数据可视化 - Streamlit实现页面组件交互与展示(以K-Means为例)
一、简介本人数据分析小白,最近接触到了Streamlit这个组件,发现真的很好用!尤其是它提供的交互功能,可以让很多数据分析的结果清晰直观地展现在页面上,比起手动修改参数,一遍一遍rerun,真的舒服了不少~~因此这篇文章将以K-Means模型为例,采用iris数据集,介绍如何使用streamlit进行数据交互可视化。1.1 成品图1.2 相关库与版本需要使用的第三方库,以及我的版本如下:库名称版
一、简介
本人数据分析小白,最近接触到了Streamlit这个组件,发现真的很好用!尤其是它提供的交互功能,可以让很多数据分析的结果清晰直观地展现在页面上,比起手动修改参数,一遍一遍rerun,真的舒服了不少~~因此这篇文章将以K-Means模型为例,采用iris数据集,介绍如何使用streamlit进行数据交互可视化。
1.1 成品图
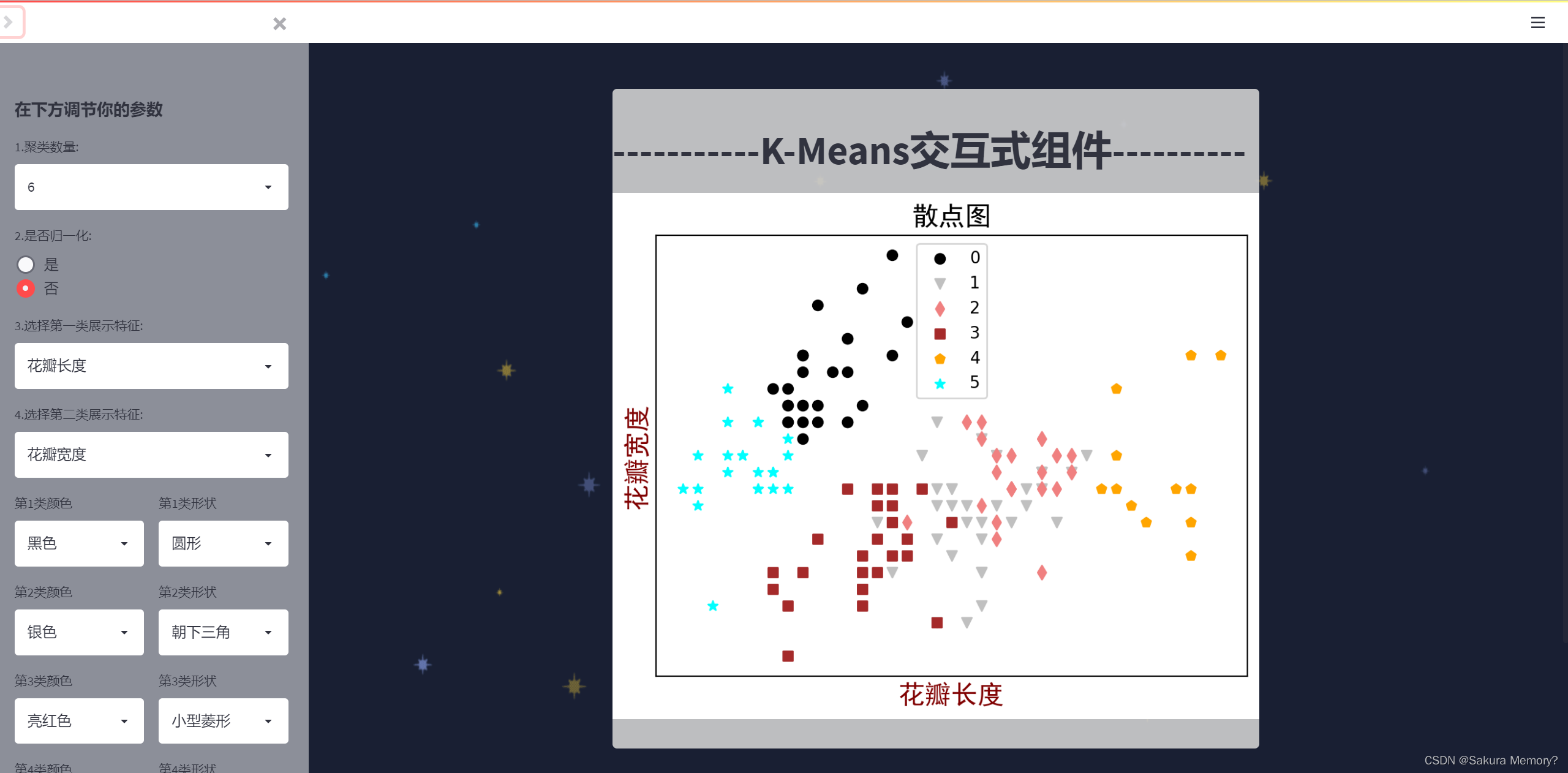
1.2 相关库与版本
