什么是数据湖(Data Lake)?
什么是数据湖(Data Lake)?有些东西就是概念,故弄玄虚,just fancy nameswikipedia:A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks su
什么是数据湖(Data Lake)?
有些东西就是概念,故弄玄虚,
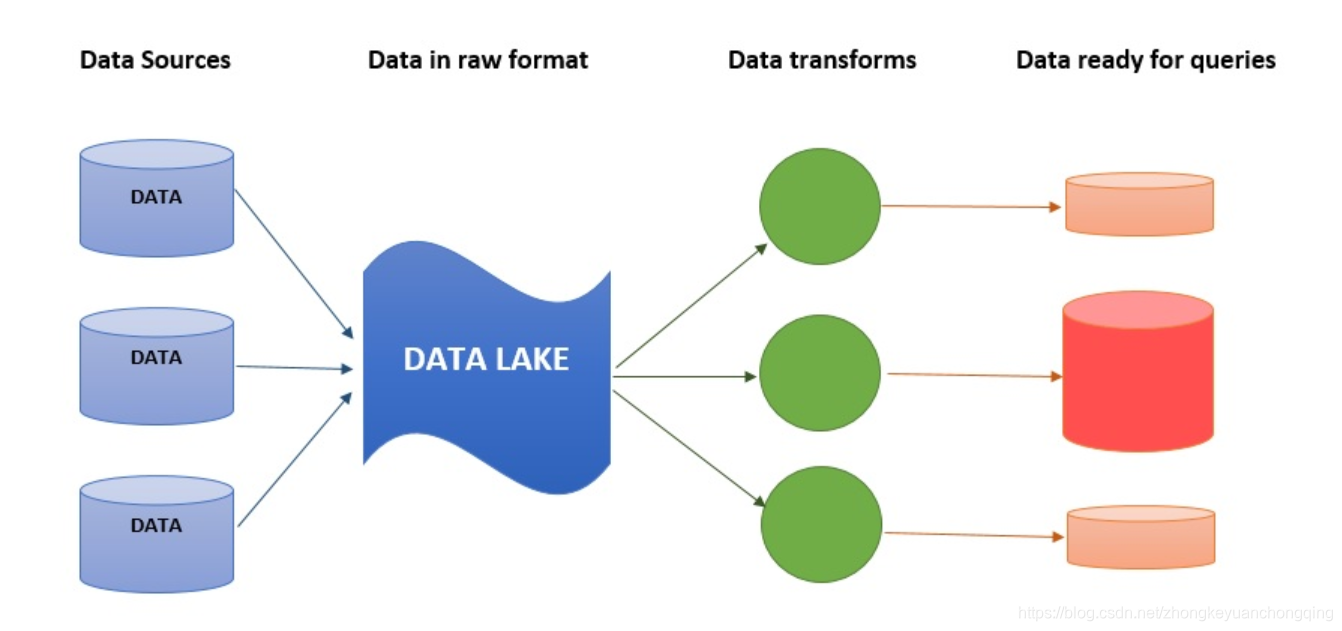
A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting , visualization , advanced analytics and machine learning . A data lake can include structured data from relational databases (rows and columns), semi-structured data ( CSV , logs, XML , JSON ), unstructured data (emails, documents, PDFs) and binary data (images, audio , video).
