决策树和随机森林预测员工离职率学习代码
使用决策树和随机森林预测员工离职率我们的任务是帮助人事部门门理解员工为何离职,预测- -个员工离职的可能性.数据来源:#引入工具包import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport matplotlib as matplotimport seaborn as sns%matplotlib inline
·
使用决策树和随机森林预测员工离职率
- 我们的任务是帮助人事部门门理解员工为何离职,预测- -个员工离职的可能性.数据来源:
#引入工具包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as matplot
import seaborn as sns
%matplotlib inline
#读取数据
df = pd.read_csv("./data/HR_comma_sep.csv",index_col = None)
# 数据预处理
#检查数据是否又缺失值
df.isnull().any()
df.head()
#重命名
df.rename(columns=({'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'projectCount',
'average_montly_hours': 'averageMonthlyHours',
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'promotion_last_5years': 'promotion',
'sales' : 'department',
'left' : 'turnover'}),inplace=True)
# 将预测标签放第一列
font = df['turnover']
df.drop(labels=['turnover'],axis=1,inplace=True)
df.insert(0,'turnover',font)
df.head()
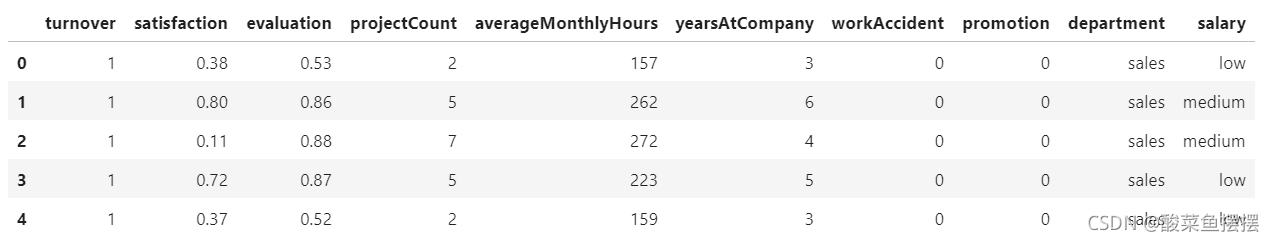
分析数据
- 14999 条数据,每一条数据包含10个特征
- 总的离职率24%
- 平均满意度0.61
turnover_rate = df.turnover.value_counts()/len(df)
turnover_rate
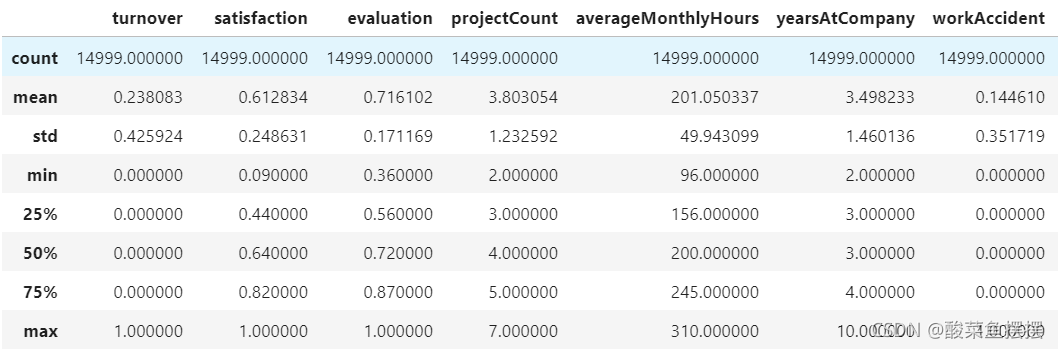
#显示统计数据
df.describe()
turnover_summary = df.groupby('turnover')
turnover_summary.mean()

相关性分析
正相关的特征:
- projectCount VS evaluation: 0.349333
- projectCount VS averageMonthlyHours: 0.417211
- averageMonthlyHours VS evaluation: 0.339742
负相关的特征:
- satisfaction VS turnover: -0.388375
思考:
- 什么特征的影响最大?
- 什么特征之间相关性最大?
