特征点检测(Landmark detection)
来源:Coursera吴恩达深度学习课程目标定位(Object localization)中介绍了其中一种思路,这里介绍另一种思路。神经网络也可以通过输出图片上特征点(landmark)的(x,y)坐标来实现对目标特征的识别,下面看几个例子。假设你正在构建一个人脸识别应用(face recognition application),你希望算法可以给出眼角的具体位置。眼角坐标为(x,y),让神经网络
来源:Coursera吴恩达深度学习课程
目标定位(Object localization)中介绍了其中一种思路,这里介绍另一种思路。神经网络也可以通过输出图片上特征点(landmark)的(x,y)坐标来实现对目标特征的识别,下面看几个例子。
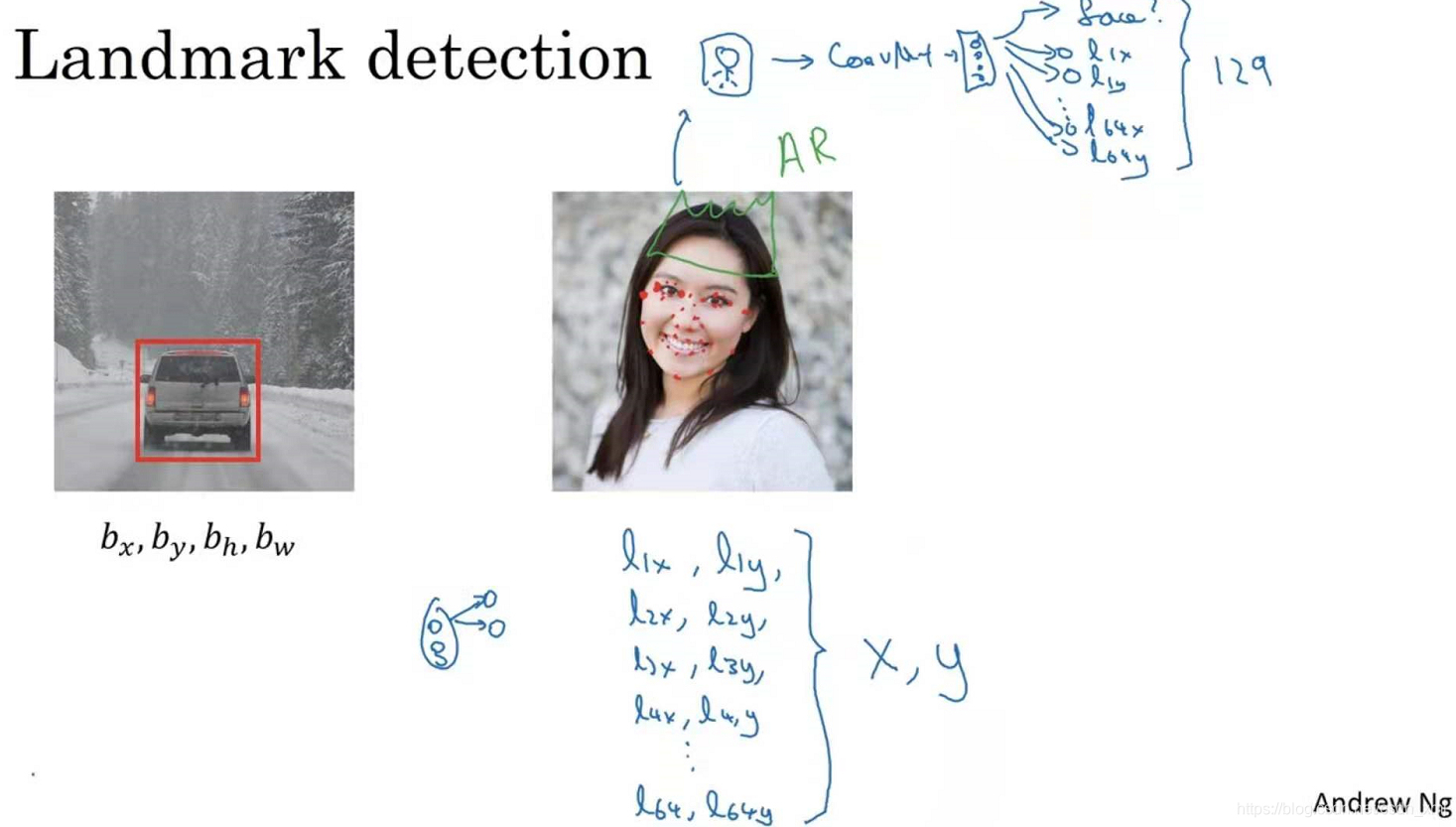
假设你正在构建一个人脸识别应用(face recognition application),你希望算法可以给出眼角的具体位置。眼角坐标为(x,y),让神经网络的最后一层多输出两个数字l_x和l_y,最为眼角的坐标值。如果你想知道两只眼睛的四个眼角的具体位置,那么依次用四个特征点来表示从左到右的四个眼角,例如第一个特征点(l_1x,l_1y),第二个特征点(l_2x,l_2y)等。
同样你也可以根据嘴部的关键点输出值来确定嘴的形状,也可以提取鼻子周围得到关键特征点。假设脸部有64个特征点(landmarks),有些点甚至可以定义脸部轮廓(define the edge of the face)或下颌轮廓(define the jawline)。选定特征点个数,并生成包含这些特征点的标签训练集(label training set),然后利用神经网络输出脸部关键特征点的位置。
