PyPDF2--如何使用python操作你的PDF文档
PyPDF2–如何使用python操作你的PDF文档前言大家好!最近想操作一下PDF文档,总是收费,于是浅尝辄止地了解了一下python当中的PyPDF2这个库。借助本篇博客总结了一下个人所学到的内容。本人才疏学浅,还望各位大佬多多指正。Python在自动化办公方面有很多实用的第三方库,可以很方便的处理word、excel、ppt、pdf文件,Python处理PDF文档的两个常用库pdfplumb
PyPDF2–如何使用python操作你的PDF文档
前言
大家好!最近想操作一下PDF文档,总是收费,于是浅尝辄止地了解了一下python当中的PyPDF2这个库。借助本篇博客总结了一下个人所学到的内容。本人才疏学浅,还望各位大佬多多指正。Python在自动化办公方面有很多实用的第三方库,可以很方便的处理word、excel、ppt、pdf文件,Python处理PDF文档的两个常用库pdfplumber,PyPDF2。在此本人对PyPDF2进行一个简单的介绍。
0.0:PyPDF2简介以及安装
PyPDF2 是一个纯 Python PDF 库,可以读取文档信息(标题,作者等)、写入、分割、合并PDF文档,它还可以对pdf文档进行添加水印、加密解密等操作。
很多具体参数设置大家可以访问其官方文档→https://pythonhosted.org/PyPDF2
Windows安装方法:
- win+r输入cmd 打开命令窗口
- 直接输入 pip install PyPDF2
- 速度太慢可以使用镜像如
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple PyPDf2 - 在pycharm上面:左上角File->Settings->Project Interpreter->+找到后Install就可以了
- 在https://pypi.org/project/PyPDF2/ 中搜索PyPDF2 1.26.0下载后也可以直接安装

(注:IOS系统以及Linux系统上安装在此不过多描述)
我们可以在其官方文档首页看到如下页面
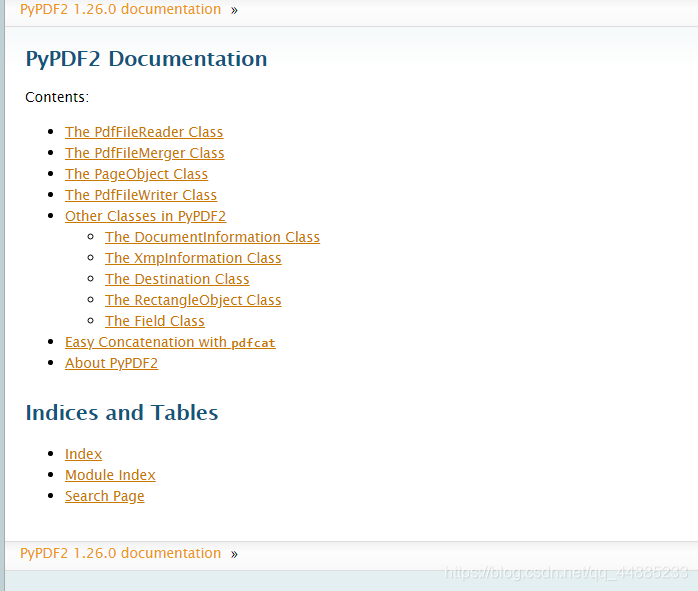
我们可以看到这个第三方库主要包括PdfFileReader Class,PdfFileMerger,PageObject Class,PdfFileWriter这四个大类还有一个其他类。下面我们开始对其一一进行描述。
1:The PdfFileReader Class:
初始化一个 PdfFileReader 对象A,此操作可能需要一些时间,因为 PDF 流的交叉引用表被读入内存。
A = PyPDF2.PdfFileReader(stream, strict=True, warndest=None, overwriteWarnings=True)
其中参数:
stream:这个单词直接翻译成中文表示溪流或者流动,这里表示你需要操作的pdf文件或者其路径的字符串。
strict:确定是否应警告用户所有问题,并导致一些可纠正的问题致命。默认为True。
warndest:记录警告的目标(默认为系统标准)
overwriteWarnings:觉得是否使用一个自定义实现来覆盖python的warning模块。
正常情况下我们一般只会用到第一个参数stream
关于PdfFileReader的一些操作函数属性的讲解
| 相关属性以及函数 | 描述 | 备注 |
|---|---|---|
| decrypt(password) | 可以对加密的文档进行解密操作 | |
| documentInfo | 通过getDocumentInfo()函数功能访问的只读属性 | |
| getDestinationPageNumber(destination) | 检索目标对象的页数 | 若错误则返回-1 |
| getDocumentInfo() | 检索PDF文件的字典信息是否存在存在会返回相关信息,不存在则会返回None | 部分PDF文件使用的是元数据流 |
| getFields(tree=None, retval=None, fileobj=None) | 如果此 PDF文档中包含交互式表单字段,则提取字段数据 | 返回类型是字典或者None |
| getFormTextFields() | 从文档中检索带有文本数据(输入,下拉列表)的表单域 | |
| getNamedDestinations(tree=None, retval=None) | 检索文档中的特定的目标 | 返回字典类型 |
| namedDestinations | 通过getNamedDestinations()函数的只读属性 | |
| getNumPages() | 计算此PDF的页数 | |
| numPages | 通过getNumPages()函数的只读属性 | |
| getOutlines(node = None,outlines = None ) | 检索文档中存在的文档大纲 | |
