2.3Tucker分解HOSVD、HOOI算法推导和python实现
HOSVD参考论文:A MULTILINEAR SINGULAR VALUE DECOMPOSITIONHOSVD虽然不能保证给Tucker分解给出最优拟合,但是可以提供一个好的初始化的解这些矩阵都是正交的。之所以求前R最大特征值,可以在下文的HOOI看到,目的是最大化目标函数UWHOSVD的最后一行证明如下:HOOI:黄色之所以可以化过去,是因为原张量X其实是核张量G在高维空间的映射,而这个映射
·
HOSVD参考论文:A MULTILINEAR SINGULAR VALUE DECOMPOSITION
HOSVD虽然不能保证给Tucker分解给出最优拟合,但是可以提供一个好的初始化的解
这些矩阵都是正交的。之所以求前R最大特征值,可以在下文的HOOI看到,目的是最大化目标函数UW

HOSVD的最后一行证明如下:
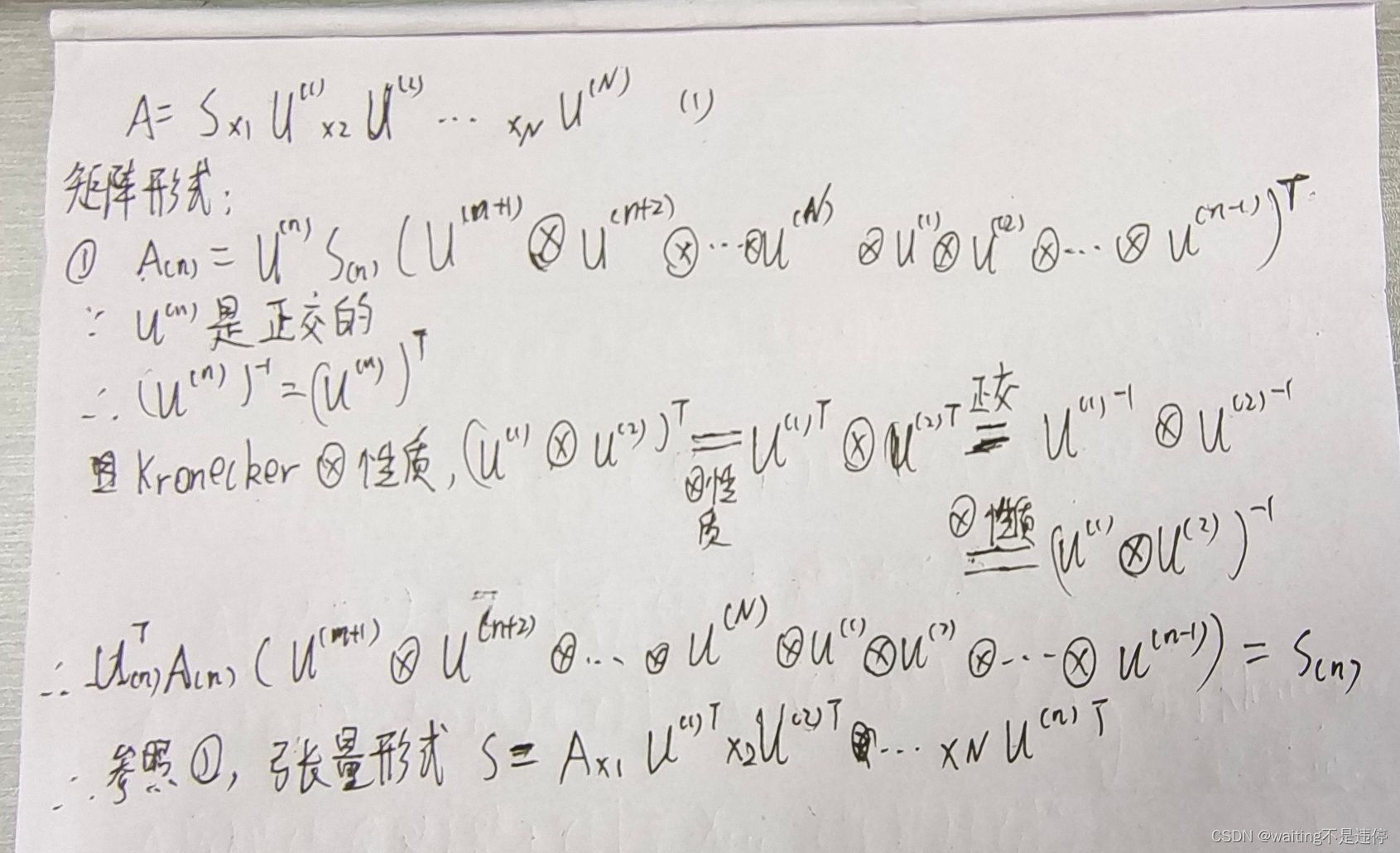
HOOI:

黄色之所以可以化过去,是因为原张量X其实是核张量G在高维空间的映射,而这个映射矩阵是单位正交矩阵,也就是说,只是旋转但不改变长度。因此F范数不变。
故此,优化目标可以化为:

因此HOOI算法如下:

注意,左特征值向量是横向量
skip是什么
python实现为:
import numpy as np
import tensorly as tl
from tensorly.decomposition import tucker
tl.set_backend('numpy')
def HOSVD(Tensor, rank):
U = []
for i in range(len(rank)):
tmpU,_,_ = np.linalg.svd(tl.unfold(Tensor,mode=i))
U.append(tmpU[0:rank[i]].T)
G = tl.tenalg.multi_mode_dot(Tensor,U,list(range(len(rank))),transpose=True)
return U,G
def HOOI(Tensor,rank,max_iter,max_err=1e5):
U,G = HOSVD(Tensor,rank)
for epoch in range(max_iter):
for i in range(len(rank)):
Y = tl.tenalg.multi_mode_dot(Tensor,U,skip=i, modes=list(range(len(rank))),transpose=True)
tmpU, _, _ = np.linalg.svd(tl.unfold(Y, mode=i))
U[i] = tmpU[0:rank[i]].T
# cal error
T_hat = tl.tenalg.multi_mode_dot(G,U,list(range(len(rank))))
error = tl.norm(Tensor - T_hat)
print("epoch:", epoch, ",error:", error)
if error<max_err:
break
G = tl.tenalg.multi_mode_dot(Tensor, U, list(range(len(rank))), transpose=True)
return U,G
# A = tl.tensor([[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0.],
# [ 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
# [ 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
# [ 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
# [ 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.],
# [ 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
# rank = [2,2]
rank = [2,3,2]
A = tl.tensor(np.array([[[1.0,14,15],[23,6,20],[24,18,8],[24,18,8]],
[[15,8,7],[28,12,17],[21,29,23],[24,18,8]],
[[9,5,3],[7,22,26],[21,1,19],[24,18,8]]]))
core, factors = tucker(A, rank=rank)
Ahat0 = tl.tenalg.multi_mode_dot(core,factors,list(range(len(rank))))
U,G = HOSVD(A,rank)
Ahat1 = tl.tenalg.multi_mode_dot(G,U,list(range(len(rank))))
U, G = HOOI(A,rank,500,1e5)
Ahat2 = tl.tenalg.multi_mode_dot(G,U,list(range(len(rank))))

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)