需要使用的第三方库,以及我的版本如下:
| 库名称 | 版本 |
|---|---|
| streamlit | 1.9.0 |
| pandas | 1.1.5 |
| numpy | 1.22.3 |
| sklearn | 0.23.1 |
| matplotlib | 3.2.1 |
以下是补习推荐网址:
Streamlit:一个傻瓜式构建可视化 web的 Python 神器 -- streamlit - 知乎 (zhihu.com)
其他库建议去菜鸟或者官网学习(或者在本文遇到不懂的可以直接百度)
二、交互原理
Streamlit的功能是实现图形可视化、以及提供交互式的点击框、选择框等。最简单的方式就是在代码框里一顿操作把最后的结果画成图,并展示在页面上。而交互式页面的原理就是在前面的基础上多了赋值这一个操作,有点类似Shell中等待输入的Input,赋值方式在页面中变成了选框。
2.1 一张很丑的自制原理图
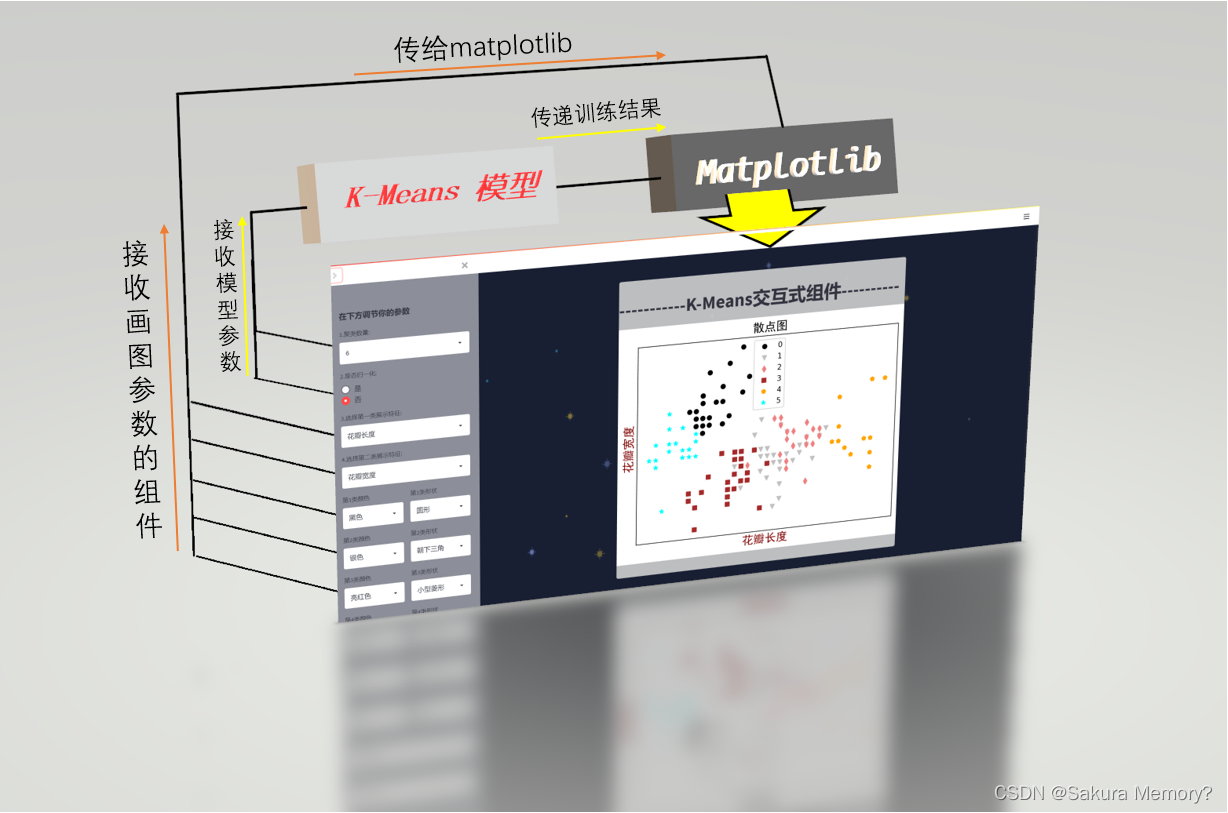
(u1s1,画图3D真好用!)