| outlines | 通过getOutlines()函数的只读属性 | |
| getPage(pageNumber ) | 按编号检索页面 | 就是找到某页内容 |
| getPageLayout() | 获取页面布局 | 返回类型为字符串 |
| pageLayout | 通过getPageLayout()的只读属性 | |
| getPageMode() | 获取页面模式 | 返回类型为字符串 |
| pageMode | 通过getPageMode的只读属性 | |
| getPageNumber(页面) | 检索给定页面的页码 | |
| getXmpMetadata() | 从PDF文档根目录检索XMP(可扩展元数据平台)数据 | |
| xmpMetadata | 通过getXmpMetadata()的只读属性 | |
| isEncrypted | 显示此文档是否被加密的属性 | 如果为True调用decrypt()解密之后属性依旧为True |
PdfFileReader相关代码举例
以下代码均在Anaconda3上正常运行
from PyPDF2 import PdfFileReader
import os #os库可以进行相关路径操作在此不做多示范
readFile = './XXX.pdf'#这里XXX改成你这个.py同文件夹下的pdf文件名即可
# 获取 PdfFileReader 对象
pdfFileReader = PdfFileReader(readFile) # 或者这个方式:pdfFileReader = PdfFileReader(open(readFile, 'rb'))
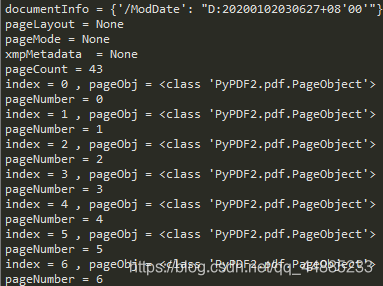
# 获取 PDF 文件的文档信息
documentInfo = pdfFileReader.getDocumentInfo()
print('documentInfo = %s' % documentInfo)
# 获取页面布局
pageLayout = pdfFileReader.getPageLayout()
print('pageLayout = %s ' % pageLayout)
# 获取页模式
pageMode = pdfFileReader.getPageMode()
print('pageMode = %s' % pageMode)
xmpMetadata = pdfFileReader.getXmpMetadata()
print('xmpMetadata = %s ' % xmpMetadata)
# 获取 pdf 文件页数
pageCount = pdfFileReader.getNumPages()
print('pageCount = %s' % pageCount)
for index in range(0, pageCount):
# 返回指定页编号的 pageObject
pageObj = pdfFileReader.getPage(index)
print('index = %d , pageObj = %s' % (index, type(pageObj)))
# 获取 pageObject 在 PDF 文档中处于的页码
pageNumber = pdfFileReader.getPageNumber(pageObj)
print('pageNumber = %s ' % pageNumber)
结果

2:The PdfFileMerger Class:
初始化一个PdfFileMerger对象B,其可以将多个pdf合并成 一个,可以串联、切片或者插入
B = PyPDF2.PdfFileMerger(strict=True)
其中参数:
strict:默认为True,决定是否用户因一下问题被警告,并且可能导致一些可以纠正的问题是致命的。
关于PdfFileMerger的一些操作函数属性的讲解
| 相关函数 | 描述 | 备注 |
|---|---|---|
| addBookmark(title, pagenum, parent=None) | 将书签添加到这个pdf里面 | |
| addMetadata(infos) | 将自定义元数据添加到输出中 | |
| addNamedDestination(title, pagenum) | 将目标添加到输出。 | |
| append(fileobj, bookmark=None, pages=None, import_bookmarks=True) | 与merge()方法相同,但是假定您要将所有页面连接到文件末尾,而不是指定位置 | |
| close() | 关闭所有文件描述符(输入和输出)并清除所有内存使用情况 | |
| merge(position, fileobj, bookmark=None, pages=None, import_bookmarks=True) | 以指定的页码将页面从给定文件合并到输出文件中 | |
| setPageLayout(layout) | 设置页面布局 | |
| setPageMode(mode) | 设置页面模式 | |