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
通过数据成功创造商业价值的组织将胜过同行。Aberdeen 的一项调查表明,实施数据湖的组织比同类公司在有机收入增长方面高出 9%。这些领导者能够进行新类型的分析,例如通过日志文件、来自点击流的数据、社交媒体以及存储在数据湖中的互联网连接设备等新来源的机器学习。这有助于他们通过吸引和留住客户、提高生产力、主动维护设备以及做出明智的决策来更快地识别和应对业务增长机会。
能够在更短的时间内从更多来源利用更多数据,并使用户能够以不同方式协同处理和分析数据,从而做出更好、更快的决策。数据湖具有增值价值的示例包括:
根据要求,典型的组织将需要数据仓库和数据湖,因为它们可满足不同的需求和使用案例。
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。事先定义数据结构和 Schema 以优化快速 SQL 查询,其中结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。
数据湖有所不同,因为它存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。捕获数据时,未定义数据结构或 Schema。这意味着您可以存储所有数据,而不需要精心设计也无需知道将来您可能需要哪些问题的答案。您可以对数据使用不同类型的分析(如 SQL 查询、大数据分析、全文搜索、实时分析和机器学习)来获得见解。
随着使用数据仓库的组织看到数据湖的优势,他们正在改进其仓库以包括数据湖,并启用各种查询功能、数据科学使用案例和用于发现新信息模型的高级功能。Gartner 将此演变称为“分析型数据管理解决方案”或“DMSA”。
| 特性 | 数据仓库 | 数据湖 |
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 设计在数据仓库实施之前(写入型 Schema) | 写入在分析时(读取型 Schema) |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 机器学习、预测分析、数据发现和分析 |
AWS Lake Formation 是一项服务,可以在几天内轻松建立安全的数据湖。数据湖是一个安全的集中式辅助存储库,它以数据原始形式和可用于分析的形式存储所有数据。利用数据湖,您可以分解数据孤岛并组合不同类型的分析,从而获得见解并指导作出更好的业务决策。
但是如今,设置和管理数据湖涉及大量极为耗时的复杂手动任务。这项工作包括加载来自不同来源的数据、监控这些数据流、设置分区、打开加密和管理密钥、定义转换作业并监控其操作、将数据重新组织成列格式、配置访问控制设置、删除冗余数据重复数据、匹配链接记录、授予对数据集的访问权限以及随时间推移审核访问权限。
使用 Lake Formation 创建数据湖很简单,只需定义数据源,制定要应用的数据访问和安全策略就行。然后,Lake Formation 会帮助您从数据库和对象存储中收集并按目录分类数据,将数据移动到新的 Amazon S3 数据湖,使用机器学习算法清理和分类数据,并保护对敏感数据的访问权限。您的用户可以访问那些描述了可用数据集及其适当用法的集中数据目录。然后,用户可以通过所选的分析和机器学习服务,利用这些数据集,例如 Amazon Redshift、Amazon Athena 和 Amazon EMR for Apache Spark(测试版)。Lake Formation 建立在 AWS Glue 中可用的功能之上。
- ODS(operational data store, staging area)存储来自各业务系统(生产系统)的原始数据,即为数据湖
- CDM为经过整合、清洗的数据。其中的DWS汇总层,为面向主题的数据仓库(狭义),用于BI报表出数
简单来说,数据湖的定义就是原始数据保存区. 虽然这个概念国内谈的少,但绝大部分互联网公司都已经有了。国内一般把整个HDFS叫做数仓(广义),即存放所有数据的地方
数据湖和数仓,就是原始数据和数仓模型的区别。因为数仓(狭义)中的表,主要是事实表-维度表(下图),主要用于BI、出报表,和原始数据是不一样的
真正的原因在于,data science和machine learning进入主流了,需要用原始数据做分析,而数仓的维度模型则通常用于聚合
另一方面,机器学习用到的数据,也不止于结构化数据。用户的评论、图像这些非结构化数据,也都可以应用到机器学习中
2者的区别,也就是AWS这张图(https://aws.amazon.com/cn/big-data/datalakes-and-analytics/what-is-a-data-lake/?nc=sn&loc=2)
- 传统数仓的工作方式是集中式的:业务人员给需求到数据团队,数据团队根据要求加工、开发成维度表,供业务团队通过BI报表工具查询
- 数据湖是开放、自助式的(self-service):开放数据给所有人使用,数据团队更多是提供工具、环境供各业务团队使用(不过集中式的维度表建设还是需要的),业务团队进行开发、分析
也就是组织架构和分工的差别 —— 传统企业的数据团队可能被当做IT,整天要求提数,而在新型的互联网/科技团队,数据团队负责提供简单易用的工具,业务部门直接进行数据的使用。人人具备数据分析能力
https://infoq.cn/article/the-development-history-of-big-data-platform-internet-age 中的图比较直观
因此,数据湖最大的意义,在于帮团队做组织架构调整,鼓励所有人了解、分析数据,降低出数类等"IT"型工作。当然,对传统企业而言,也是引入机器学习、用户画像的必须基础设施
从传统集中式的数仓转为开放式的数据湖,并不简单,会碰到许多问题
- 数据安全:如果管理数据的权限和安全?因为一些数据是敏感的、或者不应直接开放给所有人的(比如电话号码、地址等)
- 数据管理:多个团队使用数据,如何共享数据成果(比如画像、特征、指标),避免重复开发
比如,对于数据发现,目前的解决方案就是Data catalog, 典型的比如IBM Watson catalog (算是对传统元数据管理的改进). 对于机器学习方面的数据管理,可以看Airbnb的机器学习平台Bighead中的实践
可参考AWS全家桶,及其新出的data lake formation
https://aws.amazon.com/cn/big-data/datalakes-and-analytics/
Big Data Analytics Architectural Patterns & Best Practices https://www.youtube.com/watch?v=ovPheIbY7U8
Effective Data Lakes: Challenges and Design Patterns: https://www.youtube.com/watch?v=v5lkNHib7bw
Build and Govern Your Data Lakes with AWS Glue: https://www.youtube.com/watch?v=JsNR8uBVSiA
Segment的介绍: https://segment.com/blog/cultivating-your-data-lake/
数据湖对我最大的意义,是让我明白了为什么我get不到数仓的点。因为我偏机器学习、偏业务线,更倾向于拿原始数据分析,而不是用加工好的数据看指标。
All too often, we hear that businesses want to do more with their customer data. They want to be data-informed, they want to provide better customer experiences, and—most of all—they just want to understand their customers.
