2. Python实现VRP常见求解算法——遗传算法(GA)
参考笔记https://github.com/PariseC/Algorithms_for_solving_VRP1. 适用场景求解CVRP车辆类型单一车辆容量不小于需求节点最大需求单一车辆基地2. 问题分析CVRP问题的解为一组满足需求节点需求的多个车辆的路径集合。假设某物理网络中共有10个顾客节点,编号为1~10,一个车辆基地,编号为0,在满足车辆容量约束与顾客节点需求约束的条件下,此问题的一
参考笔记
https://github.com/PariseC/Algorithms_for_solving_VRP
1. 适用场景
- 求解CVRP
- 车辆类型单一
- 车辆容量不小于需求节点最大需求
- 单一车辆基地
2. 问题分析
CVRP问题的解为一组满足需求节点需求的多个车辆的路径集合。假设某物理网络中共有10个顾客节点,编号为1~10,一个车辆基地,编号为0,在满足车辆容量约束与顾客节点需求约束的条件下,此问题的一个可行解可表示为:[0-1-2-0,0-3-4-5-0,0-6-7-8-0,0-9-10-0],即需要4个车辆来提供服务,车辆的行驶路线分别为0-1-2-0,0-3-4-5-0,0-6-7-8-0,0-9-10-0。由于车辆的容量固定,基地固定,因此可以将上述问题的解先表示为[1-2-3-4-5-6-7-8-9-10]的有序序列,然后根据车辆的容量约束,对序列进行切割得到若干车辆的行驶路线。因此可以将CVRP问题转换为TSP问题进行求解,得到TSP问题的优化解后再考虑车辆容量约束进行路径切割,得到CVRP问题的解。这样的处理方式可能会影响CVRP问题解的质量,但简化了问题的求解难度。
3. 数据格式
以xlsx文件储存网络数据,其中第一行为标题栏,第二行存放车辆基地数据。在程序中车辆基地seq_no编号为-1,需求节点seq_id从0开始编号。可参考github主页相关文件。
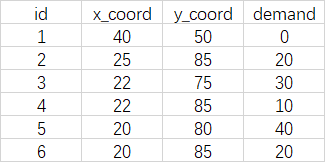
4. 分步实现
(1)数据结构
定义Sol()类,Node()类,Model()类,其属性如下表:
- Sol()类,表示一个可行解
| 属性 | 描述 |
|---|---|
| nodes_seq | 需求节点seq_no有序排列集合,对应TSP的解 |
| obj | 优化目标值 |
| fit | 解的适应度 |
| routes | 车辆路径集合,对应CVRP的解 |
- Node()类,表示一个网络节点
| 属性 | 描述 |
|---|---|
| id | 物理节点id,可选 |
| name | 物理节点名称,可选 |
| seq_no | 物理节点映射id,基地节点为-1,需求节点从0编号 |
| x_coord | 物理节点x坐标 |
| y_coord | 物理节点y坐标 |
| demand | 物理节点需求 |
- Model()类,存储算法参数
| 属性 | 描述 |
|---|---|
| best_sol | 全局最优解,值类型为Sol() |
| node_list | 物理节点集合,值类型为Node() |
| sol_list | 种群,值类型为Sol() |
| node_seq_no_list | 物理节点映射id集合 |
| depot | 车辆基地,值类型为Node() |
| number_of_nodes | 需求节点数量 |
| opt_type | 优化目标类型,0:最小车辆数,1:最小行驶距离 |
| vehicle_cap | 车辆容量 |
| pc | 交叉概率 |
| pm | 突变概率 |
| n_select | 优良个体选择数量 |
| popsize | 种群规模 |
(2)文件读取
def readXlsxFile(filepath,model):
#It is recommended that the vehicle depot data be placed in the first line of xlsx file
node_seq_no =-1 #the depot node seq_no is -1,and demand node seq_no is 0,1,2,...