| write(fileobj) | 将已合并的所有数据写入给定的输出文件 |
PdfFileMerger相关代码举例
以下代码展示的是利用PdfFileMerger进行多个pdf文件的合并
from PyPDF2 import PdfFileMerger
import os #os库可以进行相关路径操作在此不做多示范
import sys
def remove_pdf_file(file):
os.remove(file)
def get_all_pdf_files(path):
pdfs = [ file for file in os.listdir(path) if '.pdf' in file ]
return pdfs
def merge_pdf_file(pdfs):
pdf_file_merger = PdfFileMerger()
merged_pdf = 'merged_pdf_file.pdf'
for pdf in pdfs:
if merged_pdf == pdf:
remove_pdf_file(pdf)
try:
pdf_file_merger.append(open(pdf, 'rb'))
except:
print("merging pdf file %s failed." % pdf)
with open(merged_pdf, 'wb') as fout:
pdf_file_merger.write(fout)
return merged_pdf
def main():
pdfs = get_all_pdf_files(sys.path[0]) # current path
print('The file', merge_pdf_file(pdfs), 'is generated.')
if __name__ == "__main__":
main()
此处不展示结果还请大家自己运行查看
大家可以自行拓展将爬虫技术结合自动爬取网络上的pdf资源并进行合并
3:The PdfFileObject Class:
此类表示PDF文件中的单个页面。通常,将通过访问类的getPage()方法 来创建此对象 PdfFileReader,但是也可以使用createBlankPage()静态方法来创建一个空页面
C = PyPDF2.pdf.PageObject(pdf=None, indirectRef=None)
-
其中参数
- pdf:页面所属的PDF文件
- indirectRef:在该对象的源PDF中存储对该对象的原始间接引用(通俗来讲就是)
关于PdfFileObject的一些操作函数属性的讲解
| 相关属性以及函数 | 描述 | 备注 |
|---|---|---|
| addTransformation(ctm) | 将转换矩阵应用于页面 | |
| compressContentStreams() | 通过加入所有内容流并应用FlateDecode过滤器来压缩此页面的大小 | 如果内容流压缩由于某种原因变为“自动”,则此功能可能不会执行任何操作 |
| static createBlankPage(pdf=None, width=None, height=None) | 返回一个新的空白页。如果width或者height是None,尝试从最后一页得到的页面大小的PDF | |
| extractText() | 按照在内容流中提供的顺序找到所有文本绘制命令,然后提取文本 | 返回值为unicode字符串对象 |
| getContents() | 访问页面内容 | |
| mediaBox | 将两页的内容流合并为一个。资源引用(即字体)从两个页面维护 | |
| mergePage(page2) | 类似于mergePage,但是要合并的流通过应用转换矩阵来旋转 | |
| mergeRotatedPage(page2, rotation, expand=False) | 类似于mergePage,但是要合并的流通过应用转换矩阵来旋转和缩放 | |
| mergeRotatedScaledPage(page2, rotation, scale, expand=False) | 类似于mergePage,但是要合并的流通过应用转换矩阵进行转换,旋转和缩放 | |
| mergeRotatedScaledTranslatedPage(page2, rotation, scale, tx, ty, expand=False) | 类似于mergePage,但是要合并的流通过应用转换矩阵进行旋转和转换 | |
| mergeRotatedTranslatedPage(page2, rotation, tx, ty, expand=False) | 类似于mergePage,但是要合并的流通过应用转换矩阵进行缩放 | |
| mergeScaledPage(page2, scale, expand=False) | 类似于mergePage,但是要合并的流通过应用转换矩阵进行转换和缩放 | |