# 相关性矩阵
corr = df.corr()
sns.heatmap(corr,xticklabels=corr.columns.values,yticklabels=corr.columns.values)
corr

# 比较离职和未离职员工的满意度
emp_population = df['satisfaction'][df['turnover']==0].mean()
emp_turnover_satisfaction = df[df['turnover']==1]['satisfaction'].mean()
print('未离职员工满意度',emp_population)
print('离职员工满意度',emp_turnover_satisfaction)

model
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, precision_score, recall_score, confusion_matrix, precision_recall_curve
#将string型转换为整数型
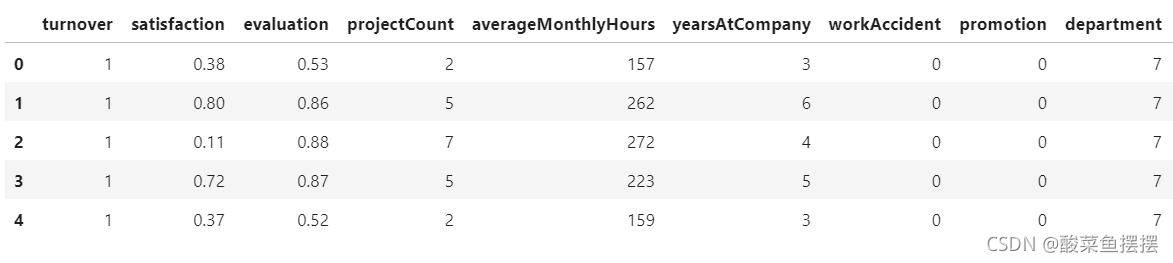
df['department'] = df['department'].astype('category').cat.codes
df['salary'] = df['department'].astype('category').cat.codes
#产生x,y
target_name = 'turnover'
# 产生x,y
y = df['turnover']
x = df.drop('turnover',axis=1)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.15,random_state=123,stratify=y)
df.head()
决策树
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
#决策树
dtree = tree.DecisionTreeClassifier(
criterion='entropy',
#max_depth=3, #定义树的深度,可以用来防止过拟合
min_weight_fraction_leaf=0.01 #定义叶子节点最少需要包含多少个样本(使用百分比表达),防止过拟合
)
dtree = dtree.fit(x_train,y_train)
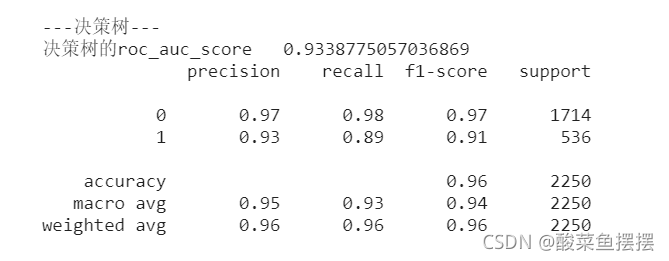
print('\n\n---决策树---')
dt_roc_auc = roc_auc_score(y_test,dtree.predict(x_test))
print('决策树的roc_auc_score ',dt_roc_auc)
print(classification_report(y_test,dtree.predict(x_test)))
随机森林
# 随机森林
rf = RandomForestClassifier(
criterion = 'entropy',
n_estimators=1000,
max_depth=None, #定义树的深度,可以用来防止过拟合
min_samples_split=10 # 定义至少多少个样本的情况下才继续分叉
# min_weight_fraction_leaf=0.01 #定义叶子节点最少需要包含多少个样本(使用百分比表达),防止过拟合
)
rf.fit(x_train,y_train)
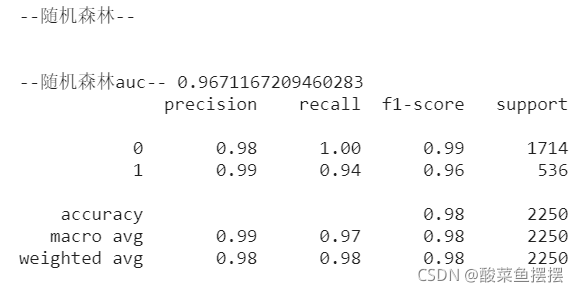
print('\n\n--随机森林--')
