【2.5万字】详解 Python-docx 自动生成word图文报告
一、环境搭建1.1 python-docx(读写Word文档的大部分操作)1.1.1 官方文档https://python-docx.readthedocs.io/en/latest/1.1.2 清华源安装python-docx我已经装过了。pip install -i https://pypi.tuna.tsinghua.edu.cn/simplepython-docx1.1.3 导包方式fro
目录
- 推荐:[python自动化办公——python操作Excel、Word、PDF集合大全](https://blog.csdn.net/weixin_41261833/article/details/106028038)
- 一、环境搭建
- 二、小试牛刀 - 工具介绍与简单使用
- 三、案例
推荐:python自动化办公——python操作Excel、Word、PDF集合大全
这是非常好的一篇博文,出于对原作者的尊重,强烈推荐点过去看!
网址:https://blog.csdn.net/weixin_41261833/article/details/106028038
一、环境搭建
1.1 python-docx(读写Word文档的大部分操作)
1.1.1 官方文档
https://python-docx.readthedocs.io/en/latest/
1.1.2 清华源安装python-docx
我已经装过了。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-docx

1.1.3 导包方式
from docx import Document
from docx.shared import Inches
1.2 win32com(主要用作doc转docx格式转换用)
1.2.1 官方文档
https://docs.microsoft.com/en-us/dotnet/api/microsoft.office.interop.word?view=word-pia
1.2.2 清华源安装win32com
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pypiwin32

1.2.3 导包方式
import win32com
from win32com.client import Dispatch, constants
1.3 docx-mailmerge(用作按照模板生成大量同类型文档)
1.3.1 官方文档
https://pypi.org/project/docx-mailmerge/
1.3.2 清华源安装docx-mailmerge
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple docx-mailmerge

1.3.3 导包方式
from mailmerge import MailMerge
1.4 matplotlib(Python 最基本的绘图库)
1.4.1 官方文档 V3.4.2
https://matplotlib.org/stable/tutorials/introductory/sample_plots.html
1.4.2 清华源安装matplotlib
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib
1.4.3 导包方式
import matplotlib.pyplot as plt
二、小试牛刀 - 工具介绍与简单使用
2.1 Python-docx
python-docx 是用于创建可修改 微软 Word 的一个 python 库,提供全套的 Word 操作,是最常用的 Word 工具
2.1.1 基本概念
- Document:是一个 Word 文档 对象,不同于 VBA 中 Worksheet 的概念,Document 是独立的,打开不同的 Word 文档,就会有不同的 Document 对象,相互之间没有影响。
- Paragraph:是段落,一个 Word 文档由多个段落组成,当在文档中输入一个回车键,就会成为新的段落,输入 shift + 回车,不会分段。
- Run 表示一个节段,每个段落由多个节段 组成,一个段落中具有相同样式的连续文本,组成一个节段,所以一个 段落对象有多个 Run 列表。
如图所示:

2.1.2 创建一个word文件
# 导包
from docx import Document
# 实例化一个Document对象,相当于打开word软件,新建一个空白文件
doc = Document()
# word文件尾部增加一个段落,并写入内容
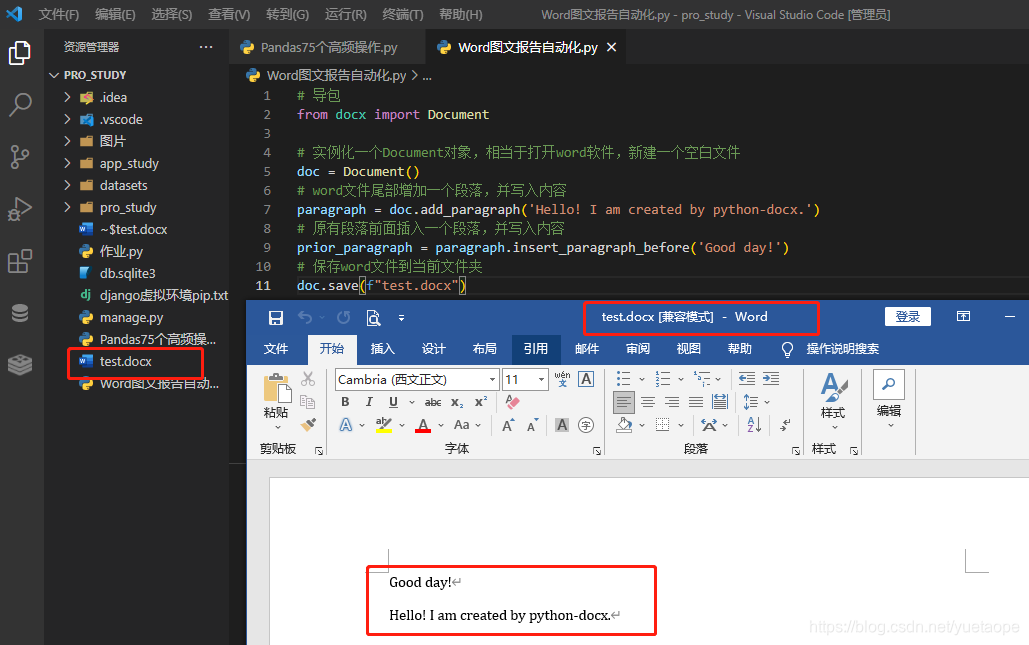
paragraph = doc.add_paragraph('Hello! I am created by python-docx.')
# 原有段落前面插入一个段落,并写入内容
prior_paragraph = paragraph.insert_paragraph_before('Good day!')
# 保存word文件到当前文件夹
doc.save(f"test.docx")
2.1.3 顺序增加段落、文字块、图片
# 导入模块
from docx import Document
# 新建文档对象按模板新建 word 文档文件,具有模板文件的所有格式
doc = Document()
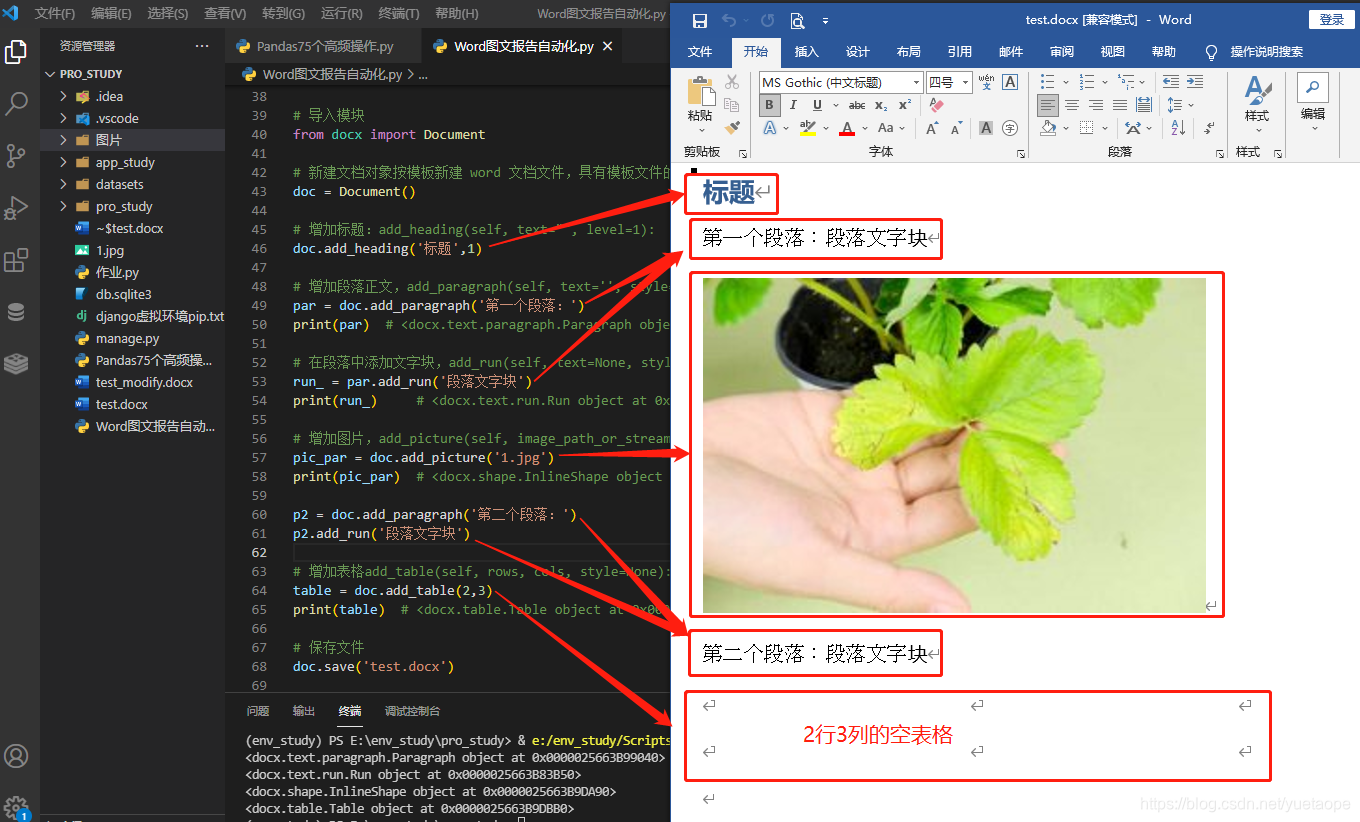
# 增加标题:add_heading(self, text="", level=1):
doc.add_heading('标题',1)
# 增加段落正文,add_paragraph(self, text='', style=None):返回一个 Paragraph 段落对象
par = doc.add_paragraph('第一个段落:')
print(par) # <docx.text.paragraph.Paragraph object at 0x000000000A889F08>
# 在段落中添加文字块,add_run(self, text=None, style=None):返回一个 run 对象
run_ = par.add_run('段落文字块')
print(run_) # <docx.text.run.Run object at 0x000000000B2D31C8>
# 增加图片,add_picture(self, image_path_or_stream, width=None, height=None):返回一个 InlineShape 对象
pic_par = doc.add_picture('1.jpg')
print(pic_par) # <docx.shape.InlineShape object at 0x000000000B2F11C8>
p2 = doc.add_paragraph('第二个段落:')
p2.add_run('段落文字块')
# 增加表格add_table(self, rows, cols, style=None):返回一个表格对象
table = doc.add_table(2,3)
print(table) # <docx.table.Table object at 0x000000000B302688>
# 保存文件
doc.save('test.docx')
2.1.4 内容修改:正则替换原有word文件中的英文引号
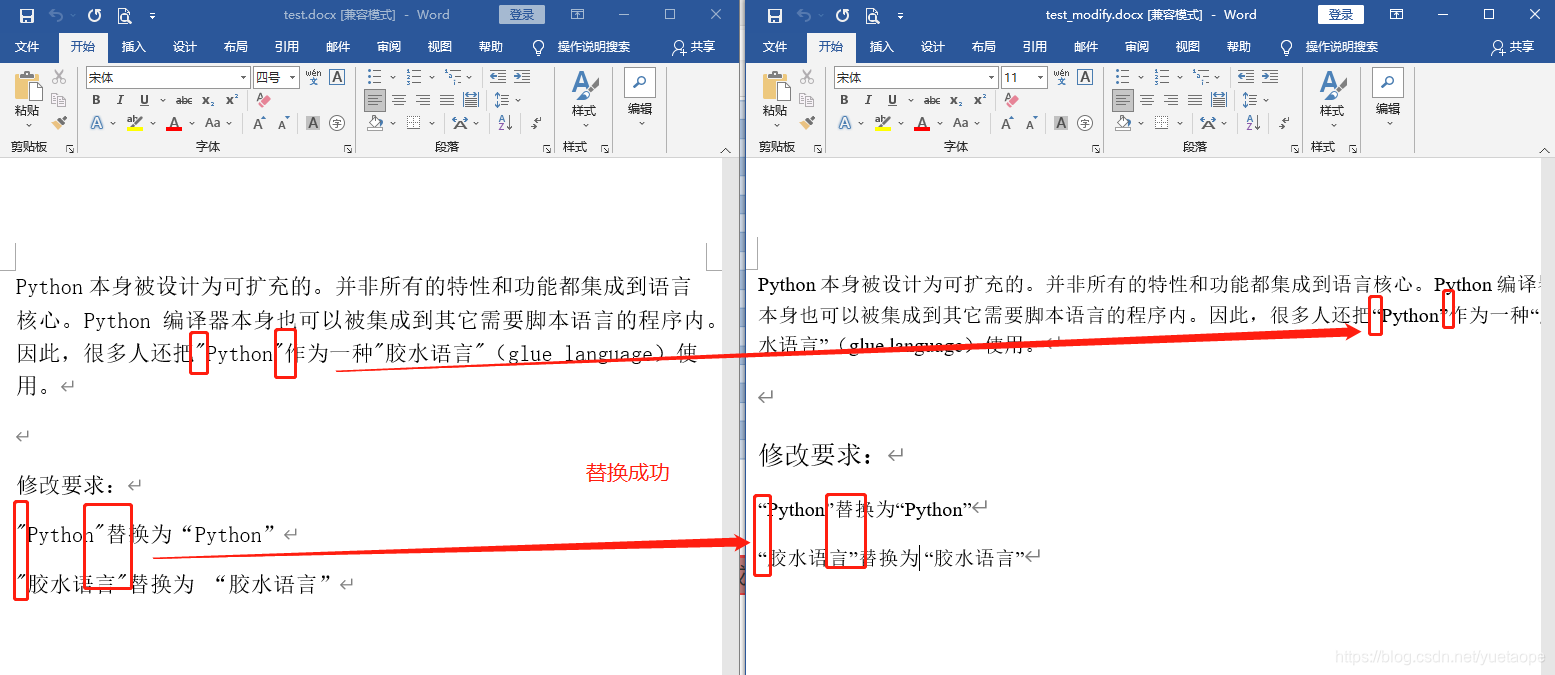
Python本身被设计为可扩充的。并非所有的特性和功能都集成到语言核心。Python编译器本身也可以被集成到其它需要脚本语言的程序内。因此,很多人还把"Python"作为一种"胶水语言"(glue language)使用。
修改要求:
"Python"替换为“Python”
"胶水语言"替换为 “胶水语言”
对于英文引号来说不区分前引号和后引号,怎么能保证配置到的不会是 “作为一种”?
