sklearn库
sklearn库sklearn 是 scikit — learn 的简称,是一个基于 Python 的第三方模块。 sklearn 库集成了一些常用的机器学习方法,在进行机器学习任务时,并不需要实现算法,只需要简单的调用 sklearn 库中提供的模块就能完成大多数的机器学习任务。sklearn 库是在 Numpy 、 Scipy 和 matplotlib 的基础上开发而成的,因此在介绍 skle
·
sklearn库
sklearn 是 scikit — learn 的简称,是一个基于 Python 的第三方模块。 sklearn 库集成了一些常用的机器学习方法,在进行机器学习任务时,并不需要实现算法,只需要简单的调用 sklearn 库中提供的模块就能完成大多数的机器学习任务。
sklearn 库是在 Numpy 、 Scipy 和 matplotlib 的基础上开发而成的,因此在介绍 sklearn 的安装前,需要先安装这些依赖库。
Sklearn 内置数据集
鸢尾花(iris)数据集
#导入鸢尾花数据集
from sklearn.datasets import load_iris
iris=load_iris()
结果:
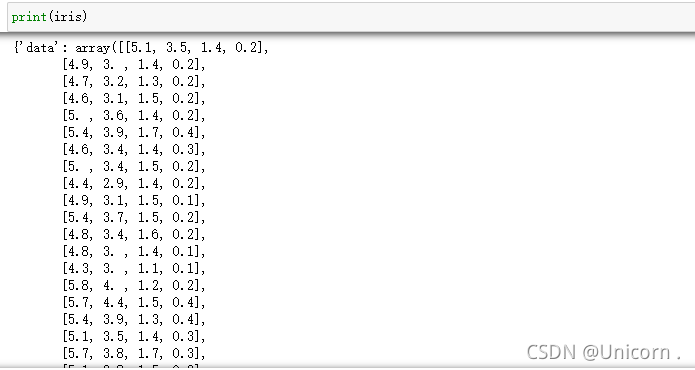
应用
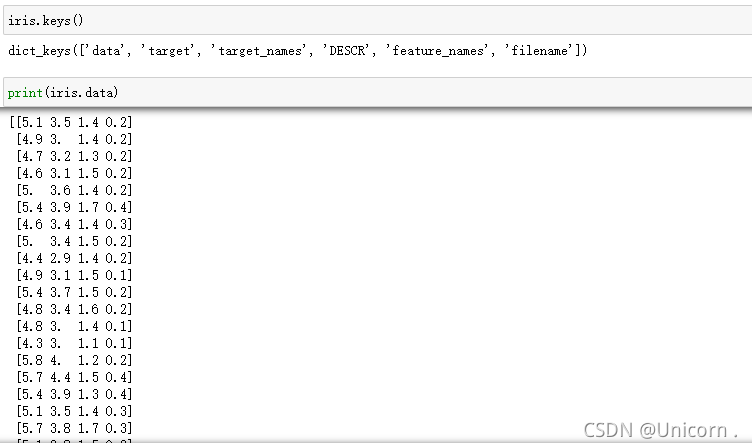
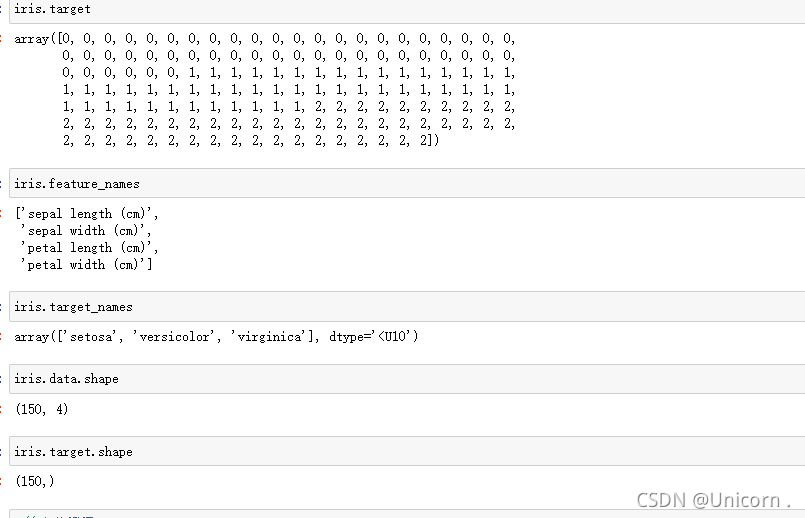
#转为数据框
import pandas as pd
iris_df=pd.DataFrame(iris.data,columns=iris.feature_names)
iris_df
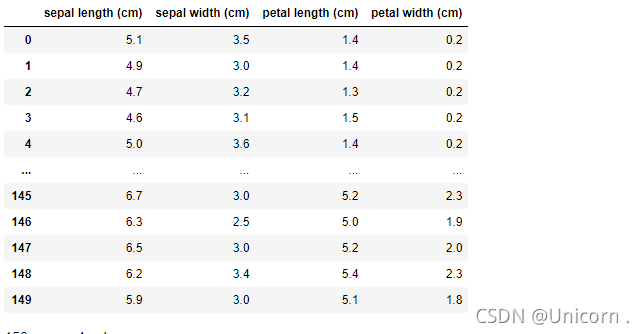
#return_X_y=True,直接返回pandas中的数据类型
iris_X,iris_y=load_iris(return_X_y=True)
print(type(iris_X))
type(iris_y)
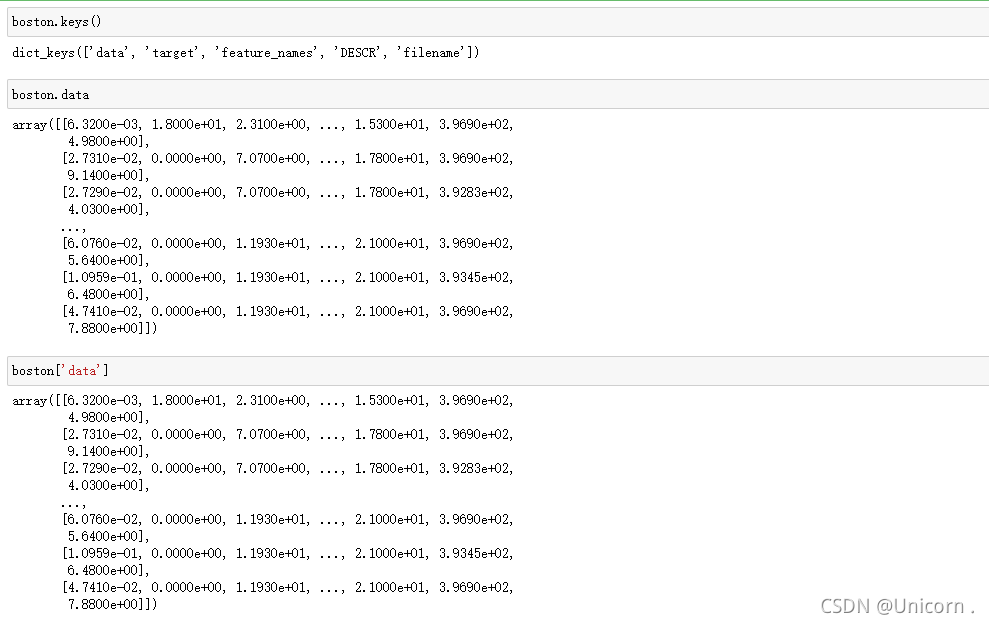
波斯顿房价数据集