| mergeScaledTranslatedPage(page2, scale, tx, ty, expand=False) | 类似于mergePage,但是将转换矩阵应用于合并的流 | |
| mergeTransformedPage(page2, ctm, expand=False) | 类似于mergePage,但是要合并的流通过应用转换矩阵进行翻译 | |
| mergeTranslatedPage(page2, tx, ty, expand=False) | 这类似于mergePage,但是要合并的流通过应用转换矩阵进行翻译 | |
| rotateClockwise(angle) | 顺时针旋转页面90度 | |
| rotateCounterClockwise(angle) | 逆时针旋转页面90度 | |
| scale(sx, sy) | 通过将变换矩阵应用于其内容并更新页面大小,以给定的因子缩放页面 | |
| scaleBy(factor) | 通过将转换矩阵应用于其内容并更新页面大小,可以按给定因子缩放页面 | |
| scaleTo(width, height) | 通过将转换矩阵应用于其内容并更新页面大小,将页面缩放到指定的尺寸 | |
| trimBox | 一个矩形对象,以默认用户空间单位表示,用于定义修剪后完成页面的预期尺寸。 | |
| artBox | 一个矩形对象,以默认用户空间单位表示,定义了页面创建者想要的页面有意义内容的范围 | |
| bleedBox | 一个矩形对象,以默认用户空间单位表示的A ,定义在生产环境中输出时页面内容应剪切到的区域 | |
| cropBox | 以默认用户空间单位表示,定义默认用户空间的可见区域。当显示或打印页面时,页面的内容将被剪切(裁剪)到该矩形,然后以实现定义的方式施加到输出介质上。默认值:与相同mediaBox | |
| mediaBox | 一个矩形对象,以默认用户空间单位表示的A ,定义了要在其上显示或打印页面的物理介质的边界。 |
PdfFileObject相关代码举例
以下代码为粗略读取PDF文本内容
def getPdfContent(filename):
pdf = PdfFileReader(open(filename, "rb"))
content = ""
for i in range(0, pdf.getNumPages()):
pageObj = pdf.getPage(i)
extractedText = pageObj.extractText()
content += extractedText + "\n"
# return content.encode("ascii", "ignore")
return content
4:The PdfFileWriter Class:
此类支持将PDF文件写出,给定由另一类产生的页面(通常为PdfFileReader)
D = PyPDF2.PdfFileWriter()
其中参数:
关于PdfFileWriter的一些操作函数属性的讲解
| 相关属性以及函数 | 解 释 | 备 注 |
|---|---|---|
| addAttachment(fname, fdata) | 将文件嵌入PDF | |
| addBlankPage(width=None, height=None) | 将一个空白页添加到PDF文件里 | 具体页数没有确定的话,添加到最后一页 |
| addBookmark(title, pagenum, parent=None, color=None, bold=False, italic=False, fit=’/Fit’, *args) | 将书签添加到这个PDF | |
| addJS(javascript) | 在打开PDF的时候添加javascript | |
| addLink(pagenum, pagedest, rect, border=None, fit=’/Fit’, *args) | 添加从矩形区域到指定页面的内部链接 | |
| addMetadata(infos) | 将自定义元数据添加到输出中 | |
| addPage(page) | 将页面添加到此PDF文件。该页面通常是从PdfFileReader实例获取的 | |
| appendPagesFromReader(reader, after_page_append=None) | 将页面从读取器复制到写入器。包括一个可选的回调参数,该参数在将页面追加到writer之后被调用 | |
| cloneDocumentFromReader(reader, after_page_append=None) | 从PDF文件阅读器创建文档的副本(克隆) | |
| cloneReaderDocumentRoot(reader) | 将阅读器文档根目录复制到编写器 | |
| encrypt(user_pwd, owner_pwd=None, use_128bit=True) | 使用PDF Standard加密处理程序对该PDF文件进行加密 | |
| getNumPages() | 获取页数 | 返回值为整数 |