经测试正则为:’"(?:[^"])*"’
?::为了取消圆括号模式配置过程的缓存,即不需要遇到一个符合的就结束匹配
[^"]:表示匹配的内容不能是 ",以避免贪婪匹配,即避免匹配成 从第一个 " 开始一直到最后一个 "结束
整体的意思是 配置两个 " 之间的内容,且内容中不包括 "
from docx import Document
from docx.oxml.ns import qn # 设置中文字体需导入 qn 模块
import re
doc = Document(r"test.docx")
# 定义正则
restr = '"(?:[^"])*"'
for p in doc.paragraphs:
# 修改引号
list_results = re.findall(restr, p.text)
for result in list_results:
# 段落文字替换掉英文引号,再赋值给段落文字
p.text = p.text.replace(result, '“' + result[1:-1] + '”')
# 修改格式必须放在后边,否则会被其他操作覆盖
# 设置全部字体为宋体
for run in p.runs:
run.font.name = 'Times New Roman' # 注:这个好像设置 run 中的西文字体
run.font.element.rPr.rFonts.set(qn('w:eastAsia'),'宋体')
doc.save(r'test_modify.docx')
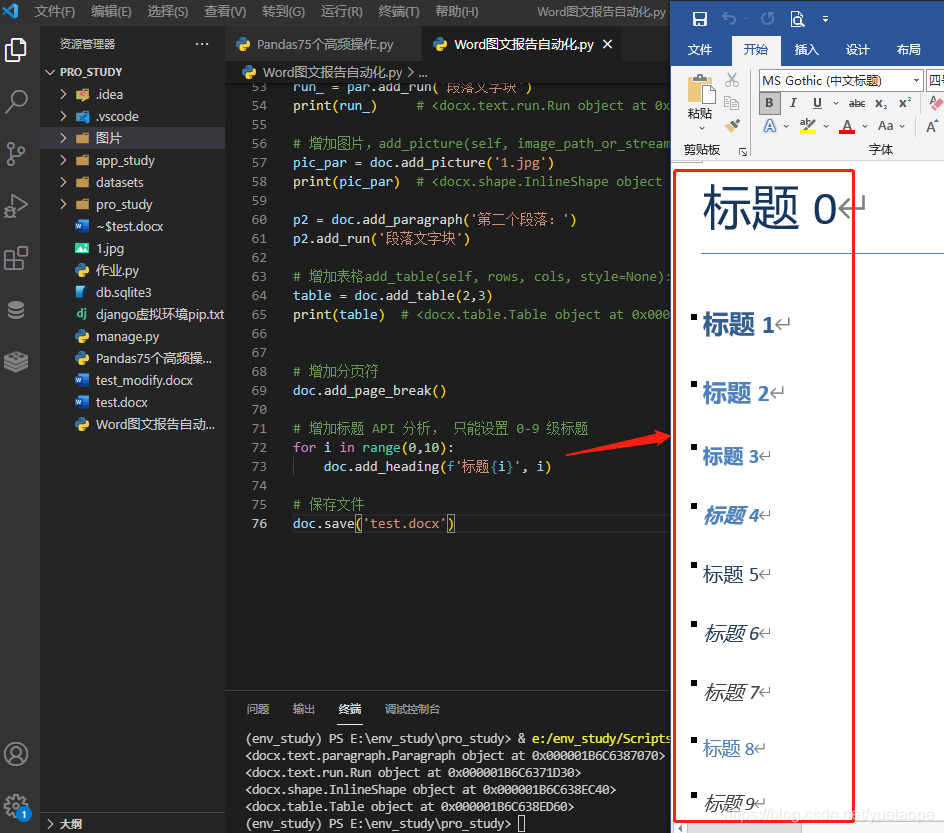
2.1.5 段落格式设置
# 增加分页符
doc.add_page_break()
# 增加标题 API 分析, 只能设置 0-9 级标题
for i in range(0,10):
doc.add_heading(f'标题{i}', i)
# 增加分页
doc.add_page_break()
# 新增一个段落,代码换行,word中就是一个段落,不换行
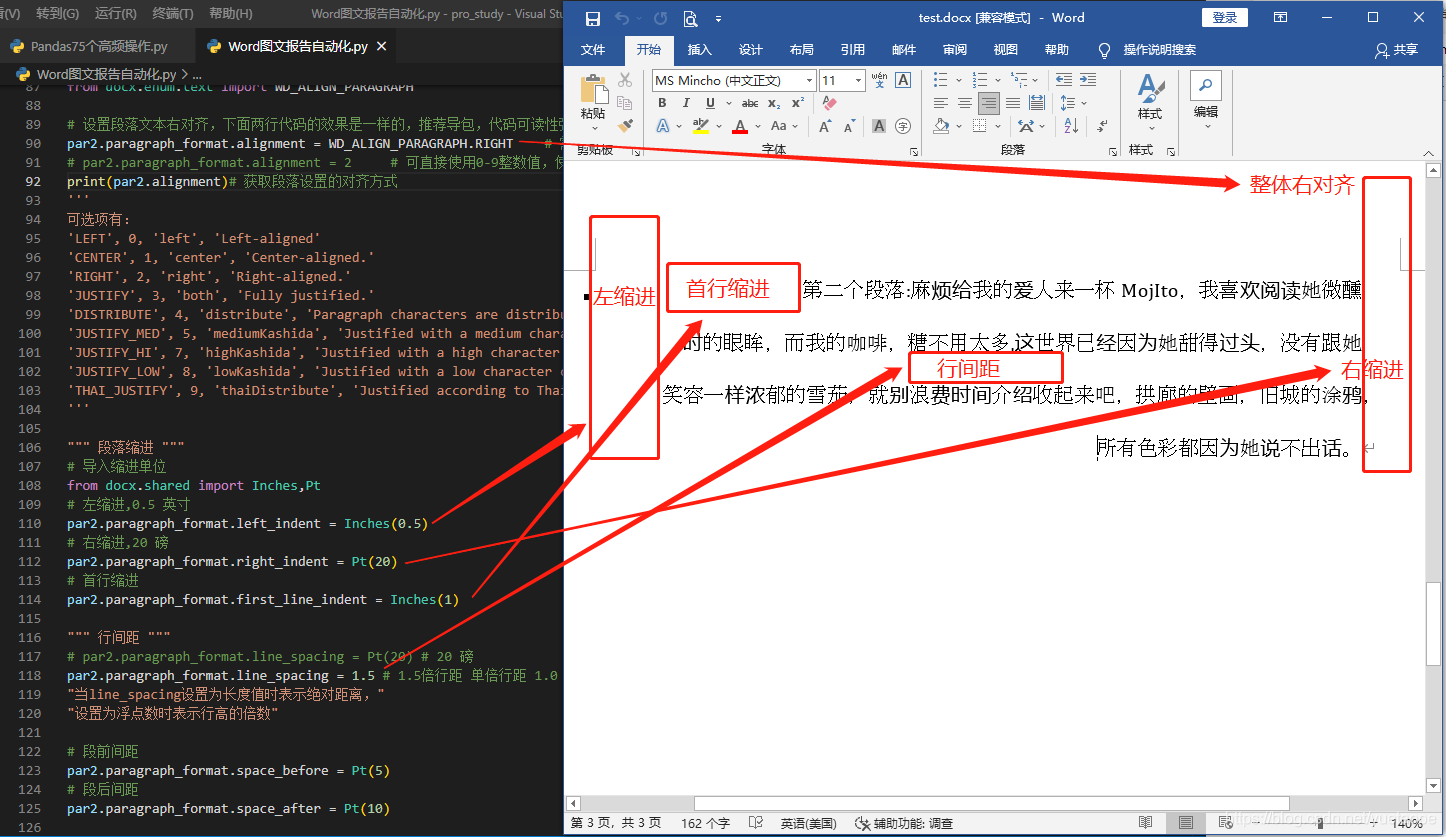
par2 = doc.add_paragraph('第二个段落:麻烦给我的爱人来一杯MojIto,'
'我喜欢阅读她微醺时的眼眸,而我的咖啡,糖不用太多,'
'这世界已经因为她甜得过头,没有跟她笑容一样浓郁的雪茄,'
'就别浪费时间介绍收起来吧,拱廊的壁画,旧城的涂鸦,'
'所有色彩都因为她说不出话。')
""" Paragraph 段落格式设置 """
# 段落对齐设置:# 导入对齐选项
from docx.enum.text import WD_ALIGN_PARAGRAPH
# 设置段落文本右对齐,下面两行代码的效果是一样的,推荐导包,代码可读性强
par2.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.RIGHT # 需要导包,代码直观
# par2.paragraph_format.alignment = 2 # 可直接使用0-9整数值,使用简单
# 获取段落设置的对齐方式
print(par2.alignment)
'''
可选项有:
'LEFT', 0, 'left', 'Left-aligned'
'CENTER', 1, 'center', 'Center-aligned.'