Getting there isn’t easy. Not only do you need to collect and store the data, you also need to identify the useful pieces and act on the insights.
At Segment, we’ve helped thousands of businesses walk the path toward becoming more data-informed. One successful technique we’ve seen time and time again is establishing a working data lake.
A data lake is a centralized repository that stores both structured and unstructured data and allows you to store massive amounts of data in a flexible, cost effective storage layer. Data lakes have become increasingly popular both because businesses have more data than ever before, and it’s never been cheaper and easier to collect and store it all.
In this post, we’ll dive into the different layers to consider when working with a data lake.
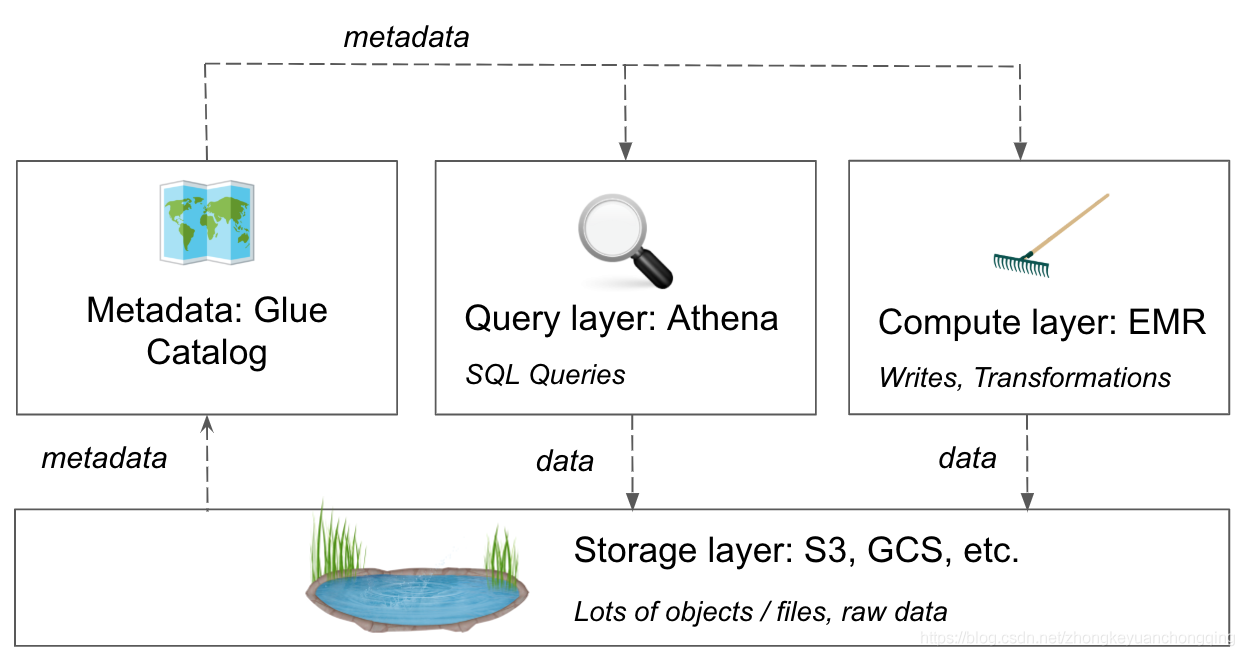
- We’ll start with an object store, such as S3 or Google Cloud Storage, as a cheap and reliable storage layer.
- Next is the query layer, such as Athena or BigQuery, which will allow you to explore the data in your data lake through a simple SQL interface.
- A central piece is a metadata store, such as the AWS Glue Catalog, which connects all the metadata (its format, location, etc.) with your tools.
- Finally, you can take advantage of a transformation layer on top, such as EMR, to run aggregations, write to new tables, or otherwise transform your data.
As heavy users of all of these tools in AWS, we’ll share some examples, tips, and recommendations for customer data in the AWS ecosystem. These same concepts also apply to other clouds and beyond.
参考:什么是数据湖?现在国内有哪些企业在做?
参考:Cultivating your Data Lake
参考:我所经历的大数据平台发展史(四):互联网时代 • 下篇
参考:AWS+什么是数据湖?

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)