index_ = three_sigma(data[u'销量']).index
print('\n异常数据如下:\n')
# data[u'销量'] = data['销量'].apply(lambda x: np.exp(x))
data.iloc[index_]
日期 销量 利润
0 2015-03-01 51.00 420.00
8 2015-02-21 6607.40 450.00
103 2014-11-08 22.00 1800.00
110 2014-11-01 60.00 60.00
144 2014-09-27 9106.44 9106.44
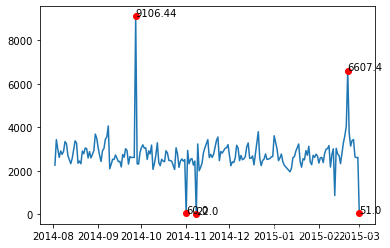
plt.plot(data[u'日期'], data[u'销量'])
plt.plot(data.iloc[index_][u'日期'], data.iloc[index_][u'销量'], 'ro')
outlier = list(data.iloc[index_][u'销量'])
outlier_x =list( data.iloc[index_][u'日期'])
for j in range(len(outlier)):
plt.annotate(outlier[j], xy=(outlier_x[j], outlier[j]), xytext=(outlier_x[j],outlier[j]))
plt.show()
总结
- 3sigma一般适用于正态分布数据或者近似正态分布
- 3也可以换成4或者5,在实际应用中可以根据业务场景来确定 k sigma中的k值

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)