'RIGHT', 2, 'right', 'Right-aligned.'
'JUSTIFY', 3, 'both', 'Fully justified.'
'DISTRIBUTE', 4, 'distribute', 'Paragraph characters are distrib'
'uted to fill the entire width of the paragraph.'
'JUSTIFY_MED', 5, 'mediumKashida', 'Justified with a medium char'
'acter compression ratio.'
'JUSTIFY_HI', 7, 'highKashida', 'Justified with a high character'
' compression ratio.'
'JUSTIFY_LOW', 8, 'lowKashida', 'Justified with a low character '
'compression ratio.'
'THAI_JUSTIFY', 9, 'thaiDistribute', 'Justified according to Tha'
'i formatting layout.'
'''
""" 段落缩进 """
# 导入缩进单位
from docx.shared import Inches,Pt
# 左缩进,0.5 英寸
par2.paragraph_format.left_indent = Inches(0.5)
# 右缩进,20 磅
par2.paragraph_format.right_indent = Pt(20)
# 首行缩进
par2.paragraph_format.first_line_indent = Inches(1)
""" 行间距 """
# par2.paragraph_format.line_spacing = Pt(20) # 20 磅
par2.paragraph_format.line_spacing = 1.5 # 1.5倍行距 单倍行距 1.0
"当line_spacing设置为长度值时表示绝对距离,"
"设置为浮点数时表示行高的倍数"
# 段前间距
par2.paragraph_format.space_before = Pt(5)
# 段后间距
par2.paragraph_format.space_after = Pt(10)
""" 设置段落内部文字在遇到需分页情况时处理状态 """
par2.paragraph_format.keep_together = True # 段中不分页
par2.paragraph_format.keep_with_next = True # 与下段同页
par2.paragraph_format.page_break_before = True # 段前分页
par2.paragraph_format.widow_control = True # 孤行控制
# 获取段落的左缩进,首行缩进,段前间距:
l_space = par2.paragraph_format.left_indent
h_space = par2.paragraph_format.first_line_indent
b_space = par2.paragraph_format.space_before
print(l_space,h_space,b_space) # 457200 914400 63500
2.1.6 字体格式设置
首先明确一个概念:
python-docx 模块中,paragraph 段落是一个块对象,可以理解为是一个容器。run 对象也是一个块对象,可以理解为具有相同格式的一段文字集合。
放在 word 文档中简单理解就是,一个段落包含许多文字,同一段落的文字,也可以有不同的格式。
注意:用 add_paragraph() 方法添加段落时,如果写入了文本,就直接创建了一个 run。
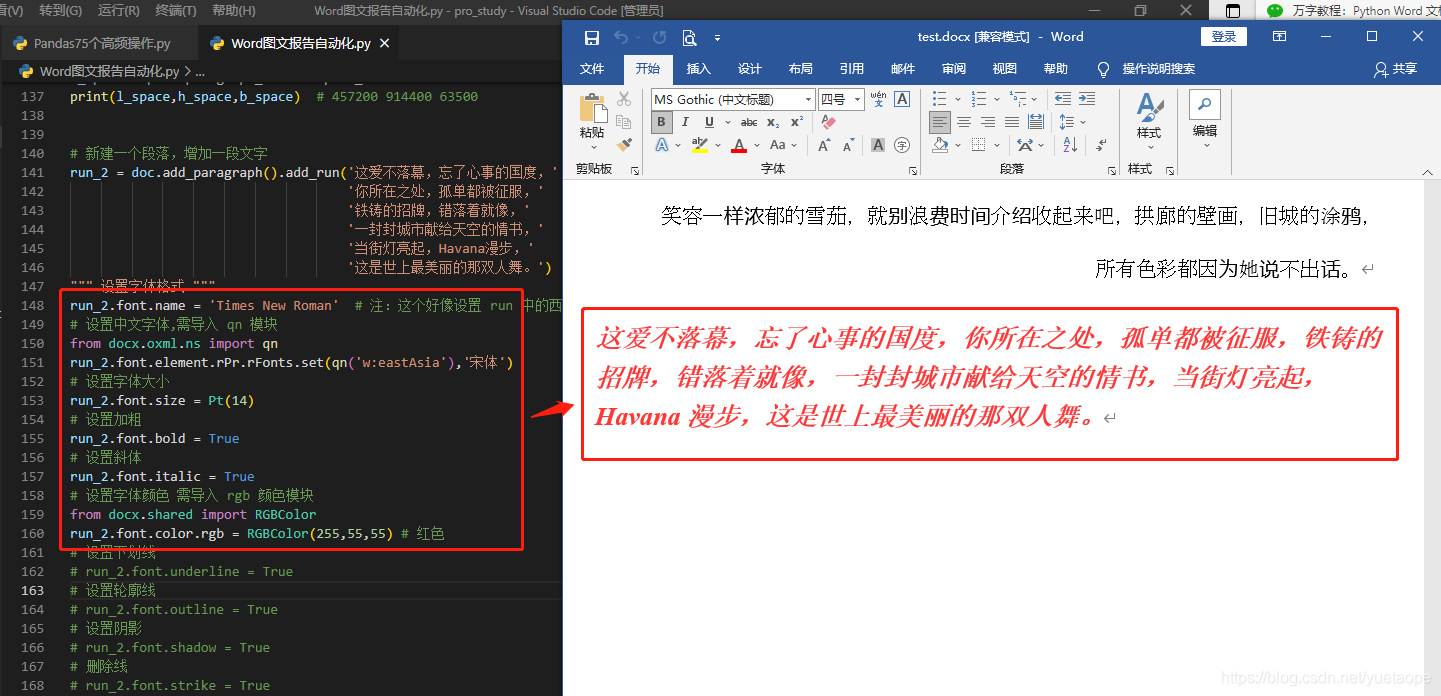
# 新建一个段落,增加一段文字
run_2 = doc.add_paragraph().add_run('这爱不落幕,忘了心事的国度,'
'你所在之处,孤单都被征服,'
'铁铸的招牌,错落着就像,'
'一封封城市献给天空的情书,'
'当街灯亮起,Havana漫步,'
'这是世上最美丽的那双人舞。')
""" 设置字体格式 """
run_2.font.name = 'Times New Roman' # 注:这个好像设置 run 中的西文字体
# 设置中文字体,需导入 qn 模块
from docx.oxml.ns import qn
run_2.font.element.rPr.rFonts.set(qn('w:eastAsia'),'宋体')
# 设置字体大小
run_2.font.size = Pt(14)
# 设置加粗
run_2.font.bold = True
# 设置斜体
run_2.font.italic = True
# 设置字体颜色 需导入 rgb 颜色模块
from docx.shared import RGBColor
run_2.font.color.rgb = RGBColor(255,55,55) # 红色
# 设置背景颜色
from docx.enum.text import WD_COLOR_INDEX
run_2.font.highlight_color = WD_COLOR_INDEX.YELLOW
"""
背景颜色可选值有:
'AUTO', 0, 'default'
'BLACK', 1, 'black'
'BLUE', 2, 'blue'
'BRIGHT_GREEN', 4, 'green',
'DARK_BLUE', 9, 'darkBlue',
'DARK_RED', 13, 'darkRed'
'DARK_YELLOW', 14, 'darkYellow'
'GRAY_25', 16, 'lightGray'
'GRAY_50', 15, 'darkGray'
'GREEN', 11, 'darkGreen'
'PINK', 5, 'magenta'
'RED', 6, 'red'
'TEAL', 10, 'darkCyan'
'TURQUOISE', 3, 'cyan'
'VIOLET', 12, 'darkMagenta'
'WHITE', 8, 'white'
'YELLOW', 7, 'yellow'
"""
# 设置下划线
# run_2.font.underline = True
# 设置轮廓线
# run_2.font.outline = True
# 设置阴影
# run_2.font.shadow = True
# 删除线
# run_2.font.strike = True
# 双删除线
# run_2.font.double_strike = True
# 设置下标
# run_2.font.subscript = True
# 设置上标
# run_2.font.superscript = True
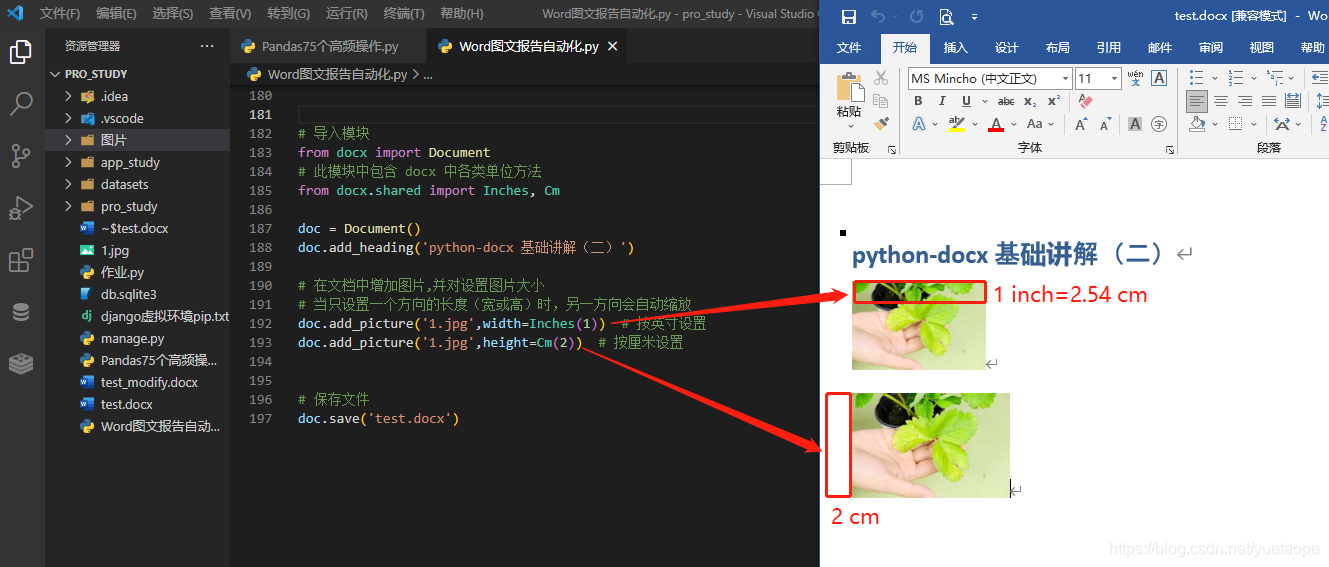
2.1.7 插入图片、设置大小
# 导入模块
from docx import Document
# 此模块中包含 docx 中各类单位方法
from docx.shared import Inches, Cm
doc = Document()
doc.add_heading('python-docx 基础讲解(二)')
# 在文档中增加图片,并对设置图片大小
# 当只设置一个方向的长度(宽或高)时,另一方向会自动缩放
doc.add_picture('1.jpg',width=Inches(1)) # 按英寸设置
doc.add_picture('1.jpg',height=Cm(2)) # 按厘米设置
2.1.8 插入表格、设置表格和单元格格式
# 导入模块
from docx import Document
# 此模块中包含 docx 中各类单位方法
from docx.shared import Inches, Cm
# 新建文档对象按模板新建 word 文档文件,具有模板文件的所有格式
doc = Document()
# 在文档中增加表格,并添加文字 "add_table(self, rows, cols, style=None):"
table1 = doc.add_table(2, 3) # 添加一个2行3列的表格,表格样式为None
# table1 = doc.add_table(2, 3, style ='Table Grid') # 添加一个2行3列的表格,表格样式为Table Grid
table1.cell(0,0).text = '0' # 给表格单元格赋值
# 获取表格对象所有单元格对象列表
print(table1._cells)
# ------运行结果------
# [<docx.table._Cell object at 0x000002131AF996C8>,
# <docx.table._Cell object at 0x000002131AF99608>,
# <docx.table._Cell object at 0x000002131AF99648>,
# <docx.table._Cell object at 0x000002131AF99688>,
# <docx.table._Cell object at 0x000002131AF99588>,
# <docx.table._Cell object at 0x000002131AF995C8>]
# ------运行结果------
# 对单元格对象设置文字
for i,cell in enumerate(table1._cells):
cell.text = str(i)
# 获取所有表格样式
from docx.enum.style import WD_STYLE_TYPE
styles = doc.styles
for style in styles:
if style.type == WD_STYLE_TYPE.TABLE:
print(style)
print(f'共有 {len(styles)} 种表格样式') # 共有 164 种表格样式
"""
可设置的表格样式:
_TableStyle('Normal Table') id: 187730312
_TableStyle('Table Grid') id: 187730312
_TableStyle('Light Shading') id: 187730376
_TableStyle('Light Shading Accent 1') id: 187730312
_TableStyle('Light Shading Accent 2') id: 187730376
_TableStyle('Light Shading Accent 3') id: 187730312
_TableStyle('Light Shading Accent 4') id: 187730376
_TableStyle('Light Shading Accent 5') id: 187730312
_TableStyle('Light Shading Accent 6') id: 187730376
_TableStyle('Light List') id: 187730312
...