| getPage(pageNumber) | 从此PDF文件中按编号检索页面 | 返回类型为Pageobject |
| getPageLayout() | 获取页面布局 | |
| getPageMode() | 获取页面模式 | |
| insertBlankPage(width=None, height=None, index=0) | 插入空白页到PDF文件 | 未指定则默认最后一页 |
| insertPage(page, index=0) | 插入一页内容到PDF文件 | |
| pageLayout | 读取和写入访问getPageLayout() 和setPageLayout()方法的属性 | |
| pageMode | 读取和写入访问getPageMode() 和setPageMode()方法的属性 | |
| removeImages(ignoreByteStringObject=False) | 从此输出中删除图像 | |
| removeLinks() | 从此输出中删除链接和注释 | |
| removeText(ignoreByteStringObject=False) | 从此输出中删除图像 | |
| setPageLayout(layout) | 设置页面布局 | |
| setPageMode(mode) | 设置页面模式 | |
| updatePageFormFieldValues(page, fields) | 从字段字典更新给定页面的表单字段值。将字段文本和值从字段复制到页面 | |
| write(stream) | 将添加到该对象的页面集合写为PDF文件 |
PdfFileWriter相关代码举例
以下代码均在Anaconda3上正常运行
"""
本程序用于编辑PDF页
@author:
"""
from PyPDF2 import PdfFileWriter, PdfFileReader
#删除
output = PdfFileWriter() #// 1
input1 = PdfFileReader(open("Linux讲义.pdf", "rb")) #// 2
def delete_pdf(index):
pages = input1.getNumPages() #// 3
for i in range(pages):
if i+1 in index:
continue
output.addPage(input1.getPage(i)) #// 4
outputStream = open("Linux讲义0.pdf", "wb")
output.write(outputStream) #// 5
#删除测试
delete_pdf([2,3,4])
'''
1声明一个用于输出PDF的实例;
2读取本地PDF文件;
3获取PDF文档的页数;
4读取PDF的第i页,添加到输出output实例中;
5把编辑后的文档保存到本地;
'''
##合并
#方法一
output = PdfFileWriter()
input1 = PdfFileReader(open("Linux讲义0.pdf", "rb"))
input2 = PdfFileReader(open("Linux讲义.pdf", "rb")) #// 1
def merge_pdf(add_index, origin_index):
pages = input1.getNumPages()
k = 0
for i in range(pages):
if i+1 in add_index:
output.addPage(input2.getPage(origin_index[k]))# // 2
pages += 1
k += 1
output.addPage(input1.getPage(i))
outputStream = open("PyPDF2-output.pdf", "wb")
output.write(outputStream)
merge_pdf([2,3,4], [0, 0, 0])
"""
1读取需要合并的源文件;
2遍历到指定页,合并源PDF的页面;
"""
#方法二
from PyPDF2 import PdfFileMerger #// 1
merger = PdfFileMerger()
input1 = open("document1.pdf", "rb") #// 2
input2 = open("document2.pdf", "rb")
input3 = open("document3.pdf", "rb")
merger.append(fileobj = input1, pages = (0,3))# // 3
merger.merge(position = 2, fileobj = input2, pages = (0,1))# // 4
merger.append(input3)# // 5
output = open("document-output.pdf", "wb")
merger.write(output)
'''
1导入PyPDF2合并模块PdfFileMerger;