先从左边的侧边栏上方(黄线流程)看起,最基本的操作就是通过选择(Streamlit提供了下拉框和圆点的选择功能)值,并将值赋给变量,再将变量传输给模型。(选择 ----> 赋值 ----> 传递 ----> 模型)
代码实现如下
a = st.selectbox('1.你想要设置的值:', ['1', '2'])) # 一定要赋值,不然选择框就只是拿来点一下玩一年的摆设
output = model(variable=a) # model就是你想使用的分析模型,需要接受参数variable,才能返回结果
print(output) # 得到了结果传递给模型训练完以后,得到训练结果,就可以让 Matplotlib 进行画图了,这是最基本的一条运作原理。
(好嘞,现在你已经学会了基本操作,让我们开始单挑最终Boss吧!)
在实现了基本的画图后,就可以开始对图像进行更多的处理了,Matplotlib画出来的原始图像并不是很美观,但是也足够进行观察了(但是我就是想让它高级一点,嘿嘿嘿);侧边栏下方(橙线流程)就是通过其他的变量去对图表的各种属性进行调整,从而达到交互式图表的效果。
三、代码部分
3.1 省流版(黄线流程)
首先导入库
import numpy as np
import pandas as pd
import streamlit as st
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler然后在终端输入 Streamlit run (你的文件名).py

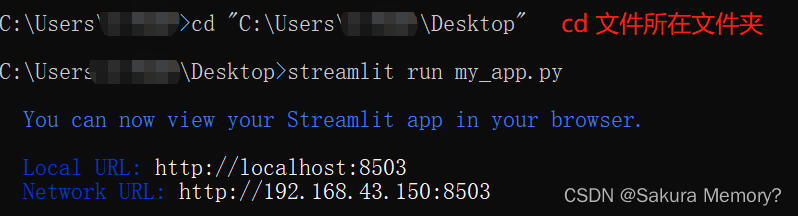
我用的是pycharm,如果是使用Jupyter或者Spyder的小伙伴,可以通过Win + R打开命令窗口,输入 cmd,打开小黑窗后,读取你的Streamlit文件的路径
比如你的.py文件在桌面,就在小黑窗输入 cd C:\Users\Desktop (路径因人而异)
然后再输入 streamlit run (你的文件名).py 就可以啦
接着开始构建页面内容(倒数两行的赋值就是第1条黄线<接受模型参数>的操作)
# streamlit的页面布局顺序是与代码位置一致的,因此我先在最前面加一个大标题
st.title('K-Means交互式组件'.center(33, '-'))
# 设置侧边栏 Tips:所有侧边栏的元素都必须在前面加上 sidebar,不然会在主页显示
st.sidebar.expander('') # expander必须接受一个 label参数,我这里留了一个空白
