【数据分析与挖掘实战】B站影视区数据分析
一.分析目标与内容B站作为一个视频内容平台,具有广泛的受众,其数据具有巨大的分析价值。在本次数据分析项目中,分别从视频角度和up主角度对B站影视区数据集进行了分析,通过描述性统计,维度拆解,聚类等方式进行了较为全面的分析。在分析过程中,特别关注了原创或搬运这个特征,并发现了一些有趣的结论。二.数据来源链接:点击获取提取码:srtc三.数据导入与基本情况查看import numpy as npimp
一.分析目标与内容
B站作为一个视频内容平台,具有广泛的受众,其数据具有巨大的分析价值。在本次数据分析项目中,分别从视频角度和up主角度对B站影视区数据集进行了分析,通过描述性统计,维度拆解,聚类等方式进行了较为全面的分析。在分析过程中,特别关注了原创或搬运这个特征,并发现了一些有趣的结论。
二.数据来源
链接:点击获取
提取码:srtc
三.数据导入与基本情况查看
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import time, datetime
from pyecharts import options as opts
from pyecharts.charts import Bar, Grid, Line,Page,Radar,Pie
warnings.filterwarnings("ignore")
%matplotlib notebook
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
pd.set_option('display.float_format',lambda x : '%.5f' % x)
np.set_printoptions(suppress=True, precision=20, threshold=10, linewidth=40)
df=pd.read_csv(r'/home/mw/input/bilibili2562/影视data_2021-11-15.csv')
df.head()

df.describe()

df.isnull().sum()

df.info()

四.数据预处理
数据预处理部分主要是将时间戳变为方便处理的时间格式,并将每一个视频的时间转化为秒,以方便后续的分析
#将数据改为时间格式
df['length_minute']=df['length'].apply(lambda x: x.split(':')[0]).astype('float')
df['length_second']=df['length'].apply(lambda x: x.split(':')[1]).astype('float')
df['length_trans']=df['length_minute']*60+df['length_second']
df['play']=df['play'].replace('--',0)#有的播放量是--,要替换成0
df['play']=df['play'].astype('float')
# 将时间戳转变为时间格式
df['created']=df['created'].apply(lambda x:time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(int(x))))
print('最早视频发布时间:'+df['created'].min())#最早发布时间
print('最晚视频发布时间:'+df['created'].max())#最后发布时间
print(df[df['copyright']==1]['record_time'].count())#1为原创
print(df[df['copyright']==2]['record_time'].count())#2为搬运
df['year']=df['created'].apply(lambda x: x.split('-')[0])#分离年
df['month']=df['created'].apply(lambda x: x.split('-')[1])#分离月
df['day']=df['created'].apply(lambda x: x.split('-')[2].split(' ')[0])#分离日
df['hour']=df['created'].apply(lambda x: x.split('-')[2].split(' ')[1].split(':')[0])#分离分钟

五.数据分析与可视化
5.1视频发布量变化
5.1.1 按年月分解
year_month_group=df.groupby(by=['year','month'])['play'].count()#按照年月聚合查看各月发稿个数
year_month_day_group=df.groupby(by=['year','month','day'])['play'].count()#按照年月日聚合查看各天发稿个数
year_month_group=year_month_group.reset_index()
year_month_group['year_month']=year_month_group['year']+year_month_group['month']
year_month_day_group=year_month_day_group.reset_index()
year_month_day_group['year_month']=year_month_day_group['year']+year_month_day_group['month']
#按照年_月拆解
x1=year_month_group[year_month_group['year']=='2021']['year_month']
y1=year_month_group[year_month_group['year']=='2021']['play'].reset_index(drop=True)
x2=year_month_group[year_month_group['year']=='2020']['year_month']
y2=year_month_group[year_month_group['year']=='2020']['play']
x3=year_month_group[year_month_group['year']=='2019']['year_month']
y3=year_month_group[year_month_group['year']=='2019']['play']
line1=(
Line(init_opts=opts.InitOpts(width='720px', height='320px')) #设置画布大小
.add_xaxis(['1月','2月','3月','4月','5月','6月','7月','8月','9月','10月','11月','12月'])
.add_yaxis('2021视频量',list(y1))
.add_yaxis('2020视频量',y2)
.add_yaxis('2019视频量',y3)
.set_global_opts(title_opts=opts.TitleOpts(title="2019-2021各月视频量分析"))
)
line1.render_notebook()