具体做法是,准备一个卷积网络和一些特征集,将人脸图片输入卷积网络,输出1或0,1表示有人脸,0表示没有人脸,然后输出(l_1x,l_1y)......直到(l_64x,l_64y)。这里一共有129(1+2*64=129)个输出单元,由此实现对图片的人脸检测和定位。这只是一个识别脸部表情的基本构造模块(basic building block),如果你玩过Snapchat或其它娱乐类应用(other entertainment),你应该对AR(增强现实Augmented Reality)过滤器多少有些了解,Snapchat过滤器实现了在脸上画皇冠和其他一些特殊效果。
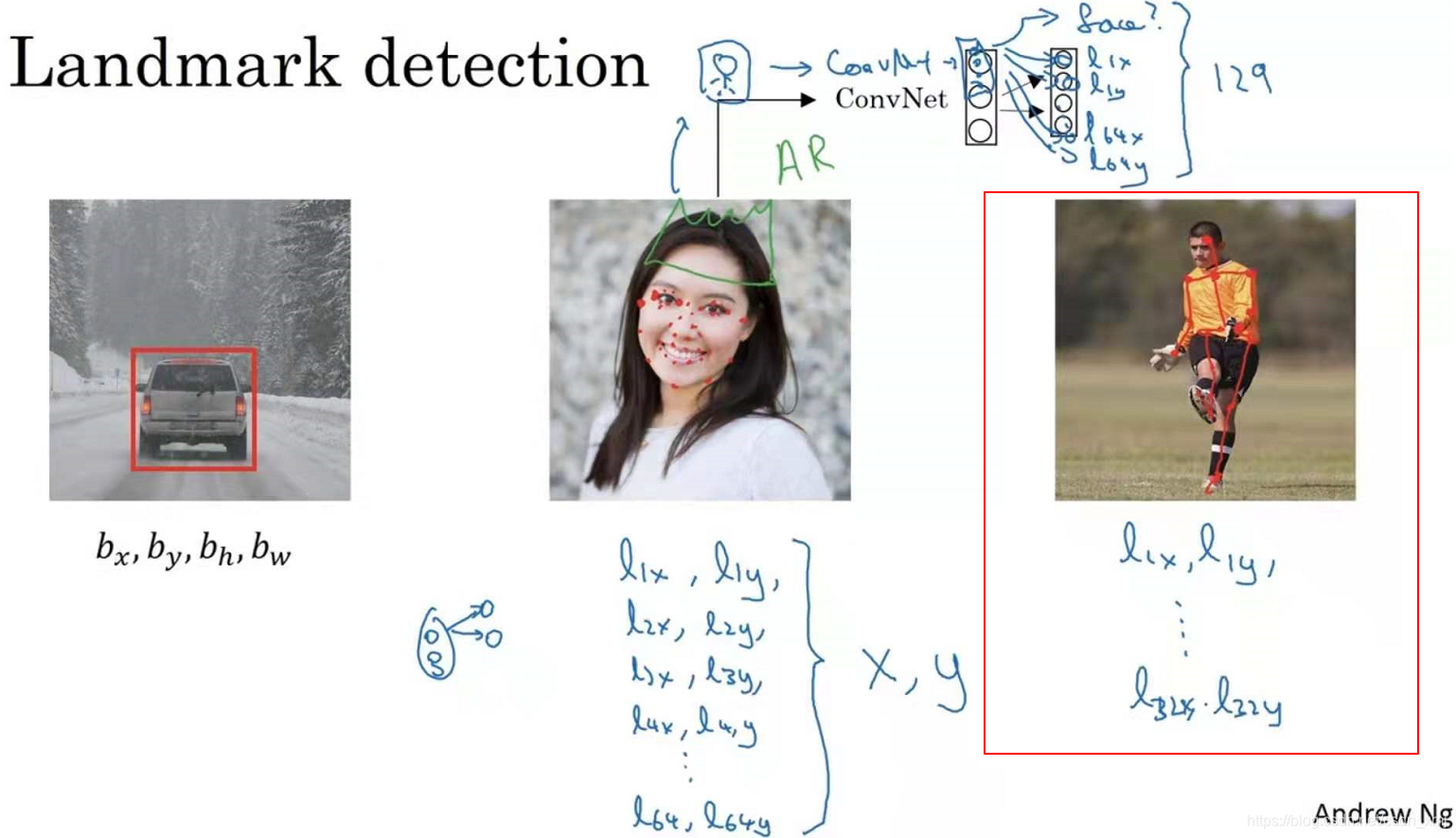
再看一个例子,上图的第三张图,如果你对人体姿态检测(people post-detection)感兴趣,也可以定义一些关键特征点(key positions),如胸部的中点(the midpoint of the chest),左肩(the left shoulder),左肘(left elbow),腰(the wrist)等,从胸部中心点(l_1x,l_1y)一直向下,一直到(l_32x,l_32y)。然后通过神经网络标注人物姿态的关键特征点,再输出这些标注过的特征点,就相当于输出了人物的姿态动作。一旦了解如何用二维坐标系(two coordinates)定义人物姿态,操作起来就相当简单了。要明确一点,特征点的特性(identity)在所有图片中必须保持一致,就好比,特征点1始终是右眼的外眼角,特征点2是右眼的内眼角,特征点3是左眼内眼角,特征点4是左眼外眼角等等。同样可以利用特征点实现其他有趣的效果,比如判断人物的动作姿态(estimate the pose of a person),识别图片中的人物表情(recognize someone’s emotion from a picture)等等。
以上就是特征点检测(landmark detection)的内容,熟悉这些构造模块有利于构建目标检测算法。
说明:记录学习笔记,如果错误欢迎指正!转载请联系我。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)