电影推荐算法及python实现
导读:推荐算法在电子商务如淘宝,个人社交如微博等方面起着重要的作用。随着这些网站的飞速发展,这种个人推荐服务得到了更广泛的应用,例如抖音短视频推荐算法可以根据用户的观看习惯进行精准投放。本人通过查阅资料简单介绍了目前的协同推荐算法,并完成了电影推荐算法的python实现,附源码及实验数据。一、协同过滤算法简介协同过滤推荐算法是当下各推荐平台运用最为广泛的推荐算法,自开始被应用以来就对推荐系统的发展
导读:推荐算法在电子商务如淘宝,个人社交如微博等方面起着重要的作用。随着这些网站的飞速发展,这种个人推荐服务得到了更广泛的应用,例如抖音短视频推荐算法可以根据用户的观看习惯进行精准投放。本人通过查阅资料简单介绍了目前的协同推荐算法,并完成了电影推荐算法的python实现,附源码及实验数据。
一、协同过滤算法简介
协同过滤推荐算法是当下各推荐平台运用最为广泛的推荐算法,自开始被应用以来就对推荐系统的发展具有长足的影响。协同过滤的核心思想是根据与目标用户的兴趣偏好相似的最近邻的偏好来进行推荐。
协同过滤推荐算法可划分为两种,一种是基于内存的协同过滤,包括基于用户(user-based)的协同过滤推荐算法和基于物品(item-based)的协同过滤推荐算法,此类算法原理相对简单,适合初学者入门学习。另一种是基于模型(model-based)的协同过滤推荐算法,采用统计、机器学习等方法,通过目标用户的历史偏好搭建用户模型并据此进行推荐,此类方法需要采集大量的用户数据,对于初学者来说并不友好,本文不再详细介绍。
1.1基于用户(user-based)的协同过滤推荐算法
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对视频内容的喜欢(如视频点赞,收藏,内容评论或分享),并对这些喜好进行度量和打分。根据不同用户对具有相同视频内容的态度和偏好程度计算用户之间的关系,在有相同喜好的用户间进行商品推荐。
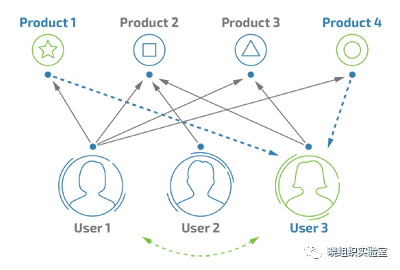
图1 user-based协同过滤推荐算法示意图
在user-based协同过滤推荐算法中,user1和user3都收藏了product2和product3,通过对user的相似度计算,两者具有相近的距离。在后续的推荐过程中,user1独有的收藏视频product1和product4会被推荐给user3。
1.2基于物品(item-based)的协同过滤推荐算法
与user-based相似,Iterm-based也需要相似性计算,只不过user-based是针对于用户进行的,而Iterm-based是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。
在图1中,Iterm-based方法以product为分析对象,对于product2,只要关注过product2的用户,同样会关注product3,两者将会被认为是同一类型。在对于user2进行推荐时,会根据其历史关注记录product2,推荐出同一类型的product3。
1.3优缺点对比
user-based的协同过滤推荐算法的最大优点是对推荐对象的结构没有特殊的要求,能够处理非结构化对象,如图片、音乐、电影等。再者,user-based的协同过滤具有可以推荐新内容的优点,能发掘在内容上截然不同的信息,用户对被推荐物品的内容信息也是事先无法预见的。这同时也是协同过滤推荐算法和Iterm-based推荐的一个很大的区别。
在一些场景中,用户数量远不如项目数量,项目维度远远高于用户维度。同时,用户兴趣爱好较为模糊,对于各类项目都会进行关注。因此,选择基于用户的方法能够大大降低空间复杂度。同时,如果项目的更新速度快,时效性要求高,如果采用Iterm-based的方法,新闻作为项目维度,不断更新项目相似度是不现实的。
在电子商务平台上,用户数量一般远远高于商品数量,用户维度远高于项目维度。同时商品没有很强的时效性,基于实际考虑,更适合采用基于项目的协同过滤推荐算法。
二、User-based协同过滤算法python实现
在电影推荐中,电影的数量远远大于用户的有效评价信息,采用Iterm-based的协同过滤算法带来了巨大的计算量以及较低的精度,为此我们选择了user-based的协同过滤算法进行电影推荐。
User-based协同过滤算法进行电影推荐分为三个阶段,第一个阶段利用用户的历史信息构建用户-电影评分矩阵。第二阶段通过选择合适的相似度公式对构建的评分矩阵计算用户之间的相似性。第三阶段,通过第三阶段得到用户间的相似性,利用近邻用户与当前用户间已评论电影的差异,利用预测公式进行预测。
2.1用户-电影评分矩阵的构建
我们从网络中获得到MovieLens数据集对用户-电影评分矩阵进行构建,数据集中包含610个用户对不同电影的10万个评分,分值为1至5,不同的用户通过电影ID相互联系,如下表所示:
表1 用户-电影评分矩阵
| 电影ID 用户ID | 1 | 2 | 3 | 4 | 5 | …… |
| 1 | 4 | 4 | ||||
| 2 | 2 | |||||
| 3 | 3 | |||||
| 4 | 5 | |||||
| 5 | 4 | |||||
| …… | …… | …… | …… | …… | …… | …… |
python代码如下:
"""
新建一个data字典存放每位用户评论的电影和评分, 如果字典中没有某位用户,则使用用户ID来创建这位用户,否则直接添加以该用户ID为key字典中
"""
file = open("./ml-latest-small/data.csv",'r', encoding='UTF-8')
data = {}
for line in file.readlines():
line = line.strip().split(',')
if not line[0] in data.keys():
data[line[0]] = {line[3]:line[1]}
else:
data[line[0]][line[3]] = line[1]
2.2寻找近邻用户
对于不同用户之间的相似性,常常通过简单的欧式距离进行计算[2],我们将采用person系数,也称为皮尔森积矩相关系数,对不同用户间的相似性进行计算。对于不同的用户,person系数取值在[-1,1]之间,如果person系数接近于1,则表示两个用户之间具有强相关性,两者对电影具有相同的个人喜好。当person系数接近于-1时,两个用户间完全负相关,及表示两人对电影的喜好完全对立。Person系数为0时,表示两个用户对电影的个人喜好并没有太多的联系。计算公式如下:
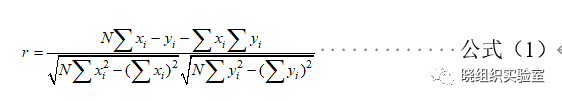
其中r表示person系数,i表示电影的编号,x和y分表表示两个不同的用户。对于每一位用户,我们通过person系数排序并筛选前10个用户作为近邻用户,根据他们对电影的评分进行电影的推荐。
2.3电影推荐
针对我们将要推荐的用户,我们通过近邻用户间的评分进行预测,预测公式如下:

如公式2所示,p为用户x对电影m的预测评分,s表示用户x的近邻用户,在本文中数量为10个。目标用户的近邻集合为Im。我们将最终得到的预测结果放到统一的集合中,并将预测结果进行降序排序,得到最终的电影推荐结果,并将结果输出。
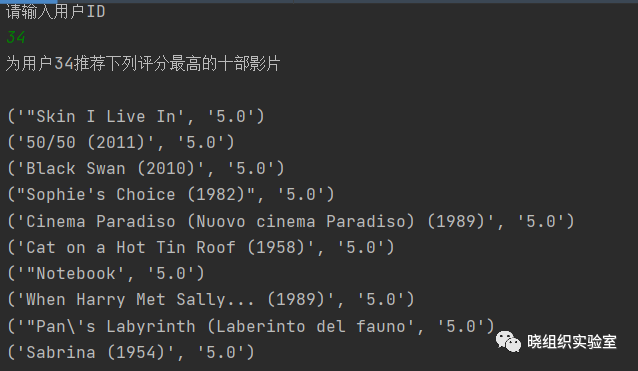
程序运行结果如下:
本文只提供了欧式距离的算法,如果需要,可更改Euclidean,用numpy函数内的pccs = np.corrcoef(x, y)进行替换,完整代码如下:
import pandas as pd
from math import *
import numpy as np
"""
读取movies文件,设置列名为’videoId', 'title', 'genres'
读取ratings文件,设置列名为'userId', 'videoId', 'rating', 'timestamp'
通过两数据框之间的 videoId 连接
保存'userId', 'rating', 'videoId', 'title'为data数据表
"""
movies = pd.read_csv("./ml-latest-small/movies.csv", names=['videoId', 'title', 'genres'])
ratings = pd.read_csv("./ml-latest-small/ratings.csv",names=['userId', 'videoId', 'rating', 'timestamp'])
data = pd.merge(movies, ratings, on='videoId')
data[['userId', 'rating', 'videoId', 'title']].sort_values('userId').to_csv('./ml-latest-small/data.csv',index=False)
"""
新建一个data字典存放每位用户评论的电影和评分, 如果字典中没有某位用户,则使用用户ID来创建这位用户,否则直接添加以该用户ID为key字典中
"""
file = open("./ml-latest-small/data.csv",'r', encoding='UTF-8')
data = {}
for line in file.readlines():
line = line.strip().split(',')
if not line[0] in data.keys():
data[line[0]] = {line[3]:line[1]}
else:
data[line[0]][line[3]] = line[1]
"""
找到两位用户共同评论过的电影,然后计算两者之间的欧式距离,最后算出两者之间的相似度,欧式距离越小两者越相似
"""
def Euclidean(user1, user2):
user1_data = data[user1]
user2_data = data[user2]
distance = 0
for key in user1_data.keys():
if key in user2_data.keys():
distance += pow(float(user1_data[key]) - float(user2_data[key]), 2)
return 1 / (1 + sqrt(distance))
"""
计算某个用户与其他用户的相似度
"""
def top_simliar(userID):
res = []
for userid in data.keys():
# 排除与自己计算相似度
if not userid == userID :
simliar = Euclidean(userID, userid)
res.append((userid, simliar))
res.sort(key=lambda val: val[1])
return res[:4]
"""
从控制台输入需要推荐的用户ID,如果用户不在原始数据集中则报错,重新输入
"""
getIdFlag = 0
while not getIdFlag:
inputUid = str(input("请输入用户ID\n"))
try:
uid = data[inputUid]
getIdFlag = 1
except Exception:
print("用户ID错误,请重新输入\n")
"""
根据与当前用户相似度最高的用户评分记录,按降序排列,推荐出改用户还未观看的评分最高的10部电影
"""
def recommend(user):
top_sim_user = top_simliar(user)[0][0]
items = data[top_sim_user]
recommendations = []
for item in items.keys():
if item not in data[user].keys():
recommendations.append((item, items[item]))
recommendations.sort(key=lambda val: val[1], reverse=True) # 按照评分排序
return recommendations[:10]
"""
根据输入的用户ID,输出为他推荐的影片
"""
Recommendations = recommend(inputUid)
print("为用户" + inputUid + "推荐下列评分最高的十部影片\n")
for video in Recommendations:
print(video)
此数据集可在官网搜索查看https://grouplens.org/datasets/movielens/
也可以添加公众号免费获取


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)