2读取需要处理和合并的PDF文档;
3从第一个PDF文档中取出需要合并的前3页;
4把第二个PDF文档的第一页插入到文档中;
5把第三个PDF文档附到输出文档末尾;
'''
#旋转
input1.getPage(1).rotateClockwise(90)#使页面1旋转90度
#添加水印
page = input1.getPage(3)
watermark = PdfFileReader(open("watermark.pdf", "rb"))
page.mergePage(watermark.getPage(0))
#其中,水印存储在另外一个PDF文档watermark.pdf中。
#加密
password = "secret"
output.encrypt(password)
结果
还请各位自己运行,运行程序时注意修改PDF文档的文件名
5:The Other Classes in PyPDF2:
5.1:The DocumentInformation Class
表示PDF文件中提供的基本文档元数据的类。该类可通过以下方式访问 getDocumentInfo()
文档元数据的所有文本属性都有 两个属性,例如。作者和author_raw。non-raw属性将始终返回a TextStringObject,使其非常适合显示元数据的情况。ByteStringObject如果PyPDF2无法解码字符串的文本编码,则raw属性有时会返回;这要求在呼叫者中增加安全性,因此不常用。
M = PyPDF2.DocumentInformation()
其中参数:无
关于The DocumentInformation Class的一些属性的讲解
| 相关属性 | 描述 | 备注 |
|---|---|---|
| author | 只读属性 | 返回类型为unicode |
| 访问文档author的只读属性 | 原始版本 | |
| creator | 文档创建者的只读属性 | 返回类型为unicode |
| creator_raw | 创建者的原始版本 | |
| producer | 访问文档生产者的只读属性 | |
| producer_raw | 生产者的“原始”版本 | |
| subject | 只读属性,用于访问文档的subject | |
| subject_raw | 主题的“原始”版本 | 返回ByteStringObject |
| title | 只读属性,用于访问文档的title只读属性,用于访问文档的title | 返回unicode字符串(TextStringObject),或者None 未指定标题 |
| title_raw | 标题的“原始”版本 | 返回ByteStringObject |
The DocumentInformation Class相关代码举例
以下代码均在Anaconda3上正常运行
from PyPDF2 import PdfFileReader
>>> inputPdf = PdfFileReader(open("test.pdf", "rb"))
>>> docInfo = inputPdf.getDocumentInfo()
>>> docInfo.author
Anonymous
>>> docInfo.creator
Hewlett Packard MFP
>>> docInfo.producer
Acrobat Distiller 10.0.0 (Windows)
>>> docInfo.title
A Test
>>> docInfo.subject
testing
结果
5.2:The XmpInformation Class
表示Adobe XMP元数据的对象。通常由getXmpMetadata()
N = PyPDF2.XmpInformation(stream)
其中参数:无
关于The XmpInformation Class的一些属性的讲解
| 相关属性 | 描述 | 备注 |
|---|---|---|
| custom_properties | 检索在未记录的pdfx元数据架构中定义的自定义元数据属性 | |
| dc_contributor | 资源的贡献者(作者除外)。未排序的名称数组 | |
| dc_coverage | 描述资源范围的文本 | |
| dc_creator | 资源作者姓名的排序列表,按优先顺序列出 | |
| dc_date | 对资源有意义的日期(日期时间(datetime.datetime实例)的排序数组)。日期和时间以UTC为单位 | |
| dc_description | 语言的字典,描述资源内容的文本描述 | |
| dc_format | 资源的哑剧类型 | |
| dc_identifier | 资源的唯一标识符 | |
| dc_language | 一个无序数组,指定资源中使用的语言 | |
| dc_publisher | 发布者名称的无序数组 | |
| dc_relation | 与其他文档的关系的无序文本描述数组 | |
| dc_rights | 用户对该资源拥有的权利的文字描述的语言键字典 | |