st.sidebar.subheader('在下方调节你的参数') # 副标题
# st.selectbox:创造一个下拉选择框的单选题,接收参数: (题目名称, 题目选项)
cluster_class = st.sidebar.selectbox('1.聚类数量:', list(range(2, 10))) # 选择聚类中心,并赋值
minmaxscaler = st.sidebar.radio('2.是否归一化:', ['是', '否']) # 选择是否标准化这样网页最原始的模样就有了(👆👆一定要赋值,不赋值的话,页面选择是不会返回结果的)

然后就是数据、模型的调用和训练
# 调用数据,经典艾瑞斯
iris = load_iris()
data = iris['data']
if minmaxscaler == '是': # 根据页面中的选择进行判断是否归一化
model_mms = MinMaxScaler().fit(data) # 调用归一标准化方法(也可以自己写一个函数处理)
data = model_mms.transform(data) # 对 data进行标准化
# 调用模型,这里用K-Means
model = KMeans(n_clusters=cluster_class).fit(data) # 这里的 cluster_class就是刚刚选框接收到的值(聚成几类)
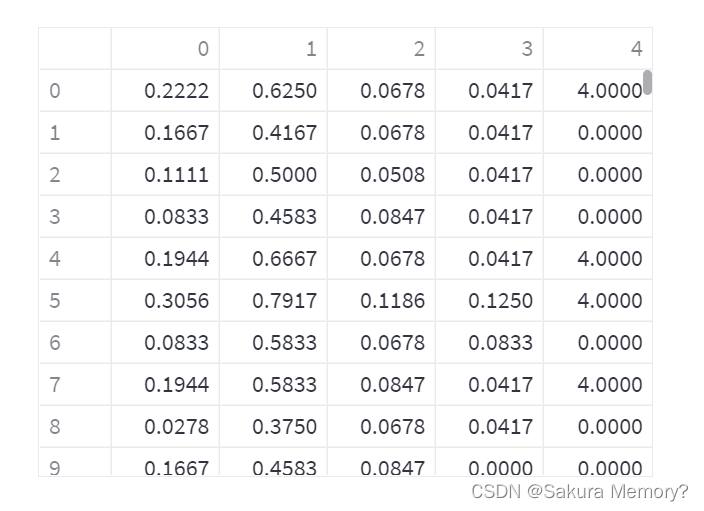
data_done = np.c_[data, model.labels_] # 将结果和数据合并,model.lables:模型训练得到的标签这时模型已经训练好了,可以用st.dataframe(data_done)查看结果👇(第“4”列就是聚类结果)
最后通过matplotlib.pyplot画图
fig, ax = plt.subplots() # 创建画布与子图
for i in set(model.labels_): # 选中每一个聚出来的类
index = data_done[:, -1] == i # 得到每一个类对应的布尔值索引
x = data_done[index, 0] # 第一特征:花瓣长 Tips:iris有四个特征,自己手动选两个
y = data_done[index, 1] # 第二特征:花瓣宽
ax.scatter(x, y) # 做出散点图
st.pyplot(fig) # 画出来!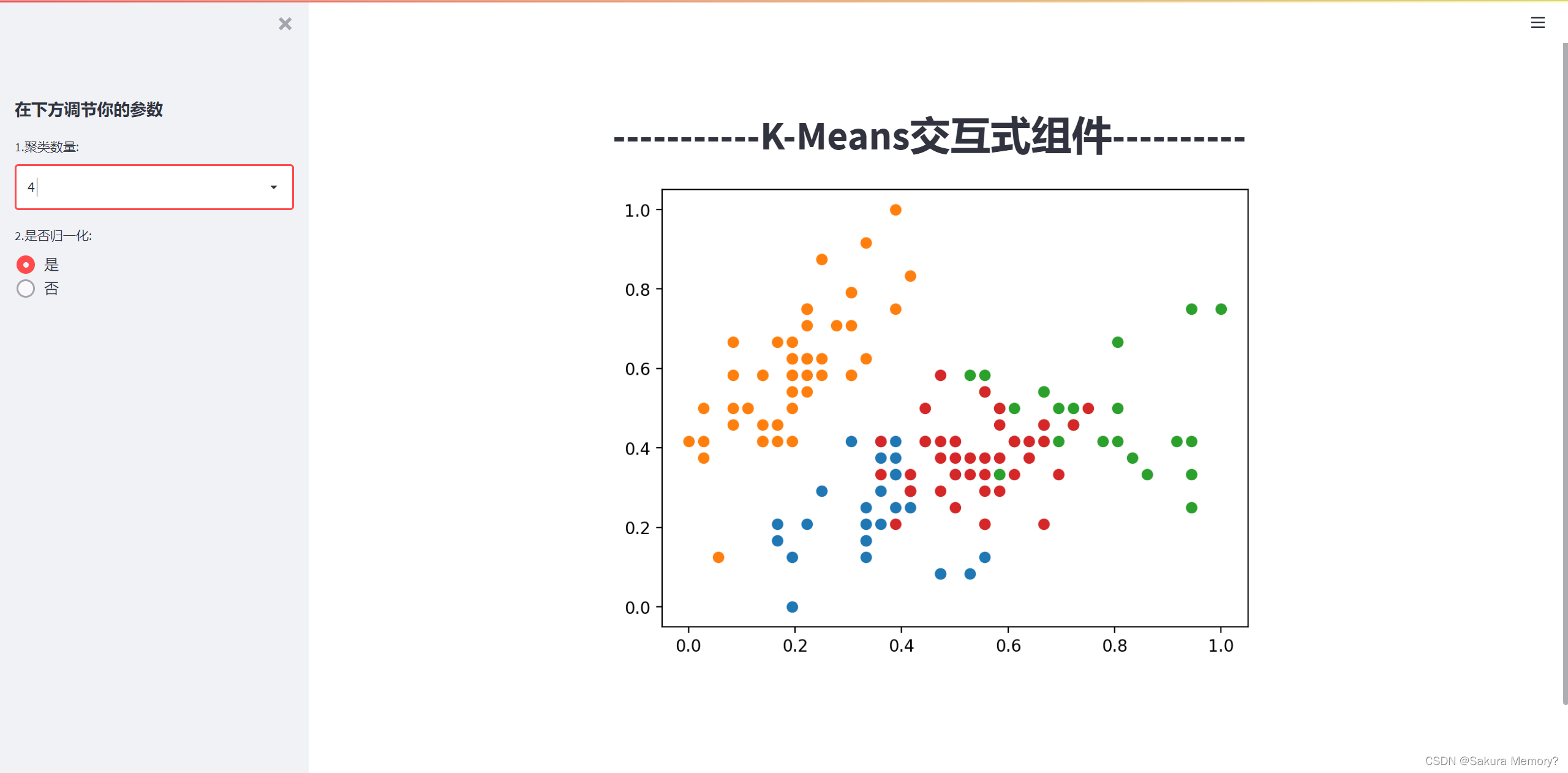
成功!