rt_roc_auc = roc_auc_score(y_test,rf.predict(x_test))
print('\n\n--随机森林auc--',rt_roc_auc)
print(classification_report(y_test,rf.predict(x_test)))
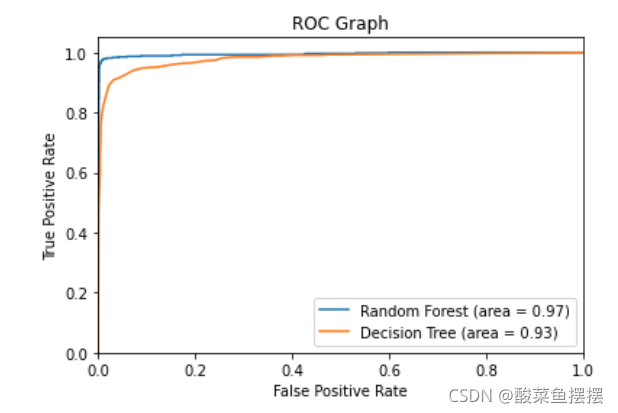
roc图
from sklearn.metrics import roc_curve
rf_fpr, rf_tpr, rf_thresholds = roc_curve(y_test, rf.predict_proba(x_test)[:,1])
dt_fpr, dt_tpr, dt_thresholds = roc_curve(y_test, dtree.predict_proba(x_test)[:,1])
plt.figure()
# 随机森林 ROC
plt.plot(rf_fpr, rf_tpr, label='Random Forest (area = %0.2f)' % rt_roc_auc)
# 决策树 ROC
plt.plot(dt_fpr, dt_tpr, label='Decision Tree (area = %0.2f)' % dt_roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Graph')
plt.legend(loc="lower right")
plt.show()
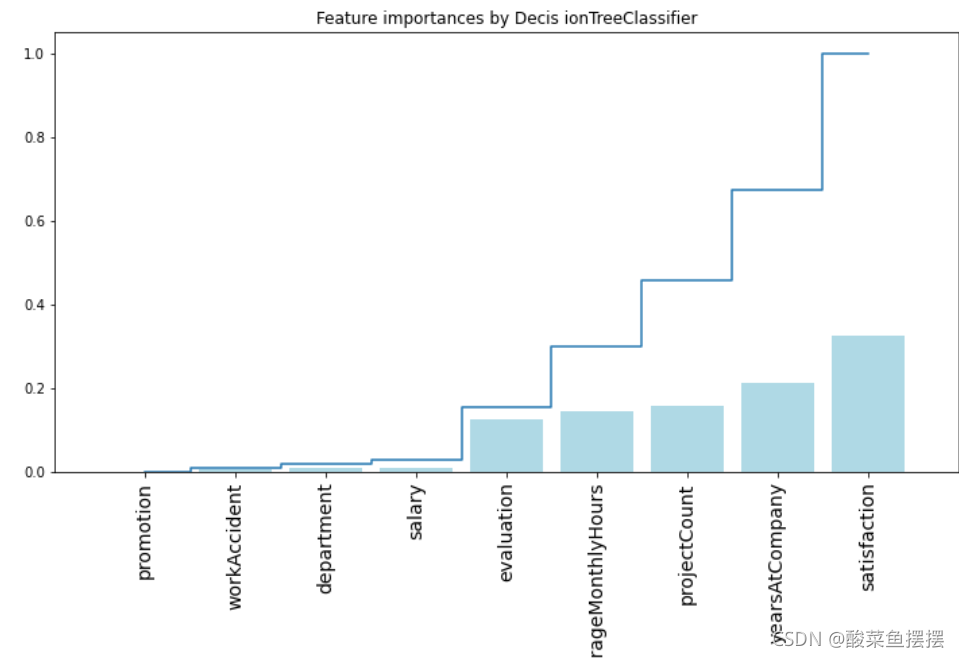
通过决策树分析不同的特征的重要性
## 画出决策树特征的重要性 ##
importances = rf.feature_importances_
feat_names = df.drop(['turnover'],axis=1).columns
indices = np.argsort(importances)[::1]
plt.figure(figsize=(12,6))
plt.title("Feature importances by Decis ionTreeClassifier")
plt.bar(range(len(indices)),importances[indices],color='lightblue',align='center')
plt.step(range(len(indices)),np.cumsum(importances[indices]),where='mid',label='Cumulative')
plt.xticks(range(len(indices)),feat_names[indices],rotation='vertical',fontsize=14)
plt.xlim([-1,len(indices)])
plt.show()
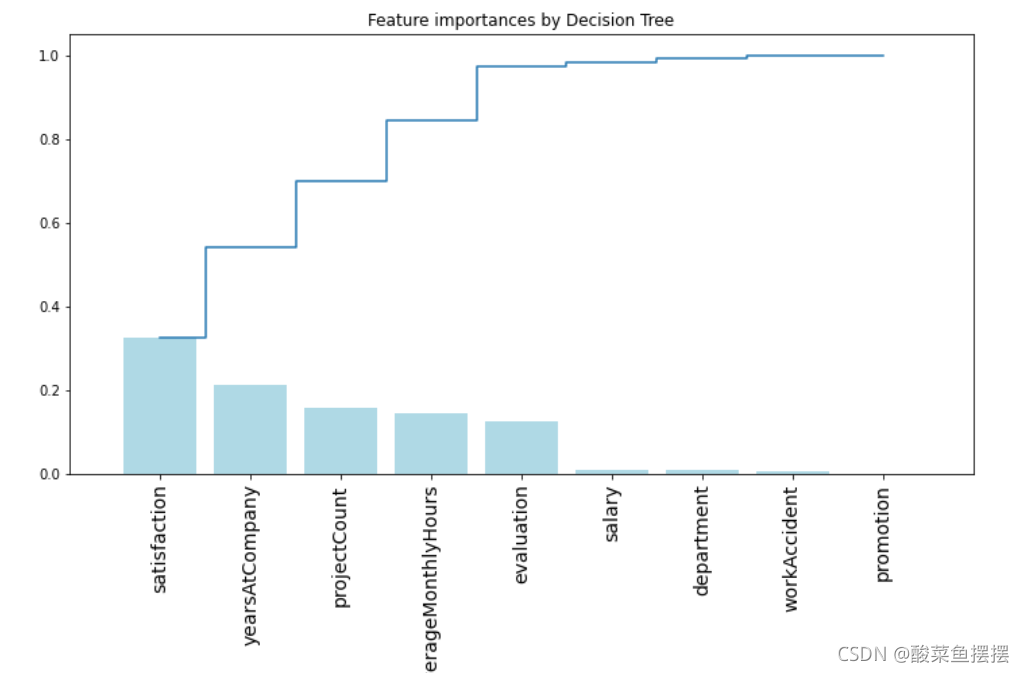
## 画出决策树的特征的重要性 ##
importances = rf.feature_importances_
feat_names = df.drop(['turnover'],axis=1).columns
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(12,6))
plt.title("Feature importances by Decision Tree")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)
plt.xlim([-1, len(indices)])
plt.show()

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)