【Pandas库】(4) 索引操作--重新生成索引
各位同学好,今天和大家分享一下pandas库的索引操作--重新生成索引。本文主要介绍如何重新生成Series类型和DataFrame类型的索引。(1)Series类型重新生成索引方法:变量 = Series名.reindex([索引名])采用该方法需要使用一个变量来接收返回值。重新生成索引的方法不会直接修改原数据,需要有一个变量来接收修改后的结果。如下代码,由于在定义Series类型数据时,ps1
各位同学好,今天和大家分享一下pandas库的索引操作--重新生成索引。
本文主要介绍如何重新生成Series类型和DataFrame类型的索引。
(1)Series类型重新生成索引
方法: 变量 = Series名.reindex([索引名])
采用该方法需要使用一个变量来接收返回值。重新生成索引的方法不会直接修改原数据,需要有一个变量来接收修改后的结果。
如下代码,由于在定义Series类型数据时,ps1中没有出现索引名'f',因此在重新生成索引时,添加的索引'f'对应的值是nan。
import pandas as pd #导入pandas库
# 生成一个Series数据,指定索引名
ps1 = pd.Series(range(1,6),index=['a','b','c','d','e'])
# 对ps1的索引名重新索引
ps2 = ps1.reindex(['e','d','c','b','a','f'])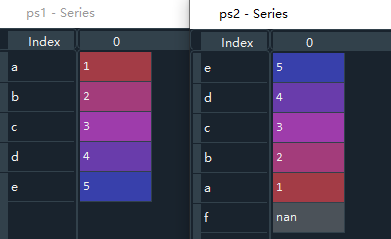
为了便于大家理解重新索引的方法,我再举个例子。
首先定义了一个元素从1到5的Series类型数据ps1,ps1的默认索引是数值类型的0、1、2...。索引重新生成时,'a'、'b'、'c'...等索引均没在ps1中出现,因此ps2接收的重新索引结果都为nan空值。要注意的是,ps3接收的结果也是nan空值,是因为重新索引时的'0'、'1'、'2'...都是字符串类型,而ps1中的索引是数值型的0、1、2...,这个不要混淆,一定要注意索引名。
import pandas as pd #导入pandas库
ps1 = pd.Series(range(1,6)) # 生成一个元素为1到5的Series类型数据
# 由于ps1中索引名没有出现过a,b,c...,因此ps3都是nan
ps2 = ps1.reindex(["a","b","c","d","e",'f'])
# ps1中的索引是数值类型的0、1、2...,重新索引时""
ps3 = ps1.reindex(["0","1","2","3","4"])
# ps4 更改正确
ps4 = ps1.reindex([4,3,2,1,0])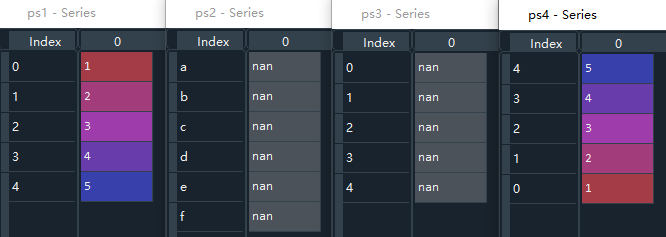
(2)DataFrame类型重新生成索引
重新生成行索引: 新变量 = 变量名.reindex([行索引名])
重新生成列索引: 新变量 = 变量名.reindex(columns=[列索引名])
首先讨论一下重新生成行索引,重新定义行索引不会直接修改原值,需要有一个新的变量来接收更改后的数据。我定义了一个DataFrame类型数据,命名pd1,它的行索引为'a','b','c',列索引为"A","B","C"。重新指定行索引,pd2多指定了一个'd'索引,然而'd'并没有在pd1中出现,因此'd'索引对应的值也是nan空值。pd3实现了重新指定行索引,索引对应的值也一起换了位置。
import pandas as pd
import numpy as np
# 使用np库生成1、2、...、9共九个数,使用reshape(行数,列数)函数,使它变成三行三列
pd1 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
pd2 = pd1.reindex(['a','b','c','d']) #多指定一行,对应行对象是nan
pd3 = pd1.reindex(["c","b","a"]) #行互换位置
我们再来看一下重新定义列索引,重新定义列索引不会直接修改原值,需要有一个新的变量来接收更改后的数据。我仍使用上面定义的pd1数据,pd4成功交换了列的索引位置,然而在pd5中,我多指定了一个列索引'D',这个索引没有在pd1中出现过,因此在重新索引后的结果中,'D'列的值都是nan空值。
import pandas as pd
import numpy as np
# 使用np库生成1、2、...、9共九个数,使用reshape(行数,列数)函数,使它变成三行三列
pd1 = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
pd4 = pd1.reindex(columns=["C","B","A"]) #列交换位置
pd5 = pd1.reindex(columns=["A","B","C","D"]) #多添加一列


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)