省流版完整代码如下:
import numpy as np
import pandas as pd
import streamlit as st
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
# streamlit的页面布局顺序是与代码位置一致的,因此我先在最前面加一个大标题
st.title('K-Means交互式组件'.center(33, '-'))
# 调用数据,经典艾瑞斯
iris = load_iris()
data = iris['data']
# ---------黄线第一步:接受模型参数----------
# 设置侧边栏 Tips:所有侧边栏的元素都必须在前面加上 sidebar,不然会在主页显示
st.sidebar.expander('') # expander必须接受一个 label参数,我这里留了一个空白
st.sidebar.subheader('在下方调节你的参数') # 副标题
# st.selectbox:创造一个下拉选择框的单选题,接收参数: (题目名称, 题目选项)
cluster_class = st.sidebar.selectbox('1.聚类数量:', list(range(2, 10))) # 选择聚类中心,并赋值
# st.radio:创造一个点击的单选题,接收参数与 selectbox一样
minmaxscaler = st.sidebar.radio('2.是否归一化:', ['是', '否']) # 选择是否标准化
if minmaxscaler == '是': # 进行判断
model_mms = MinMaxScaler().fit(data) # 调用归一标准化方法(也可以自己写一个函数处理)
data = model_mms.transform(data) # 对 data进行标准化
# ---------灰色砖头:调用 K-Means进行训练----------
model = KMeans(n_clusters=cluster_class).fit(data) # 这里的 cluster_class就是第 18行选择框接收到的值
data_done = np.c_[data, model.labels_] # 将结果和数据合并,model.lables:模型训练得到的标签
# ---------黄线第二步:传递训练结果并画图----------
fig, ax = plt.subplots() # 创建画布与子图
for i in set(model.labels_):
index = data_done[:, -1] == i # 每一个类对应的索引
x = data_done[index, 0] # 第一个特征:花瓣长度 Tips:iris有四个特征,自己选两个
y = data_done[index, 1] # 第二个特征:花瓣宽度
ax.scatter(x, y) # 做出散点图
st.pyplot(fig) # 画出来!
3.2完整版(黄线+红线)
完整版就是在省流版基础上加了许多可以调整画图参数的组件,以及页面装饰,但是也存在着一些问题,我会在结尾给出。
相较于省流版,完整版页面加入了以下组件:
| 组件 | 省流版 | 完整版 |
| “聚类数量” 按钮 | √ | √ |
| “是否归一化” 按钮 | √ | √ |
| “展示特征” 按钮 | √ | |
| “第几类的颜色” 按钮 | √ | |
| “第几类的形状” 按钮 | √ | |
| 图标元素 | √ | |
| 页面装饰 | √ |
这就是超级会员与普通会员哒!
接下来按照顺序一个一个进行代码介绍
1.“展示特征” 按钮
省流版的展示特征必须要在后台代码块中修改参数,而在iris数据集中,特征有4个:花瓣长、花瓣宽、花萼长、花萼宽。因此在展示的时候如果需要修改特征,就得通过新的选择框进行赋值,展示。代码如下:
figure = ['花瓣长度', '花瓣宽度','花萼长度','花萼宽度']
figure1 = st.sidebar.selectbox('3.选择第一类展示特征:', ['花瓣长度', '花瓣宽度','花萼长度','花萼宽度'])
