python读取excel指定的列并将内容保存为txt内容
1.需要的python库pip install xlrd2.读取excel指定的列并将内容保存为txt内容代码如下:# coding:utf-8import xlrd# 读取excel文件需要的库def strs(row):values = ""for i in range(len(row)):if i == len(row) - 1:values = values + str(row[i])
·
1.需要的python库
pip install xlrd
2.读取excel指定的列并将内容保存为txt内容
代码如下:
# coding:utf-8
import xlrd # 读取excel文件需要的库
def strs(row):
values = ""
for i in range(len(row)):
if i == len(row) - 1:
values = values + str(row[i])
else:
values = values + str(row[i])
return values
# 打开文件
data = xlrd.open_workbook("data.xlsx") # 旧版xlrd
sqlfile = open("name.txt", "a") # 文件读写方式是追加
table = data.sheets()[2] # 表头,第几个sheet表-1
nrows = table.nrows # 行数
ncols = table.ncols # 列数
colnames = table.row_values(1) # 某一行数据
# 打印出行数列数
for ronum in range(1, nrows):
row = table.cell_value(rowx=ronum, colx = 2) # 只需要修改你要读取的列数-1
values = strs(row) # 调用函数,将行数据拼接成字符串
sqlfile.writelines(values + "\n") # 将字符串写入新文件
sqlfile.close() # 关闭写入的文件
3.结果如下
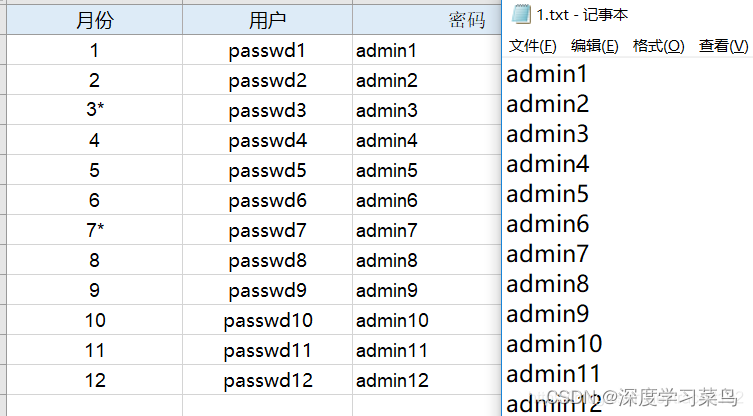
4.报错解决
- 安装最新版本的xlrd可能会报错:xlrd.biffh.XLRDError: Excel xlsx file; not supported
原因是xlrd更新了版本,只支持.xls文件。所以xlrd.open_workbook(“data.xlsx”)会报错。
可以安装旧版xlrd,在cmd中运行:
pip uninstall xlrd # 卸载
pip install xlrd==1.2.0 # 安装指定版本
- 使用python3.9读取excel时报错AttributeError: ‘ElementTree’ object has no attribute ‘getiterator’
出现错误的原因
在新版python3.9中,windows中使用的更新删除了getiterator方法,所以我们老版本的xlrd库调用getiterator方法时会报错。AttributeError: ‘ElementTree’ object has no attribute ‘getiterator’
解决方法
windows中找出目录Anaconda\Lib\site-packages\xlrd下的xlsx.py文件,
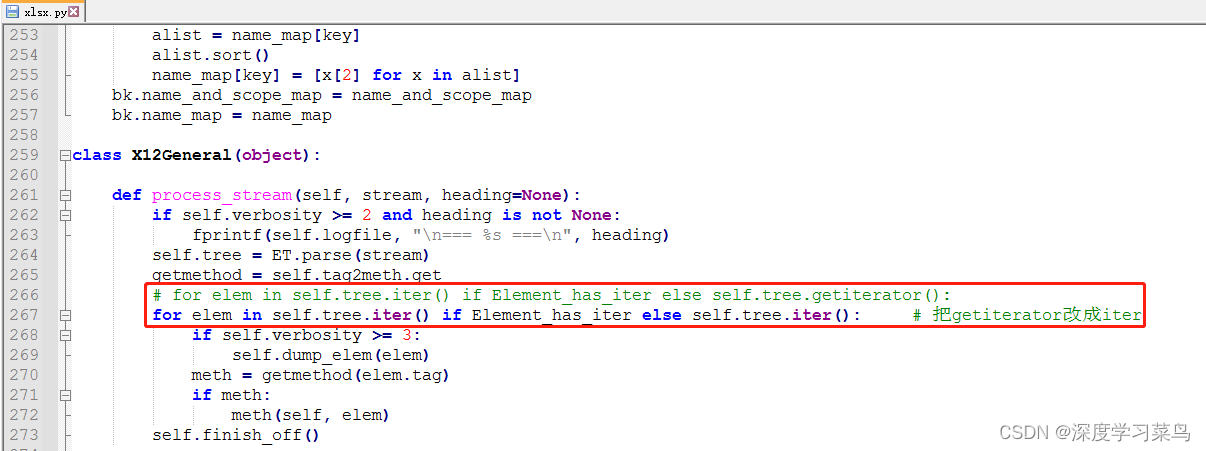
修改两个地方的的getiterator()改成iter(),下面的两个地方,这里已经把getiterator()改成iter()了
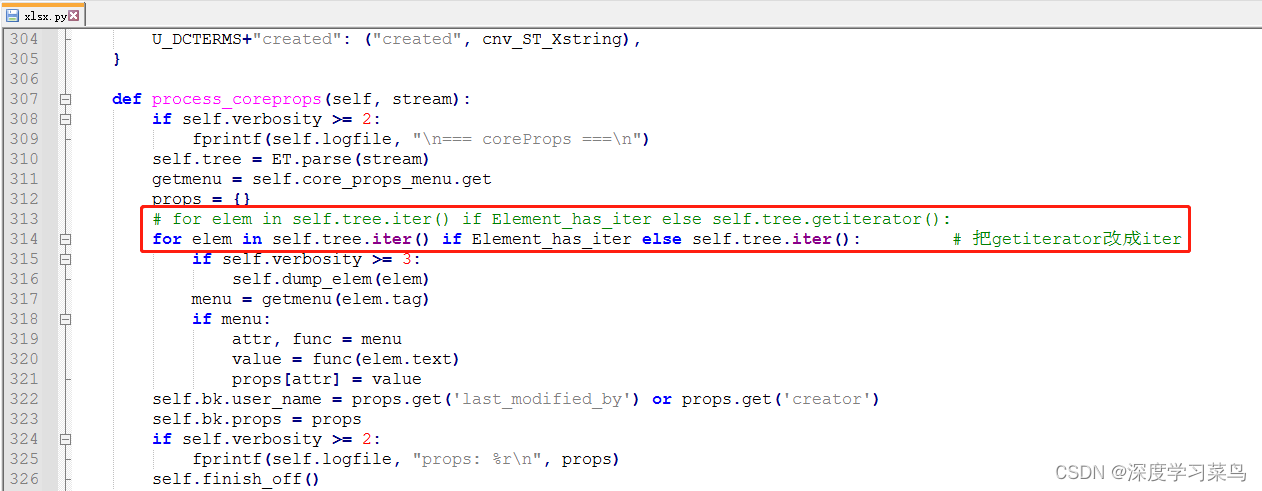
然后重新载入程序就解决了。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)