爬取网页过程报错:RemoteDisconnected: Remote end closed connection without response
有问题的代码:import urllib.request# 代码002:(未声明headers,会报错)response = urllib.request.urlopen("http://www.baidu.com")print(response)print(response.read())运行结果:Traceback (most recent call last):File "D:/Pychar
有问题的代码:
import urllib.request
# 代码002:(未声明headers,会报错)
response = urllib.request.urlopen("http://www.baidu.com")
print(response)
print(response.read())
运行结果:
Traceback (most recent call last):
File "D:/PycharmProjects/pythonProject/douban/test1/temp.py", line 11, in <module>
response = urllib.request.urlopen("http://www.baidu.com")
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\urllib\request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\urllib\request.py", line 525, in open
response = self._open(req, data)
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\urllib\request.py", line 542, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\urllib\request.py", line 502, in _call_chain
result = func(*args)
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\urllib\request.py", line 1379, in http_open
return self.do_open(http.client.HTTPConnection, req)
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\urllib\request.py", line 1354, in do_open
r = h.getresponse()
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\http\client.py", line 1332, in getresponse
response.begin()
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\http\client.py", line 303, in begin
version, status, reason = self._read_status()
File "C:\Users\lord\AppData\Local\Programs\Python\Python38-32\lib\http\client.py", line 272, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
中文翻译:
raise RemoteDisconnected("Remote end closed connection without http.client.RemoteDisconnected: Remote end closed connection without response
远程端未连接(没有http服务器,远程端关闭连接),远程端关闭连接,无响应。
解决方法:
网络参考资源:
网址:《爬虫过程报错:http.client.RemoteDisconnected: Remote end closed connection without response》
利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,因为服务器根据 UA 来判断拒绝了 python 爬虫。
把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
修改后的代码:
import urllib.request
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'}
# 代码001:
data1 = urllib.request.Request("https://www.bilibili.com", headers=headers)
data2 = urllib.request.urlopen(data1).read()
data3 = urllib.request.urlopen(data1)
data4 = urllib.request.urlopen(data1).read().decode('utf-8') #转码
print(data2)
# print(data3)
# print(data4)
# 代码002:(未声明headers,会报错)
# response = urllib.request.urlopen("http://www.baidu.com")
# print(response)
# print(response.read())
headers 获取方法(google):
打开google浏览器,查看网页源代码
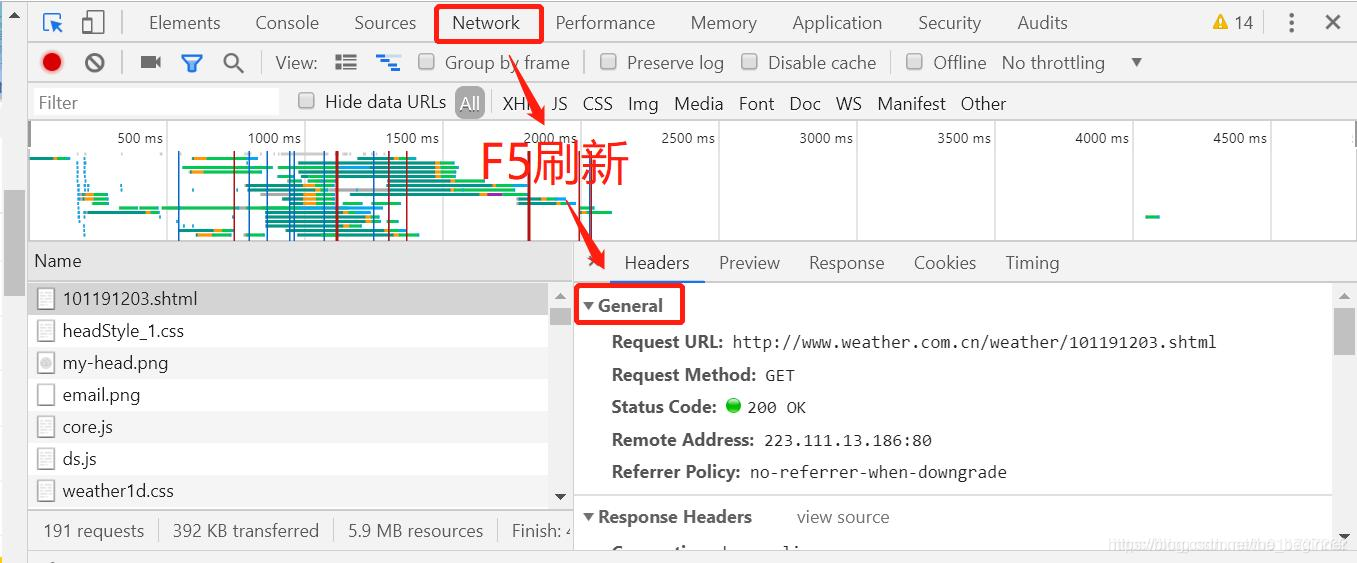
网络参考资源:
《python爬虫-通过chrome浏览器查看当前网页的http头》

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)