"""
# 表格在创建时可及可指定格式:
# doc.add_table(2,3,style ='Table Grid' )
# 也可在创建后进行设置:
table1.style = 'Table Grid'
# 表格设置自动调整列宽,(默认也为真)
table1.autofit = True
# 为表格对象增加列,add_column(self, width)
table1.add_column(Inches(3)) # 需指定宽度
# 为表格对象增加行,add_row(self)
table1.add_row() # 只能逐行添加
table1.cell(0, 3).text = '这是增加的列'
table1.cell(2, 0).text = '这是增加的行'
# 获取行对象
row0 = table1.rows[0]
print(row0)
# 获取列对象
col0 = table1.columns[0]
# 获取表格一行的单元格对象列表
row0_cells = table1.row_cells(0)
print(row0_cells)
# 运行结果
# [<docx.table._Cell object at 0x000000000B311C88>,
# <docx.table._Cell object at 0x000000000B311AC8>,
# <docx.table._Cell object at 0x000000000B311B08>,
# <docx.table._Cell object at 0x000000000B311A48>]
# 获取一列的单元格对象列表
col_0_cells = table1.column_cells(0)
print(col_0_cells)
# 运行结果
# [<docx.table._Cell object at 0x000000000B312F88>,
# <docx.table._Cell object at 0x000000000B312CC8>,
# <docx.table._Cell object at 0x000000000B31A108>]
# 设置单元格对齐方式
# 垂直对齐方式:'TOP'-0, 'CENTER'-1, 'BOTTOM'-3, 'BOTH'-101
# 水平对齐方式:'LEFT'-0, 'CENTER'-1, 'RIGHT'-2
from docx.enum.table import WD_ALIGN_VERTICAL # 导入单元格垂直对齐
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT # 导入段落对齐
table1.cell(0,0).vertical_alignment = WD_ALIGN_VERTICAL.TOP
table1.cell(0,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 按行合并单元格,要继续合并的话,可用此单元格再次使用 merge 方法
cell_new = table1.cell(2,0).merge(table1.cell(2,1)).merge(table1.cell(2,2))
# 返回一个新单元格对象
print(cell_new)
# <docx.table._Cell object at 0x000000000B312F08>
# 按列合并单元格,要继续合并的话,可用此单元格再次使用 merge 方法
cell_new1 = table1.cell(0,3).merge(table1.cell(1,3)).merge(table1.cell(2,3))
cell_new1.vertical_alignment = WD_ALIGN_VERTICAL.CENTER # 垂直居中
cell_new1.paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 左右居中
cell_par = cell_new.paragraphs[0] # 获取到对象
# 设置单元格左右对齐方式
from docx.enum.text import WD_ALIGN_PARAGRAPH
cell_par.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 获取 run 对象
cell_run = cell_new.paragraphs[0].runs[0] # 单元格.段落.块
# 设置西文字体
cell_run.font.name = 'Times New Roman'
from docx.oxml.ns import qn
cell_run.font.element.rPr.rFonts.set(qn('w:eastAsia'),'黑体')
# 设置字体颜色
from docx.shared import RGBColor
cell_run.font.color.rgb = RGBColor(255,55,55) # 红色
最终效果

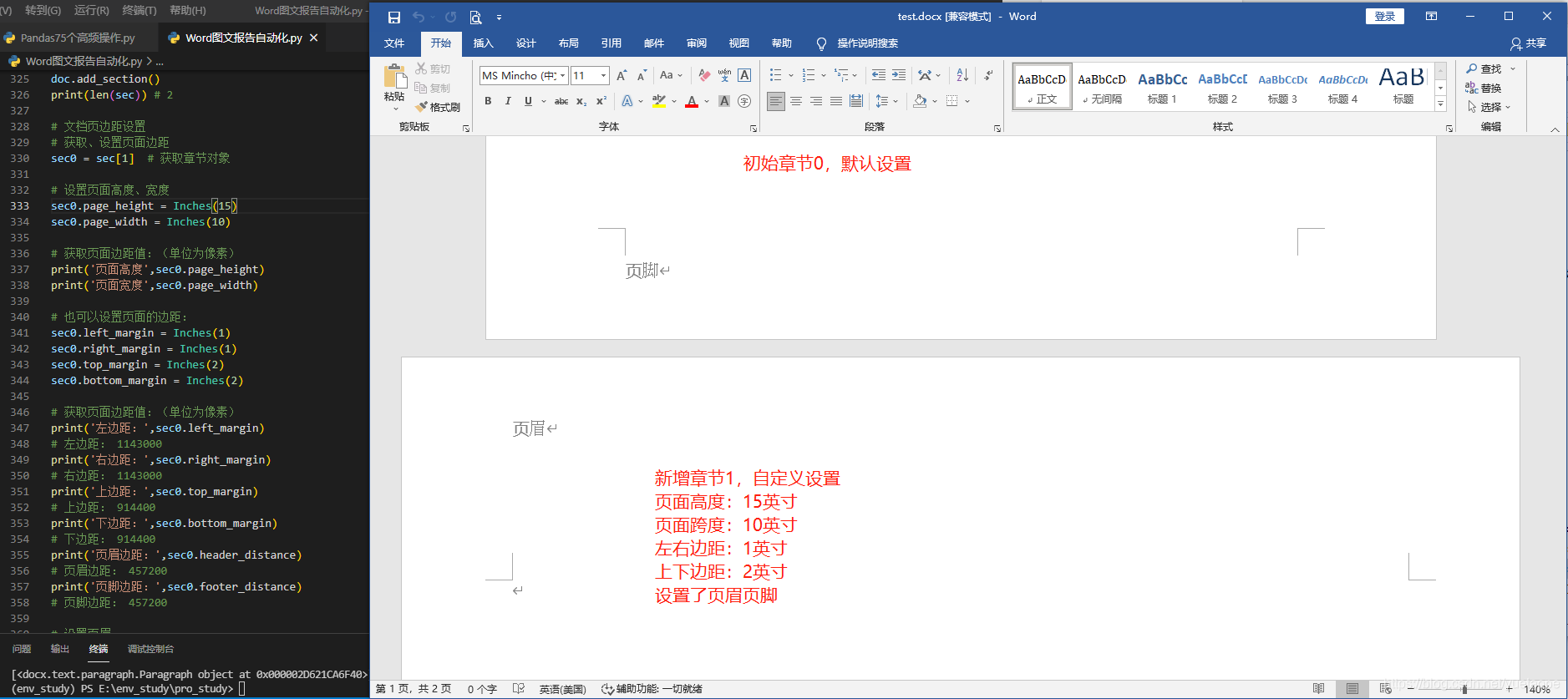
2.1.9 设置章节、页面设置、页边距、页眉、页脚
章节 也是 word 文档中一个块级元素,相较于段落块级元素它的范围应该更大一点。一般来说:一个 word 文档包含多个章节、一个章节包含多个 run 块级元素。
一个word文档被建立时至少包含一个章节:
# word文档中章节 section 对象
sec = doc.sections # 获取所有章节
print(sec) # <docx.section.Sections object at 0x000000000B312E88>
print(len(sec)) # 新建word文档只有1个章节
# 新建一个章节
doc.add_section()
print(len(sec)) # 2
# 文档页边距设置
# 获取、设置页面边距
sec0 = sec[1] # 获取章节对象
# 导入设置页面方向所需模块
from docx.enum.section import WD_ORIENT
# 设置页面方向
sec0.orientation = WD_ORIENT.LANDSCAPE # 横向
# 设置页面高度、宽度
sec0.page_height = Inches(15)
sec0.page_width = Inches(10)
# 获取页面边距值:(单位为像素)
print('页面高度',sec0.page_height)
print('页面宽度',sec0.page_width)
# 也可以设置页面的边距:
sec0.left_margin = Inches(1)
sec0.right_margin = Inches(1)
sec0.top_margin = Inches(2)
sec0.bottom_margin = Inches(2)
# 获取页面边距值:(单位为像素)
print('左边距:',sec0.left_margin)
# 左边距: 1143000
print('右边距:',sec0.right_margin)
# 右边距: 1143000
print('上边距:',sec0.top_margin)
# 上边距: 914400
print('下边距:',sec0.bottom_margin)
# 下边距: 914400
print('页眉边距:',sec0.header_distance)
# 页眉边距: 457200
print('页脚边距:',sec0.footer_distance)
# 页脚边距: 457200
# 设置页眉
head0 = sec0.header # 返回页眉对象
font0 = sec0.footer # 返回页脚对象
print(head0)
# <docx.section._Header object at 0x000000000B312E08>
print(font0)
# <docx.section._Footer object at 0x000000000B312B88>
# 查看页眉是否和上节一致
print(head0.is_linked_to_previous) # 默认为 True
# 设置页眉,页眉也是一个块级对象,里面也包含了 Paragraph 对象,所以对齐方式,文字格式设置方式和前文介绍一致。
print(head0.paragraphs)
head0_par = head0.paragraphs[0]
head0_par.add_run('页眉')
# 设置页脚,注: 设置页脚按序列增加的方式暂未找到
font0_par = font0.paragraphs[0]
font0_par.add_run('页脚')
最终效果
2.1.10 获取文档章节信息
用做示例的 test03.docx 文件截图如下:

文档中有两个章节共两页(一个章节一页),一个章节的页面为 A3 ,另一个为 A4。注意:章节对象的概念虽然比段落对象大,章节对象可以设置本章节的页面大小页眉页脚等,在该章节的段落对象必须遵守该章节的设置。但是又并不存在包含关系,也就是说不能通过章节对象获取到段落信息。
# Document 类,不仅可以新建word文档,也可以打开一个本地文档
doc = Document('test03.docx') # 想获取的文档文件名,这里是相对路径。
# 获取文档所有章节
sections = doc.sections
"class Sections(Sequence):"
print(sections)
# <docx.section.Sections object at 0x000000000B2E1148>
# 查看章节数量
print(len(sections)) # 2
# 获取章节对象的页边距等信息 "class Section(object):"
sec0 = sections[0] #这里获取的是第一个章节的页面信息,也就是 A3 页面的信息。
print(sec0)
# <docx.section.Section object at 0x000000000B2D5708>
# 获取章节页面信息
# 获取页面边距值:(单位为像素)
print('左边距:',sec0.left_margin)
# 左边距: 914400
print('右边距:',sec0.right_margin)
# 右边距: 914400
print('上边距:',sec0.top_margin)
# 上边距: 1143000
print('下边距:',sec0.bottom_margin)
# 下边距: 1143000
print('页眉边距:',sec0.header_distance)
