jieba分词词性标注含义
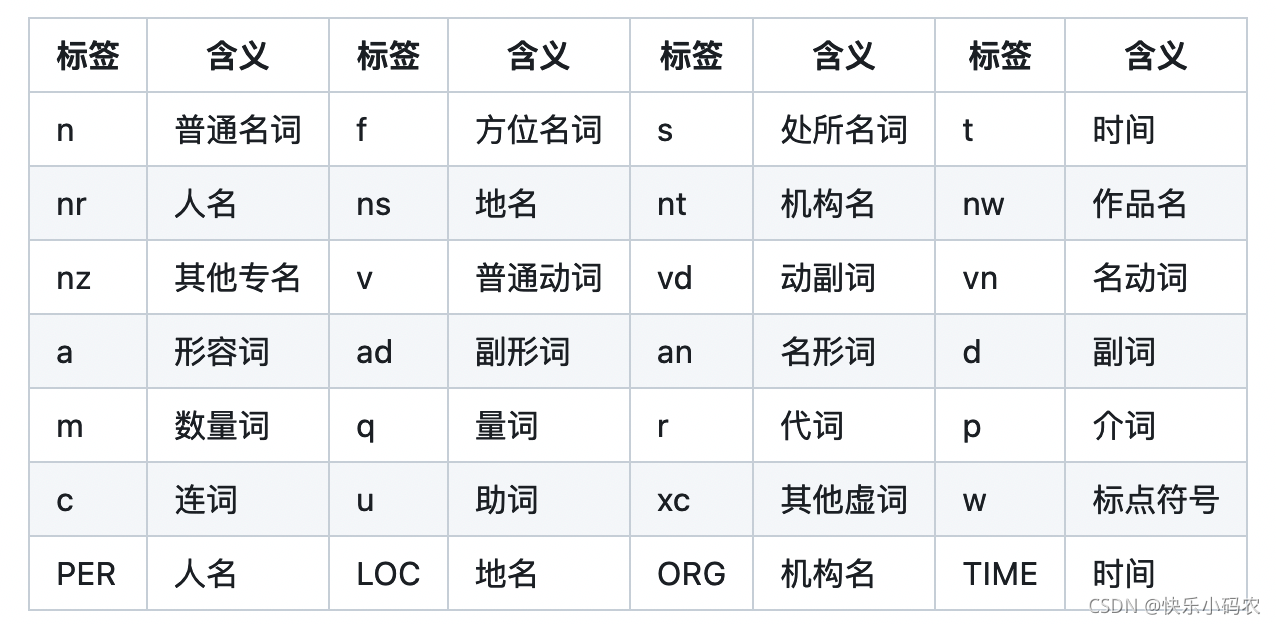
结巴分词的词性标注默认模式是使用jieba.posseg.cut(),包括24个词性标签(小写字母)。paddle模式多了4个专名类别标签(大写字母)。jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。标注句子分
·
结巴分词的词性标注
默认模式是使用jieba.posseg.cut(),包括24个词性标签(小写字母)。
paddle模式多了4个专名类别标签(大写字母)。
jieba.posseg.POSTokenizer(tokenizer=None)新建自定义分词器,tokenizer 参数可指定内部使用的jieba.Tokenizer分词器。jieba.posseg.dt为默认词性标注分词器。- 标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
- 除了jieba默认分词模式,提供paddle模式下的词性标注功能。paddle模式采用延迟加载方式,通过
enable_paddle()安装paddlepaddle-tiny,并且import相关代码; - 用法示例
>>> import jieba
>>> import jieba.posseg as pseg
>>> words = pseg.cut("我爱北京天安门") #jieba默认模式
>>> jieba.enable_paddle() #启动paddle模式. 0.40版之后开始支持,早期版本不支持
>>> words = pseg.cut("我爱北京天安门",use_paddle=True) #paddle模式
>>> for word, flag in words:
... print('%s %s' % (word, flag))
...
我 r
爱 v
北京 ns
天安门 ns
欢迎各位关注我的个人公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)