from sklearn import datasets
boston=datasets.load_boston()
boston
sklearn 基础操作
sklearn"三板斧"
1.实例化 2.fit 3.transform or predict
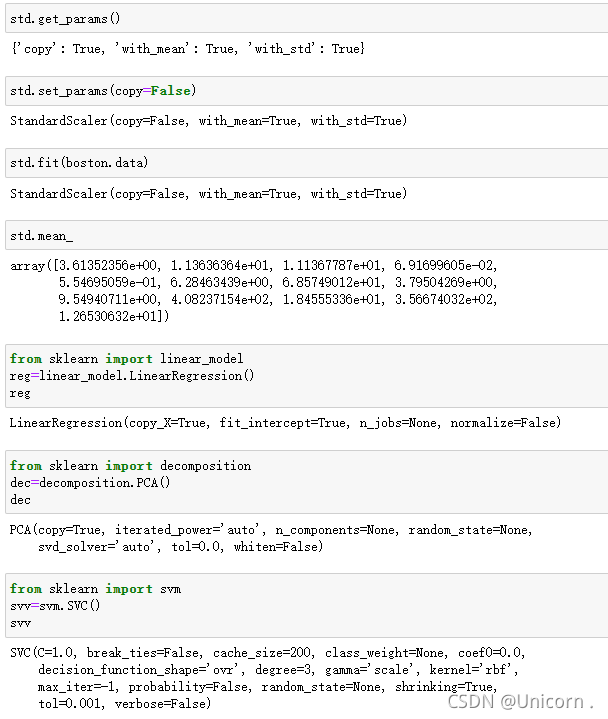
#实例化
from sklearn import preprocessing
std=preprocessing.StandardScaler()
std
数据拆分的sklearn实现
sklearn,model_selection.train_test_split()
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
boston=load_boston()
x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target,test_size=0.3,random_state=123)
len(x_train),len(x_test),len(y_train),len(y_test)
结果:

sklearn实现决策树
class sklearn.tree.DecisionTreeClassifier()
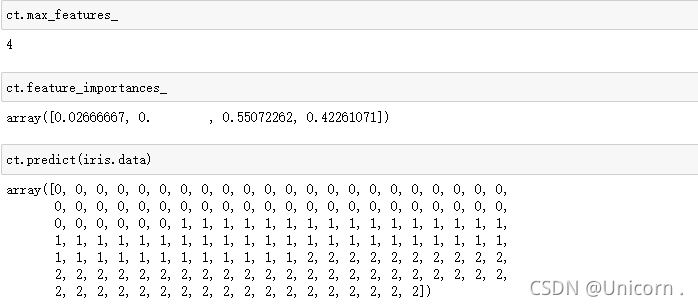
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
iris=load_iris()
ct=DecisionTreeClassifier()
ct.fit(iris.data,iris.target)

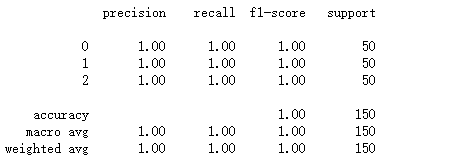
from sklearn.metrics import classification_report
print(classification_report(iris.target,ct.predict(iris.data)))

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)