不难发现,B站影视区的投稿量在19、20、21年是处于上升的趋势。但是21年的视频投稿数量有较大的波动,在3月份有一个很明显的上升,4月份又出现了回落,此后不断攀升,在8月份达到极值。8月份是暑期,投稿数量达到巅峰可以理解,但未什么3月份投稿数量会有明显波动呢?
我们对三月份这种投稿数量的变化产生了兴趣,下面分析为什么会产生这种波动。
5.1.2 按照日期进行拆解
#按照年_月_日拆解
year_month_202103=year_month_day_group[year_month_day_group['year_month']=='202103']
year_month_202104=year_month_day_group[year_month_day_group['year_month']=='202104']
year_month_202108=year_month_day_group[year_month_day_group['year_month']=='202108']
year_month_202102=year_month_day_group[year_month_day_group['year_month']=='202102']
year_month_202111=year_month_day_group[year_month_day_group['year_month']=='202111']
y_202103=year_month_202103['play']
y_202108=year_month_202108['play']
y_202104=year_month_202104['play']
y_202111=year_month_202111['play']
y_202102=year_month_202102['play']
x=[]
for i in range(1,32):
x.append(str(i))
line202103=(
Line(init_opts=opts.InitOpts(width='720px', height='320px')) #设置画布大小
.add_xaxis(x)
.add_yaxis('2021年3月视频量',list(y_202103))
.add_yaxis('2021年4月视频量',list(y_202104))
.add_yaxis('2021年2月视频量',list(y_202102))
.set_global_opts(title_opts=opts.TitleOpts(title="视频量分析"))
)
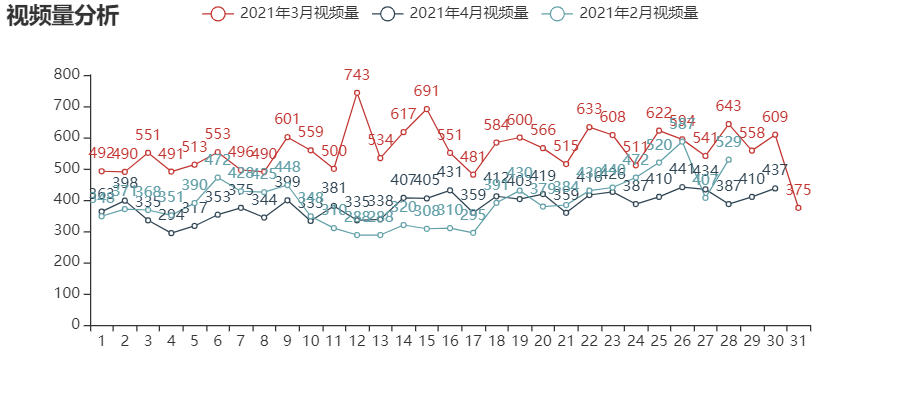
line202103.render_notebook()

可以看到,几乎三月的每一天都比2月份和4月份同期的发稿量多,这样,我们推测可能3月份出现了投稿激励的活动,使得投稿活动变得更加积极。
5.1.3 按照是否原创进行拆解
year_month_day_group_origin=df[df['copyright']==1].groupby(by=['year','month','day'])[['play']].count()#按照年月聚合查看各月原创发稿个数
year_month_day_group_copy=df[df['copyright']==2].groupby(by=['year','month','day'])[['play']].count()#按照年月聚合查看各月搬运视频发稿个数
year_month_day_group_origin=year_month_day_group_origin.reset_index()
year_month_day_group_origin['year_month']=year_month_day_group_origin['year']+year_month_day_group_origin['month']
year_month_day_group_copy=year_month_day_group_copy.reset_index()
year_month_day_group_copy['year_month']=year_month_day_group_copy['year']+year_month_day_group_copy['month']
#按照年_月_日拆解
year_month_202103=year_month_day_group_origin[year_month_day_group_origin['year_month']=='202103']
year_month_202104=year_month_day_group_origin[year_month_day_group_origin['year_month']=='202104']
year_month_202108=year_month_day_group_origin[year_month_day_group_origin['year_month']=='202108']
year_month_202102=year_month_day_group_origin[year_month_day_group_origin['year_month']=='202102']
y_202103=year_month_202103['play']
y_202108=year_month_202108['play']
y_202104=year_month_202104['play']
y_202102=year_month_202102['play']
line_origin=(
Line(init_opts=opts.InitOpts(width='720px', height='320px')) #设置画布大小
.add_xaxis(x)
.add_yaxis('2021年3月视频量',list(y_202103))
.add_yaxis('2021年4月视频量',list(y_202104))
.add_yaxis('2021年2月视频量',list(y_202102))
.set_global_opts(title_opts=opts.TitleOpts(title="原创视频量分析"))
)
#按照年_月_日拆解
year_month_202103_c=year_month_day_group_copy[year_month_day_group_copy['year_month']=='202103']
year_month_202104_c=year_month_day_group_copy[year_month_day_group_copy['year_month']=='202104']
year_month_202108_c=year_month_day_group_copy[year_month_day_group_copy['year_month']=='202108']
year_month_202102_c=year_month_day_group_copy[year_month_day_group_copy['year_month']=='202102']
y_202103_c=year_month_202103_c['play']
y_202108_c=year_month_202108_c['play']
y_202104_c=year_month_202104_c['play']
y_202102_c=year_month_202102_c['play']
line_copy=(
Line(init_opts=opts.InitOpts(width='720px', height='320px')) #设置画布大小
.add_xaxis(x)
.add_yaxis('2021年3月视频量',list(y_202103_c))
.add_yaxis('2021年4月视频量',list(y_202104_c))
.add_yaxis('2021年2月视频量',list(y_202102_c))
.set_global_opts(title_opts=opts.TitleOpts(title="搬运视频量分析"))
)
page=Page()
page.add(line_copy)
page.add(line_origin)
page.render_notebook()