figure2 = st.sidebar.selectbox('4.选择第二类展示特征:', ['花瓣长度', '花瓣宽度','花萼长度','花萼宽度'])figure1和figure2既是我们选择后进行赋值的变量,但是你的电脑可看不懂 ‘花瓣长度’ 是什么意思,因此需要建立一个和选择框一样的列表(figure)来进行索引, 因此画图部分的参数也需要作对应修改:
原代码
#for i in set(model.labels_):
# index = data_done[:, -1] == i # 每一个类对应的索引
# x = data_done[index, 0] # 第一个特征:花瓣长度 Tips:iris有四个特征,自己选两个
# y = data_done[index, 1] # 第二个特征:花瓣宽度
# ax.scatter(x, y) # 做出散点图
修改后的代码
for i in set(model.labels_):
index = data_done[:, -1] == i
x = data_done[index, figure.index(figure1)]
# e.g.第 0类特征是花瓣长度,通过页面选择使 figure1赋值为'花瓣长度'
# 然后通过列表(figure)的索引得到'花瓣长度'是第 0类特征,这样就达到了和原代码一样的效果
y = data_done[index, figure.index(figure2)] # 与 figure1同理
ax.scatter(x, y)
st.pyplot(fig)
2.“第几类颜色” 的按钮、 “第几类形状” 的按钮
这个按钮设置,首先要确定的是“总共有几类”,而分成几类是由前面通过选择框赋值给变量cluster_class确定的。因此只需要加一个for循环,就可以实现按钮数量跟随聚类数量一起变化啦:
for i in range(1, cluster_class +1): # 第1类 - 第k类 的按钮
col1, col2 = st.sidebar.columns(2) # st.columns(n):将一行分成n列
with col1: # 这里放第一列的东西
st.selectbox(f'第{i}类颜色', ['黑色', '银色','亮红色','棕色','橙色','金黄色','黄色','天蓝色','紫色']))
with col2: #第二列的东西
st.selectbox(f'第{i}类形状', ['圆形', '朝下三角', '朝上三角形', '正方形', '五边形', '星型', '六角形', '+号', 'x号', '小型菱形']))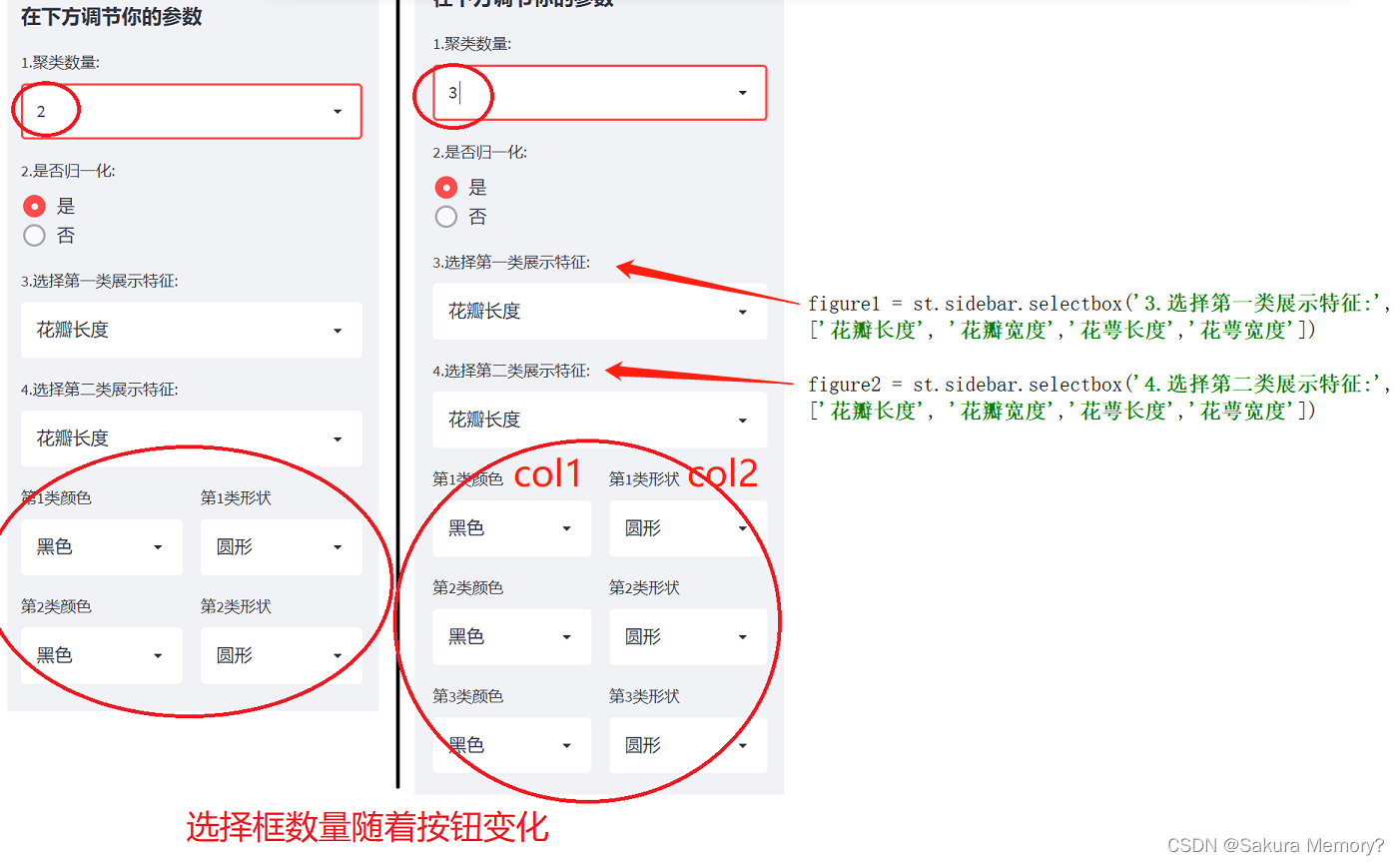
可以看到页面部分已经没有问题了,接下来是赋值部分,由于聚类的数量会变化,而创建的变量无法做到跟随数量变化,因此这里我采用了DataFrame来记录变量。由于Streamlit的页面每进行一次操作就会刷新一次,因此每次DataFrame的内容都会被重新清空赋值,不需要担心数据重复的情况。修改后的代码如下:
choice = pd.DataFrame([]) # 先创建一个空的DataFrame
for i in range(1, cluster_class +1):
col1, col2 = st.sidebar.columns(2) # 分成两列
with col1:
# 给DataFrame的第i行,color列新增一条记录
choice.loc[i, 'color'] = trans(st.selectbox(f'第{i}类颜色',
['黑色', '银色','亮红色','棕色','橙色','金黄色','黄色','天蓝色','紫色']))
# 给DataFrame的第i行,shape列新增一条记录
with col2:
choice.loc[i, 'shape'] = trans(st.selectbox(f'第{i}类形状',
['圆形', '朝下三角', '朝上三角形', '正方形', '五边形', '星型', '六角形', '+号', 'x号', '小型菱形']))
有朋友可能注意到trans,这是一个自定义函数,功能和上面的
figure.index(figure1)类似,就是根据赋值返回电脑可识别的字符,
trans的内容在末尾完整版代码已给出。这样就实现了不同类的赋值的记录,然后把他放到matplotlib里面:
for i in set(model.labels_):
index = data_done[:, -1] == i