# 页眉边距: 540385
print('页脚边距:',sec0.footer_distance)
# 页脚边距: 629920
print('页面方向:',sec0.orientation)
# 页面方向: LANDSCAPE (1)
print('页面高度:',sec0.page_height)
# 页面高度: 10657205
print('页面宽度:',sec0.page_width)
# 页面宽度: 15085695
head0 = sec0.header # 获取页眉对象
print(head0)
# <docx.section._Header object at 0x000000000B2E1348>
head0_pars = head0.paragraphs # 获取 页眉 paragraphs
# 获取页眉文字信息
# 因存在多个 paragraph 对象的可能所以用循环读取的方式
head0_string = ''
for par in head0_pars:
head0_string += par.text
print(head0_string) # 仪征市马集镇总体规划(2017-2030)——说明
# 获取页脚信息,也是类似的方法
foot0 = sec0.footer
print(foot0) # 获取页脚对象 # <docx.section._Footer object at 0x000000000B2E3808>
foot0_pars = foot0.paragraphs
foot0_string = ''
for par in foot0_pars:
foot0_string += par.text
print(foot0_string) # 1
2.1.11 获取段落文字信息
# 获取文档所有段落对象
paragraphs = doc.paragraphs
print(paragraphs)
print(len(paragraphs)) # 打印结果:20
# 获取一个段落对象的文字信息
par0 = paragraphs[0]
print(par0)
par0_string = par0.text
print(par0_string)
# 获取所有段落文字信息
pars_string = [par.text for par in paragraphs]
print(pars_string)
print('段落对齐方式:',par0.paragraph_format.alignment)
# 段落对齐方式: LEFT (0)
print('左缩进:',par0.paragraph_format.left_indent)
# 左缩进: None
print('右缩进:',par0.paragraph_format.right_indent)
# 右缩进: None
print('首行缩进:',par0.paragraph_format.first_line_indent)
# 首行缩进: 304800
print('行间距:',par0.paragraph_format.line_spacing)
# 行间距: 1.5
print('段前间距:',par0.paragraph_format.space_before)
# 段前间距: 198120
print('段后间距:',par0.paragraph_format.space_after)
# 段后间距: 198120
2.1.12 获取文字格式信息
paragraph 对象 里还有更小的 run 对象,run 对象才包含了段落对象的文字信息。paragraph.text 方法也是通过 run 对象的方法获取到文字信息的。
def text(self):
text = ''
for run in self.runs:
text += run.text
return text
# 获取文档所有段落对象
paragraphs = doc.paragraphs
print(paragraphs)
print(len(paragraphs)) # 打印结果:20
# 获取一个段落对象的文字信息
par0 = paragraphs[0]
# 获取段落的 run 对象列表
runs = par0.runs
print(runs)
# 获取 run 对象
run_0 = runs[0]
print(run_0.text) # 获取 run 对象文字信息
# 打印结果:
# 坚持因地制宜,差异化打造特色小镇,
# 获取文字格式信息
print('字体名称:',run_0.font.name)
# 字体名称: 宋体
print('字体大小:',run_0.font.size)
# 字体大小: 152400
print('是否加粗:',run_0.font.bold)
# 是否加粗: None
print('是否斜体:',run_0.font.italic)
# 是否斜体: True
print('字体颜色:',run_0.font.color.rgb)
# 字体颜色: FF0000
print('字体高亮:',run_0.font.highlight_color)
# 字体高亮: YELLOW (7)
print('下划线:',run_0.font.underline)
# 下划线: True
print('删除线:',run_0.font.strike)
# 删除线: None
print('双删除线:',run_0.font.double_strike)
# 双删除线: None
print('下标:',run_0.font.subscript)
# 下标: None
print('上标:',run_0.font.superscript)
# 上标: None
2.13 获取文档中表格信息
在介绍单元格格式信息时,说过单元格内文字信息也是通过 run 对象设置,故获取文字信息也和前面获取段落文字信息类似,就不重复了。

# 获取文档中表格信息
tables = doc.tables # 获取文档中所有表格对象的列表
print(tables)
# [<docx.table.Table object at 0x000001957059CD48>]
print(len(tables)) # 查看文档中表格数量
# 1
table0 = tables[0] # 获取表格对象
# 获取表格的样式信息
print(table0.style)
# _TableStyle('Normal Table') id: 190621384
# 获取一个表格的所有单元格
cells = table0._cells
print(len(cells)) # 表格中单元格数量
# 15
# 获取单元格内所有文字信息,用 tableobj._cells 获取到的单元格对象列表是按行排列的。
cells_string = [cell.text for cell in cells]
print(cells_string)
# 获取表格对象行数量、列数量
col_num = len(table0.columns)
print(col_num) # 3
# 行数量
row_num = len(table0.rows)
print(row_num) # 5
# 获取行对象
row0 = table0.rows[0]
# 获取列对象
col0 = table0.columns[0]
# 获取行对象文字信息
'要用 row0.cells 获取行对象的 cell 才能获取其文字信息'
row0_string = [cell.text for cell in row0.cells]
print(row0_string)
# 获取列对象文字信息
col0_string = [cell.text for cell in col0.cells]
print(col0_string)
2.2 win32com 操作 word 和 excel
2.2.1 win32com 将 doc 转为 docx
import os
from win32com import client as wc
def TransDocToDocx(oldDocName,newDocxName):
print("我是 TransDocToDocx 函数")
# 打开word应用程序
word = wc.Dispatch('Word.Application')
# 打开 旧word 文件
doc = word.Documents.Open(oldDocName)
# 保存为 新word 文件,其中参数 12 表示的是docx文件
doc.SaveAs(newDocxName, 12)
# 关闭word文档
doc.Close()
word.Quit()
print("生成完毕!")
if __name__ == "__main__":
# 获取当前目录完整路径
currentPath = os.getcwd()
print("当前路径为:",currentPath)
# 获取 旧doc格式word文件绝对路径名
docName = os.path.join(currentPath,'test.doc')
print("docFilePath = ", docName)
# 设置新docx格式文档文件名
docxName = os.path.join(currentPath,'test.docx')
TransDocToDocx(docName,docxName)
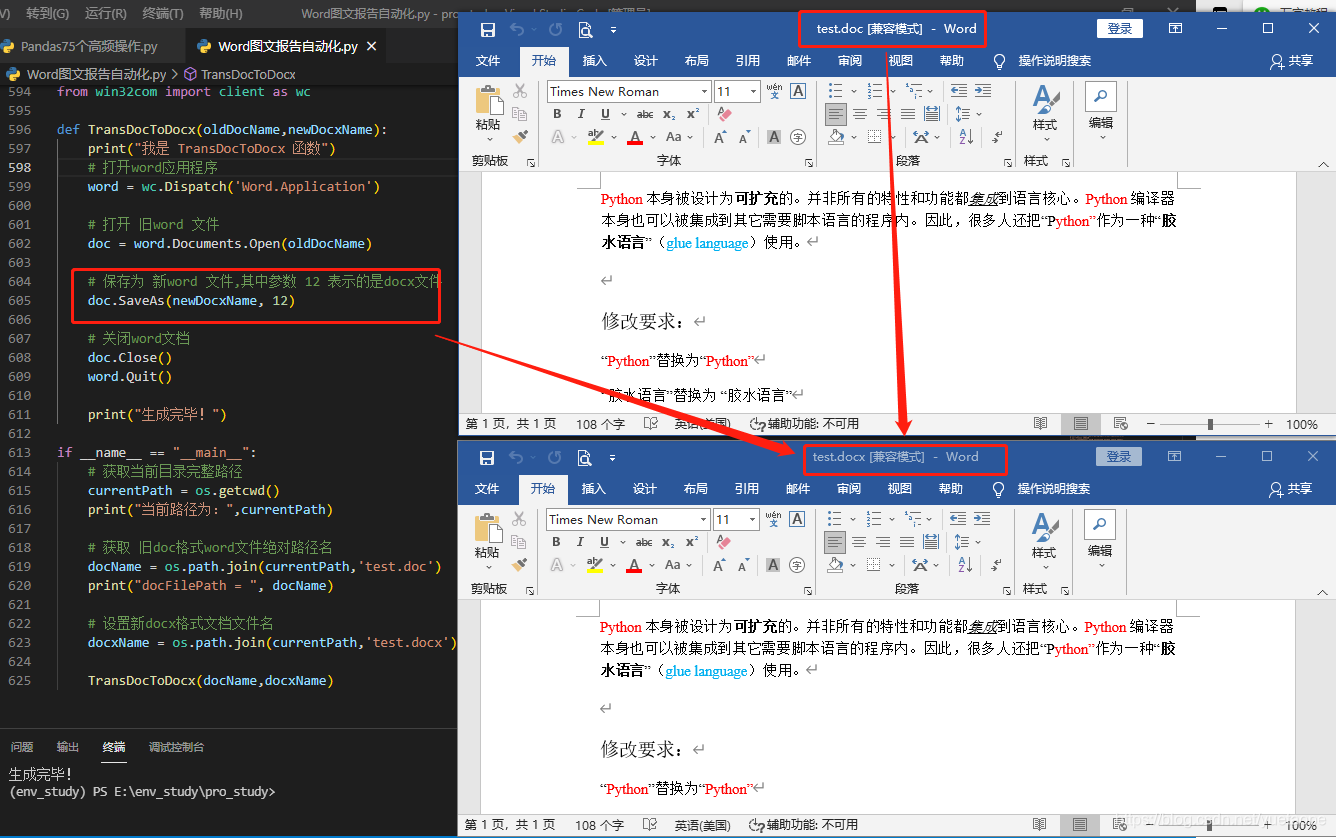
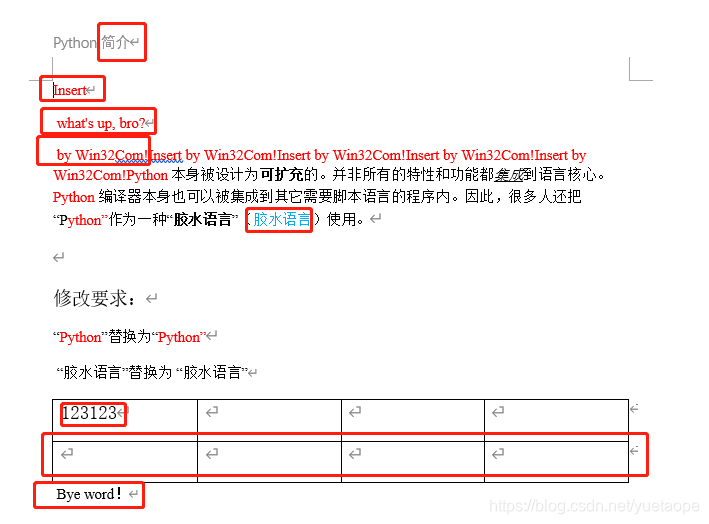
2.2.2 Win32com 操作word 插入文字、替换文字、表格插入行、保存关闭
代码运行前:

import win32com
from win32com.client import Dispatch, constants
import os
try:
w = win32com.client.Dispatch('Word.Application')
# 或者使用下面的方法,使用启动独立的进程:
# w = win32com.client.DispatchEx('Word.Application')
# 后台运行,不显示,不警告
w.Visible = 0
w.DisplayAlerts = 0
# 打开新的文件
doc = w.Documents.Open(os.getcwd() + r'\test.docx')
# worddoc = w.Documents.Add() # 创建新的文档
# 在文档开头插入文字
myRange = doc.Range(0,0)
myRange.InsertBefore('Insert by Win32Com!')