从图中不难看出,3月份视频量的激增,主要是由于搬运视频量的激增,看来激励的其实是大家水视频的力度,嘿嘿
5.2 视频发布时间分析
df_hour=df.groupby(by='hour')['mid'].count()
x=[]
for i in range(0,24):
x.append(str(i))
line_hour=(
Line(init_opts=opts.InitOpts(width='720px', height='320px')) #设置画布大小
.add_xaxis(x)
.add_yaxis('视频数',list(df_hour))
.set_global_opts(title_opts=opts.TitleOpts(title="发布视频时间分析"))
)
line_hour.render_notebook()

从视频发布时间来看,高峰期主要在10-12点以及17-18点,看来大家都喜欢吃饭下班之前传个视频,嘿嘿
5.3 原创视频与搬运视频分析
#查看原创和非原创视频个数
#设置行名
columns = ["是", "否"]
#设置数据
data1 = df.groupby(by='copyright')['pic'].count()
bar = (
Bar()
.add_xaxis(columns)
.add_yaxis("视频数", list(data1))
.set_global_opts(title_opts=opts.TitleOpts(title="是否原创"))
)
bar.render_notebook()

总体来看,原创视频和搬运视频量并没有很大的差异,原创视频属略大于搬运视频数
df_copyright_year=df.groupby(by=['year','copyright'])[['mid']].count()
df_copyright_year.reset_index(inplace=True)
# new=pd.DataFrame({'year':'2011',
# 'copyright':1,
# 'mid':0},index=[1])
#df_copyright_year=df_copyright_year.append(new)
df_copyright_year.rename(columns={'mid':'play'},inplace=True)
df_copyright_year

percent_copyright=df.groupby(by='year')[['mid']].count().reset_index()
df_copyright_year=pd.merge(df_copyright_year,percent_copyright,on='year',how='left')
df_copyright_year['copy_percent']=round(df_copyright_year['play']/df_copyright_year['mid'],2)#原创率、搬运率
df_copyright_year

x=df_copyright_year['year'].drop_duplicates()
y_0=[0]#第一年原创为0
y1=y_0+list(df_copyright_year[df_copyright_year['copyright']==1]['play'])
y2=df_copyright_year[df_copyright_year['copyright']==2]['play']
y_copy_percent=df_copyright_year[df_copyright_year['copyright']==2]['copy_percent']
print(y1)
#设置行名
columns = ["是", "否"]
#设置数据
data1 = df.groupby(by='copyright')['pic'].count()
bar = (
Bar()
.add_xaxis(list(x))
.add_yaxis("原创", list(y1))
.add_yaxis("非原创", list(y2))
.set_global_opts(title_opts=opts.TitleOpts(title="是否原创"))
)
line_copyright=(
Line(init_opts=opts.InitOpts(width='720px', height='320px')) #设置画布大小
.add_xaxis(list(x))
.add_yaxis('搬运率',list(y_copy_percent))
.set_global_opts(title_opts=opts.TitleOpts(title="搬运率分析"))
)
page=Page()
page.add(bar)
page.add(line_copyright)
page.render_notebook()