| dc_source | 来源资源的作品的唯一标识符 | |
| dc_subject | 说明性短语或关键字的无序数组,用于指定资源内容的主题 | |
| dc_title | 资源标题的语言键字典 | |
| dc_type | 文档类型的无序文本描述数组 | |
| pdf_keywords | 表示文档关键字的无格式文本字符串 | |
| pdf_pdfversion | PDF文件版本,例如1.0、1.3 | |
| pdf_producer | 创建PDF文档的工具的名称 | |
| xmp_createDate | 最初创建资源的日期和时间。日期和时间作为UTC datetime.datetime对象返回 | |
| xmp_creatorTool | 用于创建资源的第一个已知工具的名称 | |
| xmp_metadataDate | 上次更改此资源的任何元数据的日期和时间。日期和时间作为UTC datetime.datetime对象返回 | |
| xmp_modifyDate | 资源的最后修改日期和时间。日期和时间作为UTC datetime.datetime对象返回 | |
| xmpmm_documentId | 此资源所有版本和格式的通用标识符 | |
| xmpmm_instanceId | 文档特定版本的标识符,每次保存文件时都会更新 |
5.3:The Destination Class
表示PDF文件中目标的类
O = PyPDF2.generic.Destination(title, page, typ, *args)
-
其中参数:
- title:此目的地的标题
- page:此目标的页码
- typ:如何显示目的地
- *args:其他参数
关于The Destination Class的一些属性的讲解
以下属性均为只读属性
| 相关属性 | 描述 | 备注 |
|---|---|---|
| bottom | 用于访问底部垂直坐标 | |
| left | 用于访问左侧的水平坐标 | |
| page | 用于访问目标页码 | |
| right | 用于访问右侧的水平坐标 | |
| title | 访问目标标题的 | |
| top | 用于访问顶部垂直坐标 | |
| typ | 访问目标类型 | |
| zoom | 访问缩放因子 |
5.4:The RectangleObject Class
-
此类用于表示PyPDF2中的页面框。这些框包括:
- artBox
- bleedBox
- cropBox
- mediaBox
- trimBox
P = PyPDF2.generic.RectangleObject(arr)
其中参数:无
关于The RectangleObject Class的一些属性的讲解
| 相关属性 | 描述 | 备注 |
|---|---|---|
| lowerLeft | 以(x,y)形式读取和修改此框的左下坐标的属性 | |
| lowerRight | 以(x,y)形式读取和修改此框的右下坐标的属性 | |
| upperLeft | 以(x,y)形式读取和修改此框的左上坐标的属性 | |
| upperRight | 以(x,y)形式读取和修改此框的右上角坐标的属性 |
5.5:The Field Class
表示字段字典的类。此类通过以下方式访问
getFields()
M = PyPDF2.generic.Field(data)
其中参数:
data:数据
关于The Field Class的一些属性的讲解
以下属性均为只读属性
| 相关属性 | 描述 | 备注 |
|---|---|---|
| additionalActions | 用于访问其他操作字典。该词典定义了字段对触发事件的响应 | |
| altName | 用于访问此字段的备用名称 | |
| defaultValue | 用于访问此字段的默认值 | |
| fieldType | 用于访问此字段的类型 | |
| flags | 用于访问字段标志,指定字段的各种特征 | |
| kids | 用于访问该字段的孩子 | |
| mappingName | 用于访问此字段的映射名称 | |
| name | 用于访问此字段的名称 | |
| parent | 用于访问此字段的父级 | |
| value | 用于访问此字段的值。格式因字段类型而异 |
后记
- 本篇文章主要参考PyPDF2官方文档撰写,但本人英语水平有限,很多地方讲解可能没有到位。
- 写这篇博客主要是想锻炼一下英语阅读水平
- 有错的地方还请大家提出。
- 这篇博客部分参考:https://blog.csdn.net/xingxtao/article/details/79056341
- 很多代码并没有添加修改完善。等后期有时间再进行添加。
- 下一期想出一个利用爬虫爬取基金的历史的估值和实际涨幅值作为训练数据再经过学习后进行预测可视化。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)