df = pd.read_excel(filepath)
for i in range(df.shape[0]):
node=Node()
node.id=node_seq_no
node.seq_no=node_seq_no
node.x_coord= df['x_coord'][i]
node.y_coord= df['y_coord'][i]
node.demand=df['demand'][i]
if df['demand'][i] == 0:
model.depot=node
else:
model.node_list.append(node)
model.node_seq_no_list.append(node_seq_no)
try:
node.name=df['name'][i]
except:
pass
try:
node.id=df['id'][i]
except:
pass
node_seq_no=node_seq_no+1
model.number_of_nodes=len(model.node_list)
(3)初始解生成
def genInitialSol(model):
nodes_seq=copy.deepcopy(model.node_seq_no_list)
for i in range(model.popsize):
seed=int(random.randint(0,10))
random.seed(seed)
random.shuffle(nodes_seq)
sol=Sol()
sol.nodes_seq=copy.deepcopy(nodes_seq)
model.sol_list.append(sol)
(4)适应度计算
适应度计算依赖" splitRoutes “函数对TSP可行解分割得到车辆行驶路线和所需车辆数,” calDistance "函数计算行驶距离。
def splitRoutes(nodes_seq,model):
num_vehicle = 0
vehicle_routes = []
route = []
remained_cap = model.vehicle_cap
for node_no in nodes_seq:
if remained_cap - model.node_list[node_no].demand >= 0:
route.append(node_no)
remained_cap = remained_cap - model.node_list[node_no].demand
else:
vehicle_routes.append(route)
route = [node_no]
num_vehicle = num_vehicle + 1
remained_cap =model.vehicle_cap - model.node_list[node_no].demand
vehicle_routes.append(route)
return num_vehicle,vehicle_routes
def calDistance(route,model):
distance=0
depot=model.depot
for i in range(len(route)-1):
from_node=model.node_list[route[i]]
to_node=model.node_list[route[i+1]]
distance+=math.sqrt((from_node.x_coord-to_node.x_coord)**2+(from_node.y_coord-to_node.y_coord)**2)
first_node=model.node_list[route[0]]
last_node=model.node_list[route[-1]]
distance+=math.sqrt((depot.x_coord-first_node.x_coord)**2+(depot.y_coord-first_node.y_coord)**2)
distance+=math.sqrt((depot.x_coord-last_node.x_coord)**2+(depot.y_coord - last_node.y_coord)**2)
return distance
def calFit(model):
#calculate fit value:fit=Objmax-obj
Objmax=-float('inf')
best_sol=Sol()#record the local best solution
best_sol.obj=float('inf')
#计算目标函数
for sol in model.sol_list:
nodes_seq=sol.nodes_seq
num_vehicle, vehicle_routes = splitRoutes(nodes_seq, model)
if model.opt_type==0:
sol.obj=num_vehicle
sol.routes=vehicle_routes