接下来将原创分析细化到以年为单位,发现搬运率呈现一个“w”形的趋势,即“下降-上升-下降-上升”的趋势。如果聚焦到近几年来说,视频搬运率处于一个上升的态势,可能是因为视频搬运的成本低,获利高。国内政策目前是鼓励原创视频,因此我们应该思考如何进一步鼓励原创视频,而不是让搬运视频的风气进一步扩散。
5.4以up主为主体的数据分析
5.4.1up主特征提取
year_month_group=df.groupby(by=['author','year','month','mid'])[['play']].count()#按照年月和作者聚合查看各月各个作者发稿个数
year_month_group=year_month_group.reset_index()
year_month_group.rename(columns={'play':'number'},inplace=True)
year_month_group.head()

current_time=datetime.date(2021, 11, 15) #爬虫的爬取数据的时间
#up主最近一个视频到当天的间隔R
df['year_month_day']=df['created'].apply(lambda x: x.split(' ')[0])
df['year_month_day']=df['year_month_day'].apply(lambda x :datetime.datetime.strptime(x, '%Y-%m-%d').date())
up_inform=df.groupby(by='author')[['year_month_day']].max()
up_inform.reset_index(inplace=True)
up_inform['last_till_now']=up_inform['year_month_day'].apply(lambda x:(current_time-x).days)
#up主视频平均播放量
df_mean_view=df.groupby(by='author')[['play']].mean()
#注意设置as_index = False,否则mean_view为nan(因为赋值是根据索引匹配,as_index = True时索引为author,无法与up_inform的index匹配)
up_inform['mean_view']=df.groupby(by='author',as_index = False).mean()['play']
#up主发第一个视频到现在的间隔
up_inform['first_time']=df.groupby(by='author',as_index = False).min()['year_month_day']
up_inform['first_till_now']=up_inform['first_time'].apply(lambda x:(current_time-x).days)
#up主发视频的视频量
up_inform['video_number']=df.groupby(by='author',as_index = False).count()['mid']
#up主发视频的平均间隔(第一个视频到最后一个视频的间隔/视频量)
up_inform['mean_gap']=(up_inform['first_till_now']-up_inform['last_till_now'])/up_inform['video_number']
#up主每个视频的平均评论数目
up_inform['mean_comment']=df.groupby(by='author',as_index = False).sum()['comment']/up_inform['video_number']
#up主每个视频的平均弹幕
up_inform['mean_video_review']=df.groupby(by='author',as_index = False).sum()['video_review']/up_inform['video_number']
#up主发视频的平均时间
up_inform['mean_video_length']=df.groupby(by='author',as_index = False).sum()['length_trans']/up_inform['video_number']
#up主发视频原创或是搬运
up_inform['copyright']=df.groupby(by='author',as_index = False).sum()['copyright']/up_inform['video_number']
#删除日期列
up_inform=up_inform.drop(['year_month_day','first_time'], axis=1)
up_inform.head()

5.4.2相关性分析
#绘制up主视频信息的热力图
%matplotlib inline
plt.figure(figsize=(10,8))
data_heat=up_inform.iloc[:,1:]
df_corr = data_heat.corr()
sns.heatmap(df_corr, annot=True, fmt='.2f')
plt.show()

从热力图来看,up主平均视频弹幕量和平均视频评论量有较大的关系,弹幕数和平均视频播放量也有较大的相关度。值得注意的是,视频的平均发布数量和原创程度也有一定程度的关系,平均发布视频越多的up主越可能是搬运up主。
5.5up主聚类分析
这里借用“RFM”模型的思路,选出了up主上一次发布视频距今的天数,平均发视频的间隔,平均视频播放量作为特征输入K-Means模型进行分类,同时加入了我们感兴趣的一个变量——是否原创,来进行更细致的分类。大家也可以进一步选择合适的特征进行聚类分析。
在这里,分析采用轮廓系数判断聚类的好坏。轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。
轮廓系数确定方法:
- 计算样本i到同簇其他样本的平均距离ai。ai 越小,说明样本i越应该被聚类到该簇。将ai 称为样本i的簇内不相似度。簇C中所有样本的a i 均值称为簇C的簇不相似度。
- 计算样本i到其他某簇Cj 的所有样本的平均距离bij,称为样本i与簇Cj 的不相似度。定义为样本i的簇间不相似度:bi =min{bi1, bi2, …,bik},bi越大,说明样本i越不属于其他簇。
- 根据样本i的簇内不相似度a i 和簇间不相似度b i ,定义样本i的轮廓系数每个样本的轮廓系数计算公式为:(b-a)/Max(a,b)。轮廓系数越接近1说明结果越好(聚类越准确),越接近-1说明结果越差,若值在0值附近,则说明样本在两个簇的边界上。
sklearn中调用:
sklearn.metrics.silhouette_score(X, labels, metric=‘Euclidean’,sample_size=None, random_state=None, **kwds)返回所有样本的平均轮廓系数。
# 从sklearn导入聚类算法函数
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
data_heat=up_inform[['last_till_now','mean_view','mean_gap','copyright']]#选取的up主特征
#标准化处理
upZscore = (data_heat - data_heat.mean(axis=0)) /data_heat.std(axis=0)
upZscore.columns = ['Z' + i for i in upZscore.columns]
Z_result_list=list(upZscore.columns)
upZscore.head()
random_state = 5
score = []
inertia = []
nums=range(2,10)
# 遍历多个可能的候选簇数量
for n_clusters in range(2,10):
kmeans = KMeans(n_clusters=n_clusters, random_state=random_state)
kmeans.fit(upZscore)
inertia.append(kmeans.inertia_)#inertia:整体簇内平方和
score.append(silhouette_score(upZscore, kmeans.labels_,sample_size=128, metric='euclidean')) #衡量聚类算法的指标:轮廓系数
plt.figure(figsize=(10, 6))
plt.plot(nums,score)
plt.grid(linestyle=':')
plt.xlabel('K')
plt.ylabel('Score')
plt.title('Performance of K-means')