# 新增的代码 👇👇
color = choice.loc[i+1, 'color']
shape = choice.loc[i+1, 'shape']
# 新增的代码 👆👆
x = data_done[index, figure.index(figure1)]
y = data_done[index, figure.index(figure2)]
ax.scatter(x, y, c=color, marker=shape) # 这里对应地加入颜色和形状的参数就可以了
st.pyplot(fig)3.图表元素
简简单单加几行代码给图表美化一下:
for i in set(model.labels_):
index = data_done[:, -1] == i
color = choice.loc[i+1, 'color']
shape = choice.loc[i+1, 'shape']
x = data_done[index, figure.index(figure1)] # 改选择特征
y = data_done[index, figure.index(figure2)]
ax.scatter(x, y, c=color, marker=shape)
# 下面是新增的部分👇👇👇
# 设置字体
font_dict = dict(fontsize=16, # 字体大小
color='maroon', # 颜色
family='SimHei',) # 类型
# 设置x, y轴标题
ax.set_xlabel(figure1, fontdict=font_dict)
ax.set_ylabel(figure2, fontdict=font_dict)
# 设置图表标题
ax.set_title('散点图', fontdict=dict(fontsize=16, color='black', family='SimHei',))
# 设置图例
ax.legend(set(model.labels_))
# 取消坐标显示
ax.set_xticks([])
ax.set_yticks([])
st.pyplot(fig)4.页面装饰
streamlit的st.markdown()提供了非常强大的功能,可以直接在里面写html或css!!(但是我不懂这俩语言,雾),因此如果有学过网页的小伙伴,可以自行修改页面元素。
我在网上抄了一些能用的样式,可以参考一下:
# 背景图片的网址
img_url = 'https://img.zcool.cn/community/0156cb59439764a8012193a324fdaa.gif'
# 修改背景样式
st.markdown('''<style>.css-fg4pbf{background-image:url(''' + img_url + ''');
background-size:100% 100%;background-attachment:fixed;}</style>
''', unsafe_allow_html=True)
# 侧边栏样式
st.markdown('''<style>#root > div:nth-child(1) > div > div > div > div >
section.css-1lcbmhc.e1fqkh3o3 > div.css-1adrfps.e1fqkh3o2
{background:rgba(255,255,255,0.5)}</style>''', unsafe_allow_html=True)
# 底边样式
st.markdown('''<style>#root > div:nth-child(1) > div > div > div > div >
section.main.css-1v3fvcr.egzxvld3 > div > div > div
{background-size:100% 100% ;background:rgba(207,207,207,0.9);
color:red; border-radius:5px;} </style>''', unsafe_allow_html=True)
请注意,一定要在st.markdown最后加 unsafe_allow_html=True ,不然代码会直接在页面上显示 对比一下修改前后:

虽然但是还是好看一点点吧!
成功!
