【python】pandas对于数据的处理——插入、删除、空值重复值处理等
pandas常见的对数据的处理有:插入、删除、空值查找/填充、重复值删除、排序、筛选等
概览:
pandas常见的对数据的处理有:插入、删除、空值查找/填充、重复值删除、排序、筛选等
常用的函数:
insert() ----插入
drop() ----删除
isnull() ----查找空值
fillna() ----空值填充
drop_duplicates() ----删除重复值
sort_values() ----排序
1、插入
pandas没有专门的插入行的方法,所以插入数据一般指的是插入一列,有两种方式,一种是直接设置一列,这种情况下是在最右侧加入一列,另一种是用insert()在指定位置插入一列
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
dt['品牌']=['AA','BB','CC','DD','EE','FF','GG']
print(dt)
dt1=pd.read_excel('产品统计表.xlsx',sheet_name=0)
dt1.insert(1,'品牌',['AA','BB','CC','DD','EE','FF','GG'])
print(dt1)
运行结果:

2、删除数据
drop()可以通过设置axis变量,删除指定的行或列
删除列代码示例
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
print(dt)
dt=dt.drop(dt.columns[[1,3]],axis=1) #删除第2、4列
dt=dt.drop(columns=['收入(元)'],axis=1) #删除'收入(元)'列
print(dt)
运行结果

删除行代码示例:
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0,index_col=0)
print(dt)
dt=dt.drop(dt.index[[0,3]],axis=0) #删除第1、4行
dt=dt.drop(index=['a007'],axis=0) #删除'a007'列,需要在打开excel时设置用哪一列做索引
print(dt)
运行结果
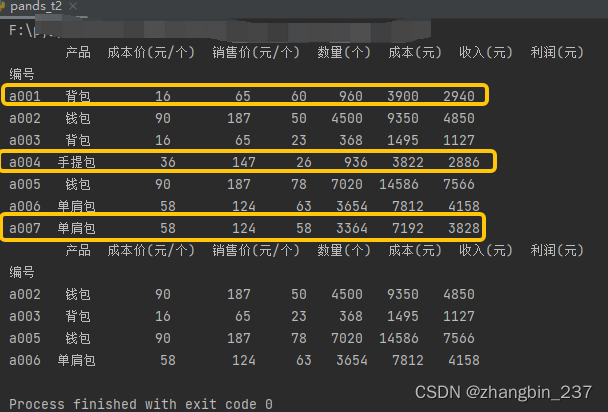
3、空值处理
查找空值用isnull():
import pandas as pd
dt=pd.read_excel('产品统计表1.xlsx',sheet_name=0)
print(dt)
print(dt.isnull())
执行结果:

删除空值有两种情况,一种是有空值就删掉这一整行,还有一种是整行全都是空值才删除
import pandas as pd
dt=pd.read_excel('产品统计表1.xlsx',sheet_name=0)
b=dt.dropna()
print(b)
c=dt.dropna(how='all')
print(c)
执行结果:

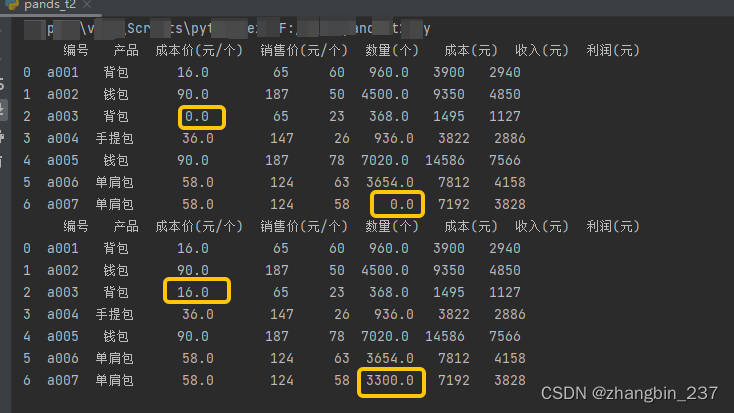
空值填充,fillna():
import pandas as pd
dt=pd.read_excel('产品统计表1.xlsx',sheet_name=0)
b=dt.fillna(0)
print(b)
c=dt.fillna({'成本价(元/个)':16,'成本(元)':3300})
print(c)
执行结果:
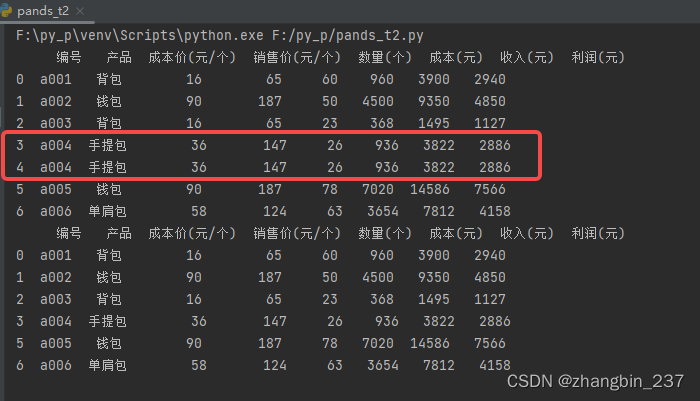
4、重复值处理
删除重复行,最基础的情况下,是两行的值都完全一样的时候才会删除重复值:
import pandas as pd
dt=pd.read_excel('产品统计表2.xlsx',sheet_name=0)
print(dt)
b=dt.drop_duplicates()
print(b)执行结果:
还可以按照某一列的值进行重复值查找、删除:
import pandas as pd
dt=pd.read_excel('产品统计表2.xlsx',sheet_name=0)
print(dt)
b=dt.drop_duplicates(subset='产品',keep='first') #保留重复值的第一个出现的所在行
print(b)
c=dt.drop_duplicates(subset='产品',keep='last') #保留重复值的最后一个出现的所在行
print(c)执行结果:

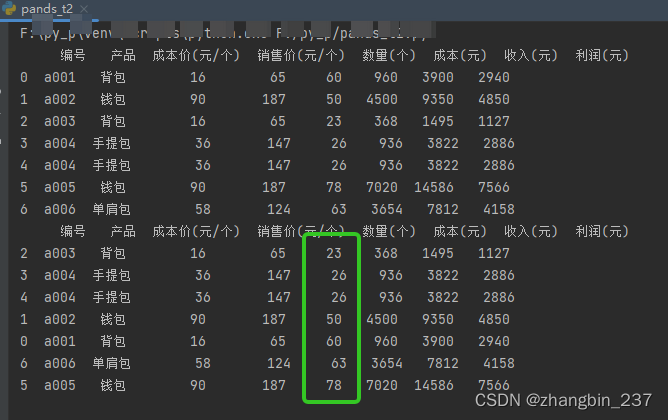
获取某一列的唯一值
import pandas as pd
dt=pd.read_excel('产品统计表2.xlsx',sheet_name=0)
print(dt)
f=dt['产品'].unique()
print(f)
5、排序
用sort_values()排序
import pandas as pd
dt=pd.read_excel('产品统计表2.xlsx',sheet_name=0)
print(dt)
f=dt.sort_values(by='数量(个)',ascending=True) #ascending=False时为倒序排序
print(f)
用rank()获取数据的排序值
import pandas as pd
dt=pd.read_excel('产品统计表2.xlsx',sheet_name=0)
print(dt)
print('---------------')
f=dt['利润(元)'].rank(method='average',ascending=False) #ascending=False时为倒序排序
#method='first'时,如果有重复数据,越早出现的数据排名越靠前
print(f)

6、筛选数据
主要是用'==' 、'>'、'<'
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
print(dt)
print('---------------')
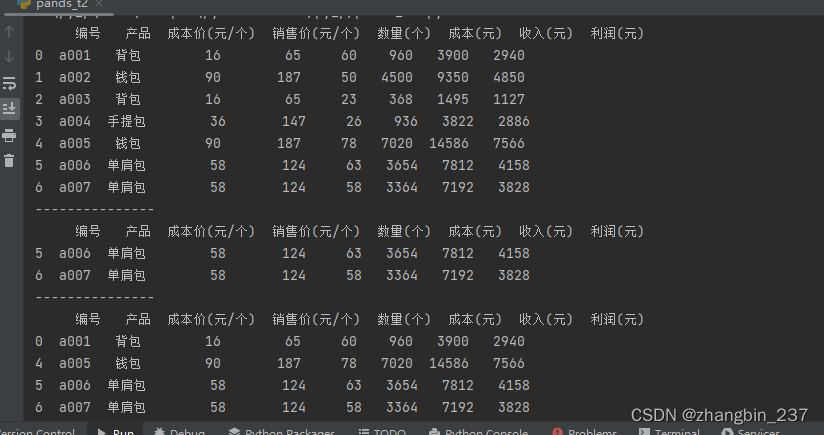
a=dt[dt['产品']=='单肩包']
print(a)
print('---------------')
b=dt[dt['数量(个)']>50]
print(b)
如果是多个筛选条件,用'&'连起来
import pandas as pd
dt=pd.read_excel('产品统计表.xlsx',sheet_name=0)
#print(dt)
print('---------------')
a=dt[dt['产品']=='单肩包']
print(a)
print('---------------')
b=dt[dt['数量(个)']>50]
print(b)
print('---------------')
c=dt[(dt['产品']=='单肩包')&(dt['数量(个)']>60)]
print(c)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)