由聚类结果可视化可知,最佳的聚类数为4左右
在一部分,定义一个方法,通过该方法,我们可以通过输入标准化后的up主特征dataframe,需要聚类的个数以及选择的聚类特征,便可以直接进行K-Means聚类并绘制雷达图。
#k-means建模以及绘制结果雷达图
def k_means_radar(upZscore,n_Cluster,result_list):
#初始化Kmeans模型
kmodel = KMeans(n_clusters=n_Cluster)
kmodel.fit(upZscore)#训练模型
#处理模型数据形成一个绘图用的dataframe
kmeansCenters = pd.DataFrame(kmodel.cluster_centers_, columns = upZscore.columns)
labelsCounts = pd.DataFrame(kmodel.labels_)[0].value_counts()
kmeansLabels = pd.DataFrame(labelsCounts, index = None)
kmeansLabels.columns = ['Num']
kmeansResult=[]
kmeansResult = pd.concat([kmeansCenters, kmeansLabels], axis=1)
cluster_name=['群体1']
for i in range(2,n_Cluster+1):
cluster_name.append('群体'+str(i))
kmeansResult['Class']=cluster_name
# print(kmeansResult)
change_c=['Class','Num']
#改变一下列的顺序
for i in result_list:
change_c.append(i)
kmeansResult = kmeansResult[change_c]
kmeansResult0 = pd.concat([kmeansResult,kmeansResult[[result_list[0]]]],axis=1)#这里要多一列,以便绘制雷达图
#print(kmeansResult0)
#绘制雷达图
fig =plt.figure(figsize=(12,10))
ax = plt.subplot(121,polar = True)
plot=kmeansResult0.iloc[:,2:len(result_list)+3]#绘图的数据,前两列是类别和数量所以不用
angles=np.linspace(0,2*np.pi,len(result_list)+1,endpoint =True)
for i in range(0,n_Cluster):
print(plot.iloc[i])
ax.plot(angles, plot.loc[i],'o--',label = 'class'+str(i+1))
#print(result_list)
result_list.append(result_list[0])
ax.set_thetagrids(angles * 180/np.pi,result_list)
plt.legend(loc='lower right', bbox_to_anchor=(1.5, 0.0))
plt.title('Radar of client')
ax2 = plt.subplot(122)
plt.subplots_adjust(wspace = 1 )
labels = kmeansResult['Class']
sizes = kmeansResult['Num']
plt.pie(sizes,labels=labels,autopct='%1.1f%%',shadow=False,startangle=150)
plt.title("客户群体比例")
plt.show()
plt.show()
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
Z_result_list=list(upZscore.columns)
kmeans_n=4
k_means_radar(upZscore,kmeans_n,Z_result_list)

通过雷达图可知,up主被分成了4类,下面总结如下:
**普通up。**这是小up群体,其视频平均发布间隔一般(这里由于特征处理的原因,也可能是只发布过一条视频,需要进一步确定),视频播放量较少,最近有发布视频,是占比最大的一个群体。对于他们,我们需要进一步增加其曝光度,提高其知名度,让他们也能有发挥的空间。
**需要挽回的up。**这一类up的最大特点是视频的平均播放量较大,但是距离上一次发布时间较长。
**大水王up。**这一类up搬运视频较多,活跃度较大,但是视频质量不高,平均视频播放量较低,属于需要整治的up。
**沉默up。**这一类up的平均发视频间隔较长,距今也有一段时间没有发视频,需要分析其不活跃的原因,通过活动等手段唤醒其发视频的欲望。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 8
8 1
1- 1



 已为社区贡献4条内容
已为社区贡献4条内容
 免费领云主机
免费领云主机



 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(1)