完整版完整代码如下:
import numpy as np
import pandas as pd
import streamlit as st
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
img_url = 'https://img.zcool.cn/community/0156cb59439764a8012193a324fdaa.gif' # 背景图片的网址
st.markdown('''<style>.css-fg4pbf{background-image:url(''' + img_url + ''');
background-size:100% 100%;background-attachment:fixed;}</style>
''', unsafe_allow_html=True) # 修改背景样式
iris = load_iris()
data = iris['data']
st.title('K-Means交互式组件'.center(33, '-'))
st.sidebar.expander('')
st.sidebar.subheader('在下方调节你的参数')
cluster_class = st.sidebar.selectbox('1.聚类数量:', list(range(2, 10)))
minmaxscaler = st.sidebar.radio('2.是否归一化:', ['是', '否'])
if minmaxscaler == '是':
model_mms = MinMaxScaler().fit(data)
data = model_mms.transform(data)
figure = ['花瓣长度', '花瓣宽度','花萼长度','花萼宽度']
figure1 = st.sidebar.selectbox('3.选择第一类展示特征:', ['花瓣长度', '花瓣宽度','花萼长度','花萼宽度'])
figure2 = st.sidebar.selectbox('4.选择第二类展示特征:', ['花瓣长度', '花瓣宽度','花萼长度','花萼宽度'])
def trans(select):
if select == '黑色':
return 'black'
elif select == '银色':
return 'silver'
elif select == '亮红色':
return 'lightcoral'
elif select == '棕色':
return 'brown'
elif select == '橙色':
return 'orange'
elif select == '金黄色':
return 'gold'
elif select == '黄色':
return 'yellow'
elif select == '绿色':
return 'lawngreen'
elif select == '天蓝色':
return 'cyan'
elif select == '紫色':
return 'purple'
elif select == '圆形':
return 'o'
elif select == '朝下三角':
return 'v'
elif select == '朝上三角形':
return '^'
elif select == '正方形':
return 's'
elif select == '五边形':
return 'p'
elif select == '星型':
return '*'
elif select == '六角形':
return 'h'
elif select == '+号':
return '+'
elif select == 'x号':
return 'x'
elif select == '小型菱形':
return 'd'
choice = pd.DataFrame([])
for i in range(1, cluster_class +1):
col1, col2 = st.sidebar.columns(2) # 分成两列
with col1: #第一列的东西
choice.loc[i, 'color'] = trans(st.selectbox(f'第{i}类颜色', ['黑色', '银色','亮红色','棕色','橙色','金黄色','黄色',
'天蓝色','紫色']))
with col2: #第二列的东西
choice.loc[i, 'shape'] = trans(st.selectbox(f'第{i}类形状', ['圆形', '朝下三角', '朝上三角形', '正方形', '五边形', '星型'
, '六角形', '+号', 'x号', '小型菱形']))
model = KMeans(n_clusters=cluster_class).fit(data)
data_done = np.c_[data, model.labels_]
# st.write(model.labels_)
# st.write(model.cluster_centers_)
fig, ax = plt.subplots()
for i in set(model.labels_):
index = data_done[:, -1] == i
color = choice.loc[i+1, 'color']
shape = choice.loc[i+1, 'shape']
x = data_done[index, figure.index(figure1)] # 改选择特征
y = data_done[index, figure.index(figure2)]
ax.scatter(x, y, c=color, marker=shape)
# plt.axis('off')
font_dict = dict(fontsize=16,
color='maroon',
family='SimHei',)
ax.set_xlabel(figure1, fontdict=font_dict)
ax.set_ylabel(figure2, fontdict=font_dict)
ax.set_title('散点图', fontdict=dict(fontsize=16, color='black', family='SimHei',))
ax.legend(set(model.labels_))
ax.set_xticks([])
ax.set_yticks([])
# ax.tick_params(bottom=False,top=False,left=False,right=False)
st.pyplot(fig)
st.markdown('''<style>#root > div:nth-child(1) > div > div > div > div >
section.css-1lcbmhc.e1fqkh3o3 > div.css-1adrfps.e1fqkh3o2
{background:rgba(255,255,255,0.5)}</style>''', unsafe_allow_html=True) # 侧边栏样式
st.markdown('''<style>#root > div:nth-child(1) > div > div > div > div >
section.main.css-1v3fvcr.egzxvld3 > div > div > div
{background-size:100% 100% ;background:rgba(207,207,207,0.9);
color:red; border-radius:5px;} </style>''', unsafe_allow_html=True) # 底边样式
四、缺点
目前已知的缺点就是每次打开网页,所有的选项都是默认的第一个,因此会出现全是小黑圆点的y=x线条hhhhh,需要自己一个一个去改;另外在修改的过程中,由于每选项一次,页面都会刷新一次,因此K-Means的聚类结果也会重新计算一次,比如label是1的花,可能刷新一次后label变成了2(还是同一个类,但是标签变了),这就导致图表中相同类点的款式会变来变去😶
如果有大佬提供解决方法就太棒啦!感激不尽!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)