# 在文档末尾添加内容
myRange2 = doc.Range()
myRange2.InsertAfter('\n Bye word!\n')
# 在文档i指定位置添加内容
i = 6
myRange3 = doc.Range(1, i)
myRange3.InsertAfter("\n what's up, bro?\n")
# 使用样式
wordSel = myRange.Select()
# wordSel.Style = constants.wdStyleHeading1
# 正文文字替换
w.Selection.Find.ClearFormatting()
w.Selection.Find.Replacement.ClearFormatting()
w.Selection.Find.Execute('glue language', False, False, False, False, False, True, 1, True, '胶水语言', 2)
# 页眉文字替换
w.ActiveDocument.Sections[0].Headers[0].Range.Find.ClearFormatting()
w.ActiveDocument.Sections[0].Headers[0].Range.Find.Replacement.ClearFormatting()
w.ActiveDocument.Sections[0].Headers[0].Range.Find.Execute('介绍', False, False, False, False, False, True, 1, False, '简介', 2)
# 表格操作
doc.Tables[0].Rows[0].Cells[0].Range.Text ='123123'
doc.Tables[0].Rows.Add() # 增加一行
# 打印
doc.PrintOut()
# 另存为
doc.SaveAs(os.getcwd() + r'\test_modify.docx')
except Exception as e:
print(e)
finally:
doc.Close()
w.Quit()
代码运行后:
2.2.3 Win32com 操作 excel 插入图片
# -*- coding: utf-8 -*-
from win32com.client import Dispatch
import win32com.client
class easyExcel:
"""A utility to make it easier to get at Excel. Remembering
to save the data is your problem, as is error handling.
Operates on one workbook at a time."""
def __init__(self, filename=None):
self.xlApp = win32com.client.Dispatch('Excel.Application')
if filename:
self.filename = filename
self.xlBook = self.xlApp.Workbooks.Open(filename)
else:
self.xlBook = self.xlApp.Workbooks.Add()
self.filename = ''
def save(self, newfilename=None):
if newfilename:
self.filename = newfilename
self.xlBook.SaveAs(newfilename)
else:
self.xlBook.Save()
def close(self):
self.xlBook.Close(SaveChanges=0)
del self.xlApp
def getCell(self, sheet, row, col):
"Get value of one cell"
sht = self.xlBook.Worksheets(sheet)
return sht.Cells(row, col).Value
def setCell(self, sheet, row, col, value):
"set value of one cell"
sht = self.xlBook.Worksheets(sheet)
sht.Cells(row, col).Value = value
def getRange(self, sheet, row1, col1, row2, col2):
"return a 2d array (i.e. tuple of tuples)"
sht = self.xlBook.Worksheets(sheet)
return sht.Range(sht.Cells(row1, col1), sht.Cells(row2, col2)).Value
def addPicture(self, sheet, pictureName, Left, Top, Width, Height):
"Insert a picture in sheet"
sht = self.xlBook.Worksheets(sheet)
sht.Shapes.AddPicture(pictureName, 1, 1, Left, Top, Width, Height)
def cpSheet(self, before):
"copy sheet"
shts = self.xlBook.Worksheets
shts(1).Copy(None,shts(1))
if __name__ == "__main__":
PNFILE = r'E:\env_study\pro_study\1.jpg'
xls = easyExcel(r'E:\env_study\pro_study\test.xlsx')
xls.addPicture('Sheet1', PNFILE, 20,20,1000,1000)
xls.cpSheet('Sheet1')
xls.save()
xls.close()
最终效果:
2.2.4 Win32com 转换word为pdf
# 转换word为pdf
from win32com.client import Dispatch, constants
import os
# 生成Pdf文件
def funGeneratePDF():
word = Dispatch("Word.Application")
word.Visible = 0 # 后台运行,不显示
word.DisplayAlerts = 0 # 不警告
doc = word.Documents.Open(os.getcwd() + r"\test.docx") # 打开一个已有的word文档