if sol.obj>Objmax:
Objmax=sol.obj
if sol.obj<best_sol.obj:
best_sol=copy.deepcopy(sol)
else:
distance=0
for route in vehicle_routes:
distance+=calDistance(route,model)
sol.obj=distance
sol.routes=vehicle_routes
if sol.obj>Objmax:
Objmax=sol.obj
if sol.obj < best_sol.obj:
best_sol = copy.deepcopy(sol)
#calculate fit value
for sol in model.sol_list:
sol.fit=Objmax-sol.obj
#update the global best solution
if best_sol.obj<model.best_sol.obj:
model.best_sol=best_sol
(5)优良个体选择
采用二元锦标赛法进行优良个体选择。
遗传算法中的锦标赛选择策略每次从种群中取出一定数量个体(放回抽样),然后选择其中最好的一个进入子代种群。重复该操作,直到新的种群规模达到原来的种群规模。几元锦标赛就是一次性在总体中取出几个个体,然后在这些个体中取出最优的个体放入保留到下一代种群的集合中。具体的操作步骤如下:
1、确定每次选择的个体数量N。(二元锦标赛选择即选择2个个体)
2、从种群中随机选择N个个体(每个个体被选择的概率相同) ,根据每个个体的适应度值,选择
其中适应度值最好的个体进入下一代种群。
3、 重复步骤(2)多次(重复次数为种群的大小),直到新的种群规模达到原来的种群规模。
def selectSol(model):
sol_list=copy.deepcopy(model.sol_list)
model.sol_list=[]
for i in range(model.n_select):
f1_index=random.randint(0,len(sol_list)-1)
f2_index=random.randint(0,len(sol_list)-1)
f1_fit=sol_list[f1_index].fit
f2_fit=sol_list[f2_index].fit
if f1_fit<f2_fit:
model.sol_list.append(sol_list[f2_index])
else:
model.sol_list.append(sol_list[f1_index])
(6)交叉
采用OX交叉法。
Order Crossover (OX)
过程:
遗传算法中几种交叉算子小结
两个父代:Par1 和Par2
- 随机选择一对染色体(父代)中几个基因的起止位置(两染色体被选位置相同)
- 生成一个子代,并保证子代中被选中的基因的位置与父代相同
- 先找出第一步选中的基因在另一个父代中的位置,再将其余基因按顺序放入上一步生成的子代中:
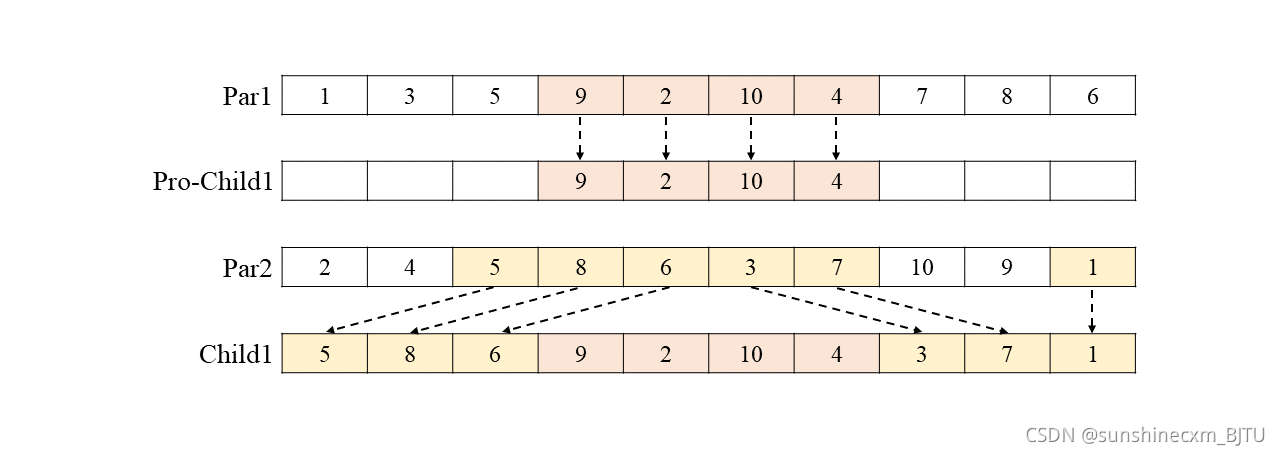
需要注意的是,这种算法同样会生成两个子代,另一个子代生成过程完全相同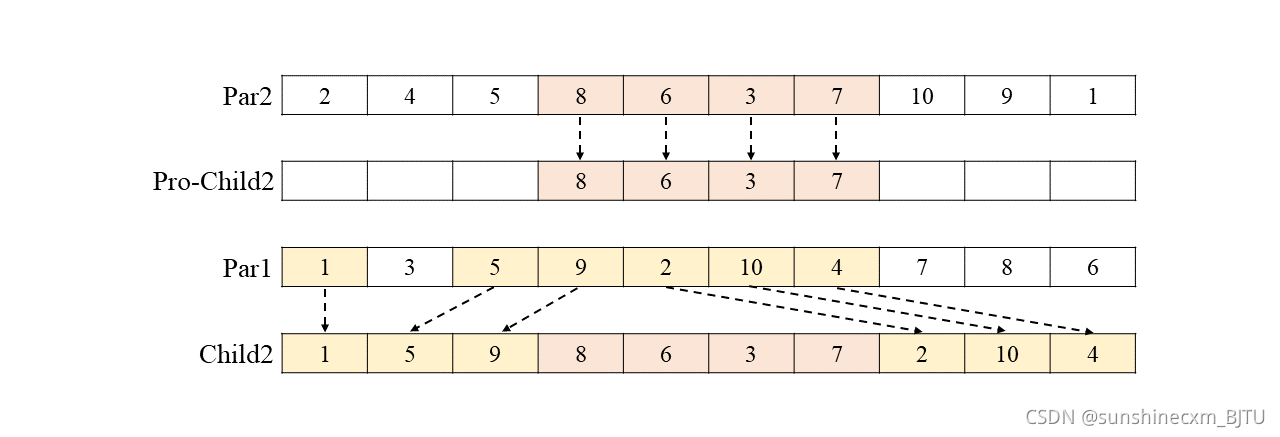
产生两个子代:Child1和Child2
# Order Crossover (OX)
def crossSol(model):
sol_list=copy.deepcopy(model.sol_list)
model.sol_list=[]
while True:
f1_index = random.randint(0, len(sol_list) - 1)
f2_index = random.randint(0, len(sol_list) - 1)
if f1_index!=f2_index:
f1 = copy.deepcopy(sol_list[f1_index])
f2 = copy.deepcopy(sol_list[f2_index])
if random.random() <= model.pc:
cro1_index=int(random.randint(0,model.number_of_nodes-1))
cro2_index=int(random.randint(cro1_index,model.number_of_nodes-1))
new_c1_f = []
new_c1_m=f1.nodes_seq[cro1_index:cro2_index+1]
new_c1_b = []
new_c2_f = []
new_c2_m=f2.nodes_seq[cro1_index:cro2_index+1]
new_c2_b = []
for index in range(model.number_of_nodes):
if len(new_c1_f)<cro1_index:
if f2.nodes_seq[index] not in new_c1_m:
new_c1_f.append(f2.nodes_seq[index])
else:
if f2.nodes_seq[index] not in new_c1_m:
new_c1_b.append(f2.nodes_seq[index])
for index in range(model.number_of_nodes):
if len(new_c2_f)<cro1_index:
if f1.nodes_seq[index] not in new_c2_m:
new_c2_f.append(f1.nodes_seq[index])
else:
if f1.nodes_seq[index] not in new_c2_m:
new_c2_b.append(f1.nodes_seq[index])
new_c1=copy.deepcopy(new_c1_f)
new_c1.extend(new_c1_m)
new_c1.extend(new_c1_b)
f1.nodes_seq=new_c1
new_c2=copy.deepcopy(new_c2_f)
new_c2.extend(new_c2_m)
new_c2.extend(new_c2_b)
f2.nodes_seq=new_c2
model.sol_list.append(copy.deepcopy(f1))
model.sol_list.append(copy.deepcopy(f2))
else:
model.sol_list.append(copy.deepcopy(f1))
model.sol_list.append(copy.deepcopy(f2))
if len(model.sol_list)>model.popsize:
break
(7)突变
采用二元突变。
def muSol(model):
sol_list=copy.deepcopy(model.sol_list)
model.sol_list=[]
while True:
f1_index = int(random.randint(0, len(sol_list) - 1))
f1 = copy.deepcopy(sol_list[f1_index])
m1_index=random.randint(0,model.number_of_nodes-1)
m2_index=random.randint(0,model.number_of_nodes-1)
if m1_index!=m2_index:
if random.random() <= model.pm:
node1=f1.nodes_seq[m1_index]
f1.nodes_seq[m1_index]=f1.nodes_seq[m2_index]
f1.nodes_seq[m2_index]=node1
model.sol_list.append(copy.deepcopy(f1))
else:
model.sol_list.append(copy.deepcopy(f1))
if len(model.sol_list)>model.popsize:
break
(8)绘制收敛曲线
def plotObj(obj_list):
plt.rcParams['font.sans-serif'] = ['SimHei'] #show chinese
plt.rcParams['axes.unicode_minus'] = False # Show minus sign
plt.plot(np.arange(1,len(obj_list)+1),obj_list)
plt.xlabel('Iterations')
plt.ylabel('Obj Value')
plt.grid()
plt.xlim(1,len(obj_list)+1)
plt.show()
(9)输出结果
def outPut(model):
work=xlsxwriter.Workbook('result.xlsx')
worksheet=work.add_worksheet()
worksheet.write(0,0,'opt_type')
worksheet.write(1,0,'obj')
if model.opt_type==0:
worksheet.write(0,1,'number of vehicles')
else:
worksheet.write(0, 1, 'drive distance of vehicles')
worksheet.write(1,1,model.best_sol.obj)
for row,route in enumerate(model.best_sol.routes):
worksheet.write(row+2,0,'v'+str(row+1))
r=[str(i)for i in route]
worksheet.write(row+2,1, '-'.join(r))
work.close()

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)