doc.SaveAs(os.getcwd() + r"\test.pdf", 17) # txt=4, html=10, docx=16, pdf=17
doc.Close()
word.Quit()
if __name__ == '__main__':
funGeneratePDF()
三、案例
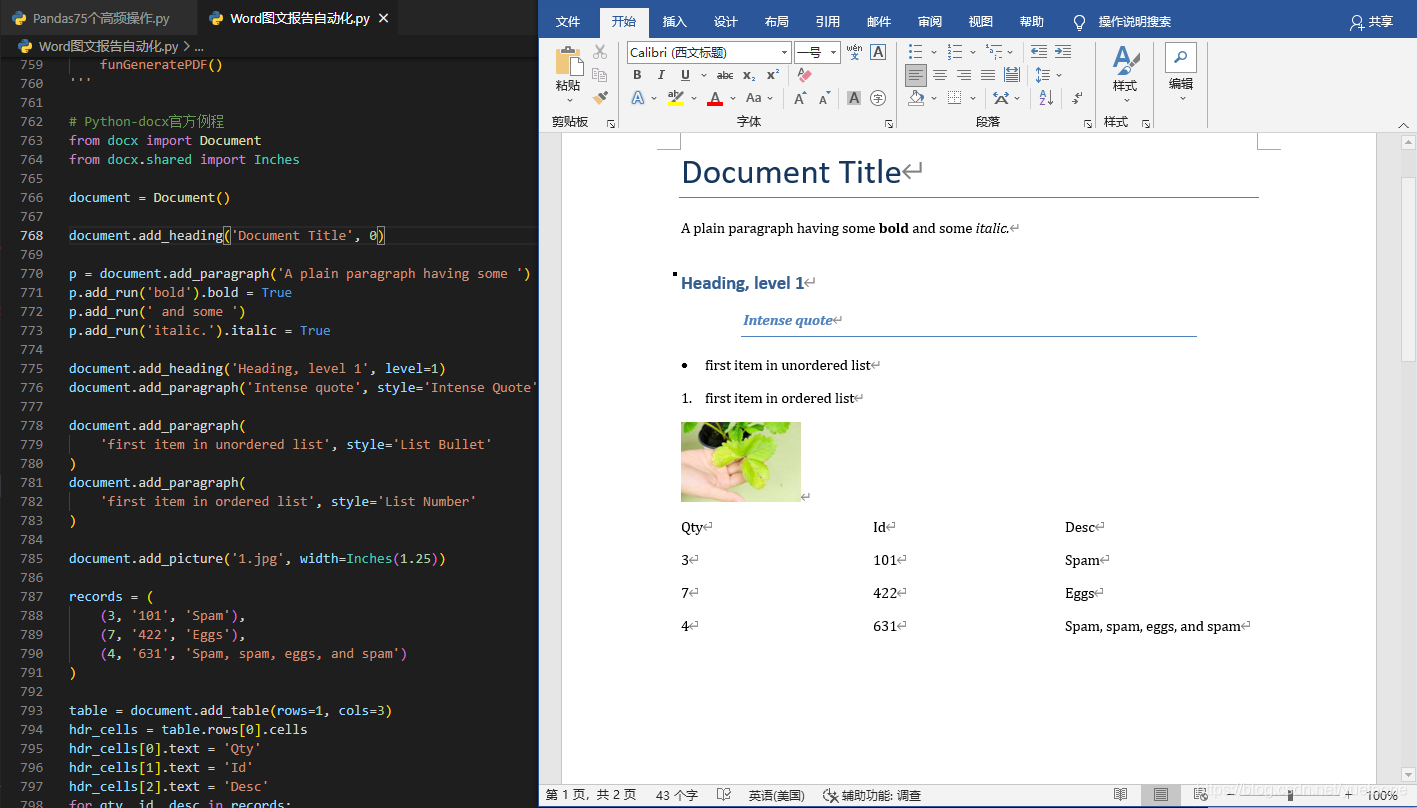
3.1 Python-docx官方例程
# Python-docx官方例程
from docx import Document
from docx.shared import Inches
document = Document()
document.add_heading('Document Title', 0)
p = document.add_paragraph('A plain paragraph having some ')
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote')
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'first item in ordered list', style='List Number'
)
document.add_picture('1.jpg', width=Inches(1.25))
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
document.save('4.1 Python-docx官方例程.docx')
3.2 市民水电费缴费通知单
用水电气数据已经统计在一个 Excel 文件中,Excel 表格数据如下:
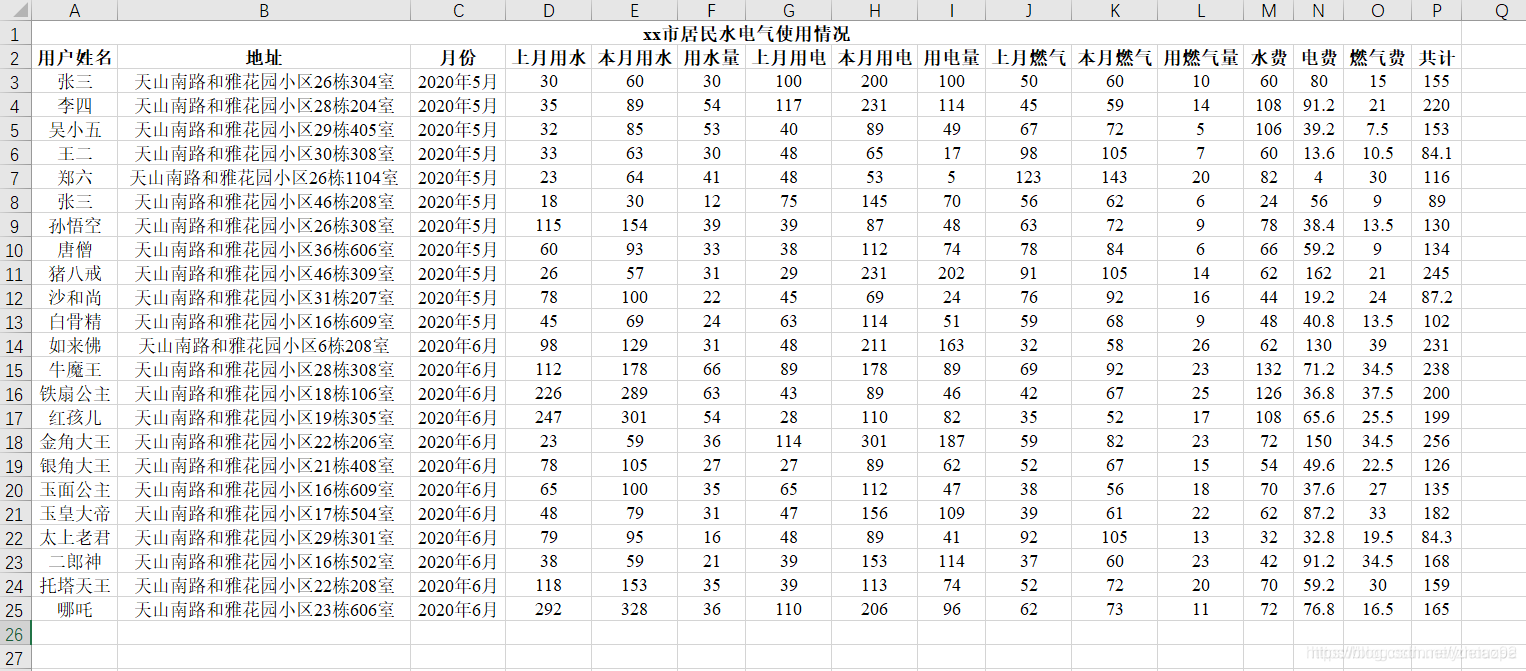
分析:
从需求上来看,核心功能就是要: 读取模板文件,在不改变模板文件中段落、文字格式的前提下,根据数据内容替换部分文字。
根据需要,调整的 Word 模板文件截图:

批量生成的缴费通知文件截图:
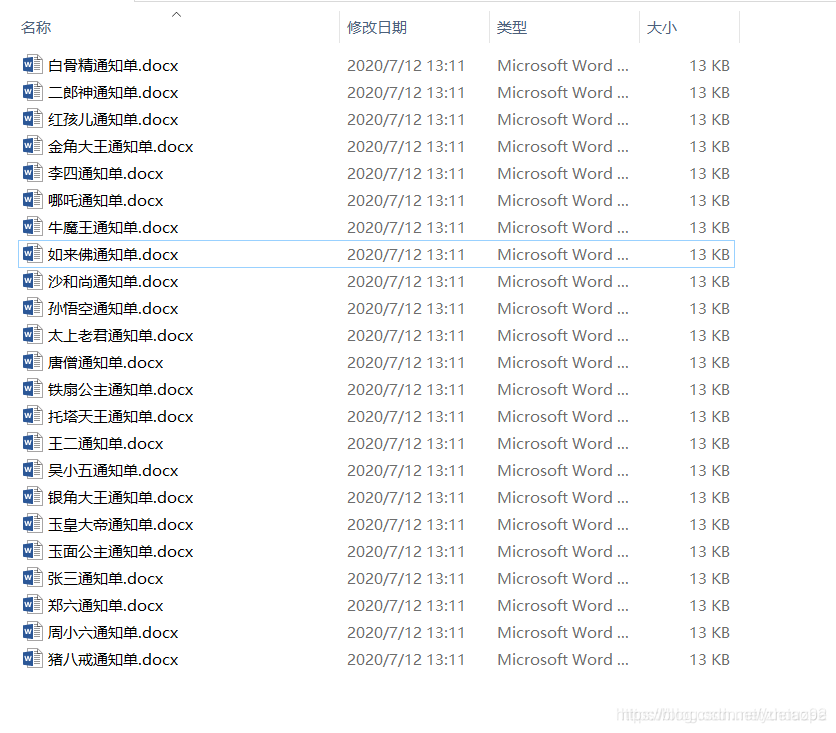
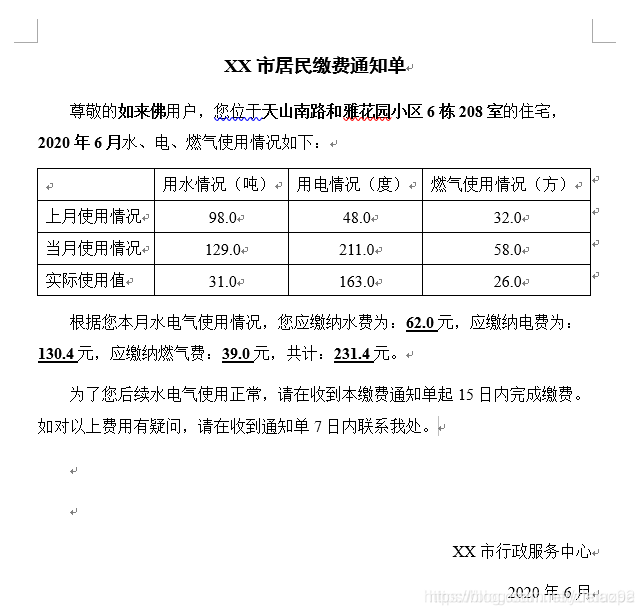
# 导入模块
import xlrd
import docx
# 定义获取 word 模板正文段落、表格 run 对象函数
def get_runs(path):
doc = docx.Document(path)
runs_g = []
# 获取段落 run 对象
for par_g in doc.paragraphs:
for run_g in par_g.runs:
runs_g.append(run_g)
# 获取表格 run 对象
table_g = doc.tables[0]
for cell_g in table_g._cells:
for cell_par_g in cell_g.paragraphs:
for cell_run_g in cell_par_g.runs:
runs_g.append(cell_run_g)
return doc,runs_g
# 读取 Excel 文件数据
excel_obj = xlrd.open_workbook('el01.xlsx')
# 获取 sheet
sheet = excel_obj.sheet_by_index(0)
# 按行读取所有数据
excel_data = sheet._cell_values
# 需制作缴费通知单数据
notice_data = excel_data[2:]
# 模板内设置的标志:
tags_1 = ['用户姓名','用户居住地址','通知月份',
'上月用水','本月用水','实际用水',
'上月用电','本月用电','实际用电',
'上月用气','本月用气','实际用气',
'本月水费','本月电费','本月燃气费',
'总计费用']
# 遍历需制作缴费单数据
for ds in notice_data:
# 构建替换数据字典
notice_dict = dict(zip(tags_1,ds))
# 创建 word、run 列表
doc_t,runs_t = get_runs('test01.docx')
# 遍历模板run对象 和 notice_dict key 匹配
# 匹配成功则替换 run 内容
for run_t in runs_t:
if run_t.text in notice_dict.keys():
run_t.text = str(notice_dict[run_t.text])
doc_t.save('outpath/%s通知单.docx' % ds[0])
3.3 docx&matplotlib 自动生成数据分析报告
原始数据:
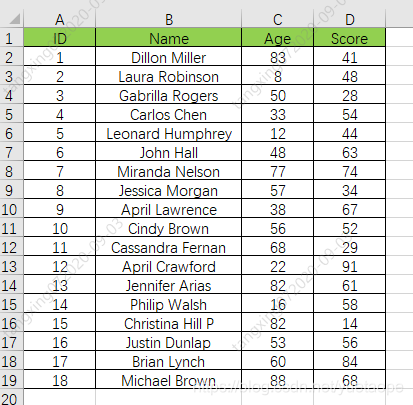
import xlrd
import matplotlib
import matplotlib.pyplot as plt
from docx import Document
from docx.shared import Inches
# 获取学习成绩信息
def GetExcelInfo():
print("开始获取表格内容信息")
# 打开指定文档
xlsx = xlrd.open_workbook('学生成绩表格.xlsx')
# 获取sheet
sheet = xlsx.sheet_by_index(0)
# 获取表格行数
nrows = sheet.nrows
print("一共 ",nrows," 行数据")
# 获取第2列,和第4列 所有值(列表生成式),从第2行开始获取
nameList = [str(sheet.cell_value(i, 1)) for i in range(1, nrows)]
scoreList = [int(sheet.cell_value(i, 3)) for i in range(1, nrows)]
# 返回名字列表和分数列表
return nameList,scoreList
# 生成学生成绩柱状图(使用matplotlib)
# 会生成一张名为"studentScore.jpg"的图片
def GenerateScorePic(scoreList):
# 解析成绩列表,生成横纵坐标列表
xNameList = [str(studentInfo[0]) for studentInfo in scoreList]
yScoreList = [int(studentInfo[1]) for studentInfo in scoreList]
print("xNameList",xNameList)
print("yScoreList",yScoreList)
# 设置字体格式
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用黑体显示中文
# 设置绘图尺寸
plt.figure(figsize=(10,5))
# 绘制图像
plt.bar(x=xNameList, height=yScoreList, label='学生成绩', color='steelblue', alpha=0.8)
# 在柱状图上显示具体数值, ha参数控制水平对齐方式, va控制垂直对齐方式
for x1, yy in scoreList:
plt.text(x1, yy + 1, str(yy), ha='center', va='bottom', fontsize=16, rotation=0)
# 设置标题
plt.title("学生成绩柱状图")
# 为两条坐标轴设置名称
plt.xlabel("学生姓名")
plt.ylabel("学生成绩")
# 显示图例
plt.legend()
# 坐标轴旋转
plt.xticks(rotation=90)
# 设置底部比例,防止横坐标显示不全
plt.gcf().subplots_adjust(bottom=0.25)
# 保存为图片
plt.savefig("studentScore.jpg")
# 直接显示
plt.show()
# 开始生成报告
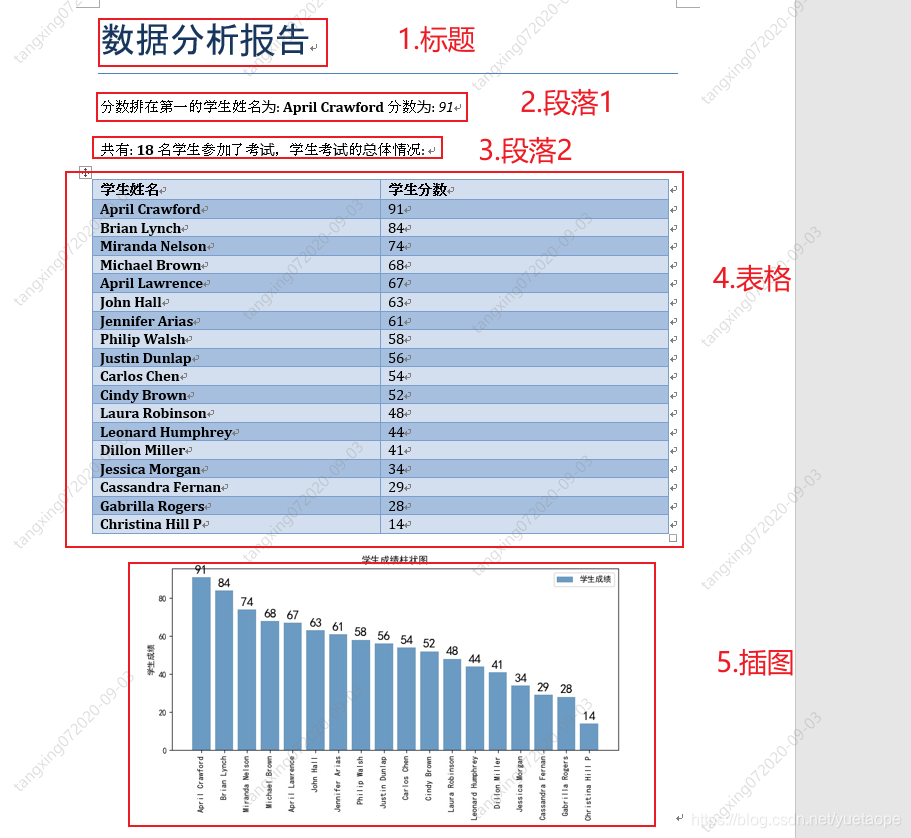
def GenerateScoreReport(scoreOrder,picPath):
# 新建一个文档
document = Document()
# 设置标题
document.add_heading('数据分析报告', 0)
# 添加第一名的信息
p1 = document.add_paragraph("分数排在第一的学生姓名为: ")
p1.add_run(scoreOrder[0][0]).bold = True
p1.add_run(" 分数为: ")
p1.add_run(str(scoreOrder[0][1])).italic = True
# 添加总体情况信息
p2 = document.add_paragraph("共有: ")
p2.add_run(str(len(scoreOrder))).bold = True
p2.add_run(" 名学生参加了考试,学生考试的总体情况: ")
# 添加考试情况表格
table = document.add_table(rows=1, cols=2)
table.style = 'Medium Grid 1 Accent 1'
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '学生姓名'
hdr_cells[1].text = '学生分数'
for studentName,studentScore in scoreOrder:
row_cells = table.add_row().cells
row_cells[0].text = studentName
row_cells[1].text = str(studentScore)
# 添加学生成绩柱状图
document.add_picture(picPath, width=Inches(6))
document.save('学生成绩报告.docx')
if __name__ == "__main__":
# 调用信息获取方法,获取用户信息
nameList,scoreList = GetExcelInfo()
# print("nameList:",nameList)
# print("ScoreList:",scoreList)
# 将名字和分数列表合并成字典(将学生姓名和分数关联起来)
scoreDictionary = dict(zip(nameList, scoreList))
# print("dictionary:",scoreDictionary)
# 对字典进行值排序,高分在前,reverse=True 代表降序排列
scoreOrder = sorted(scoreDictionary.items(), key=lambda x: x[1], reverse=True)
# print("scoreOrder",scoreOrder)
# 将进行排序后的学生成绩列表生成柱状图
GenerateScorePic(scoreOrder)
# 开始生成报告
picPath = "studentScore.jpg"
GenerateScoreReport(scoreOrder,picPath)
print("任务完成,报表生成完毕!")
最终结果
3.4 docx-mailmerge 自动生成万份劳动合同
3.4.1 创建合同模板

创建一个域
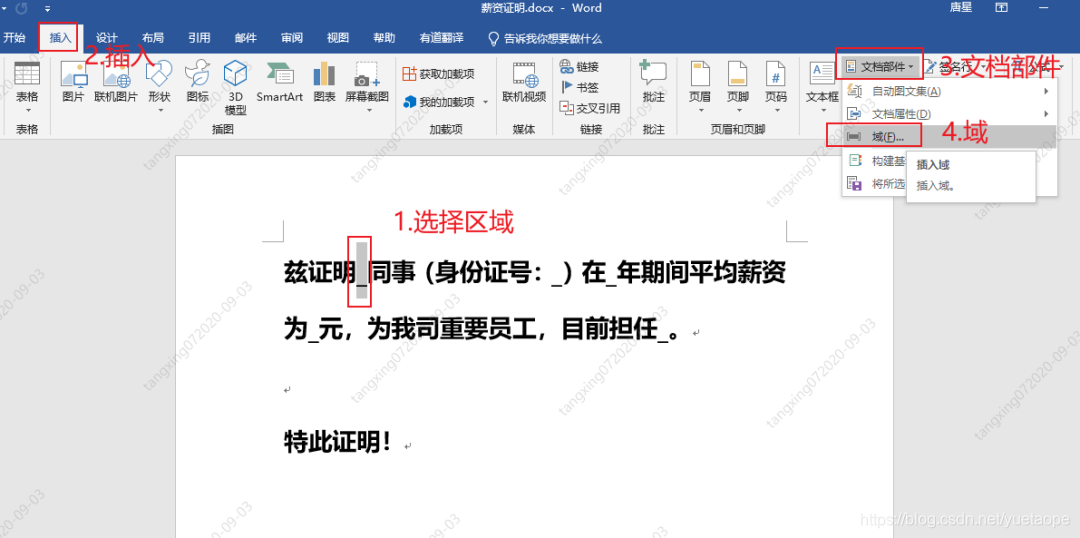
设置域名
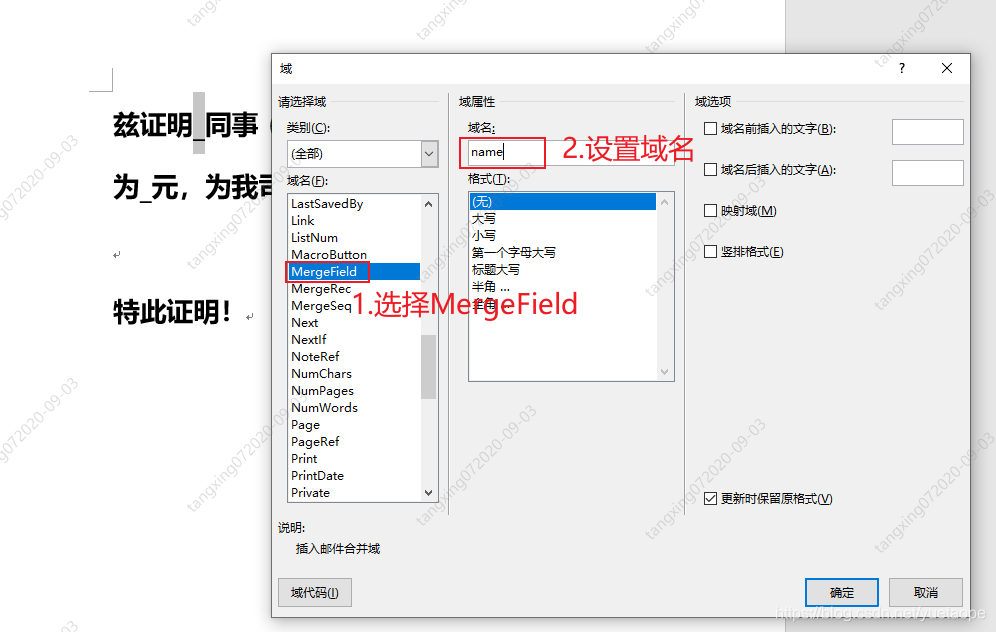
添加一个完成

依次全部添加

from mailmerge import MailMerge
from datetime import datetime
# 生成单份合同
def GenerateCertify(templateName,newName):
# 打开模板
document = MailMerge(templateName)
# 替换内容
document.merge(name='唐星',
id='1010101010',
year='2020',
salary='99999',
job='嵌入式软件开发工程师')
# 保存文件
document.write(newName)
if __name__ == "__main__":
templateName = '薪资证明模板.docx'
# 获得开始时间
startTime = datetime.now()
# 开始生成
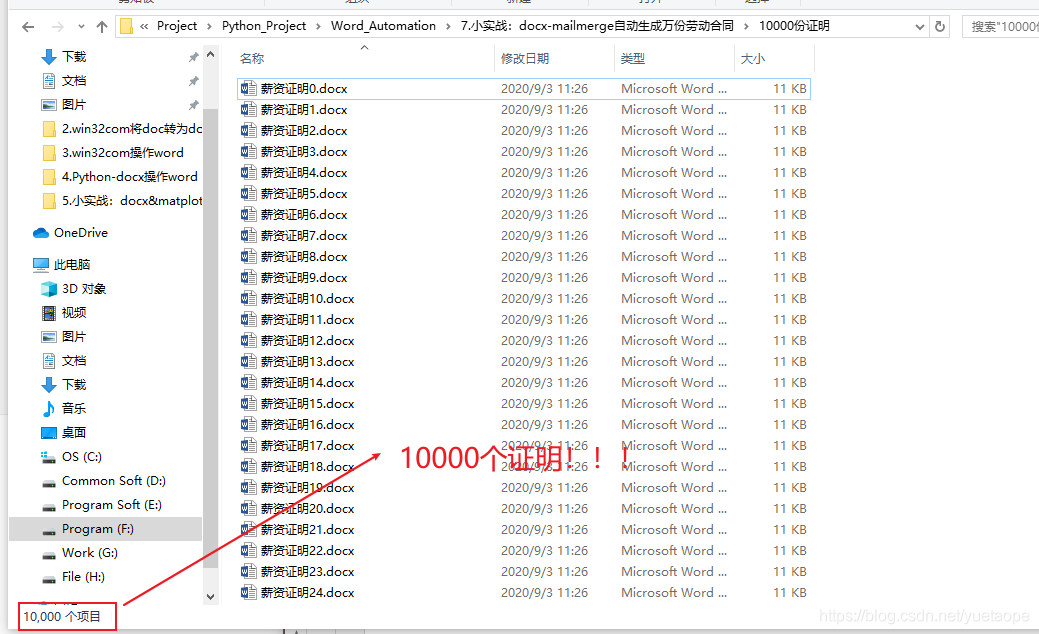
for i in range(10000):
newName = f'./10000份证明/薪资证明{i}.docx'
GenerateCertify(templateName,newName)
# 获取结束时间
endTime = datetime.now()
# 计算时间差
allSeconds = (endTime - startTime).seconds
print("生成10000份合同一共用时: ",str(allSeconds)," 秒")
print("程序结束!")


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 44
44 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)