NAFNet:图像去噪,去模糊新SOTA!荣获NTIRE 2022 超分辨率冠军方案!
导读:2022年4月,旷视研究院发表了一种基于图像恢复任务的全新网络结构,它在SIDD和GoPro数据集上进行训练和测试,该网络结构实现了在图像去噪任务和图像去模糊任务上的新SOTA。具体计算量与实验效果如下图所示:不仅如此,基于NAFNet,旷视还提出了一种针对超分辨率的NAFNet变体结构,该网络为NAFNet-SR。NAFNet-SR在NTIRE 2022 超分辨率...

导读:2022年4月,旷视研究院发表了一种基于图像恢复任务的全新网络结构,它在SIDD和GoPro数据集上进行训练和测试,该网络结构实现了在图像去噪任务和图像去模糊任务上的新SOTA。具体计算量与实验效果如下图所示:
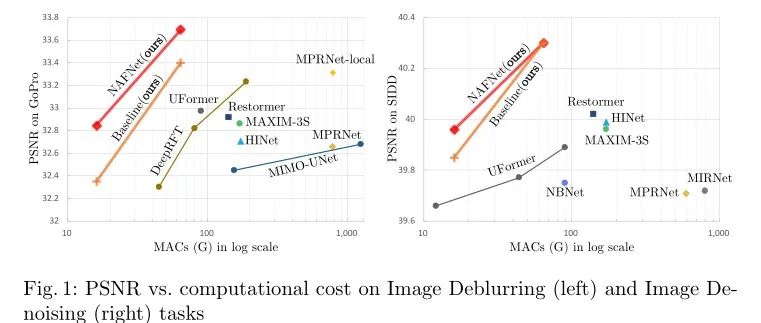
不仅如此,基于NAFNet,旷视还提出了一种针对超分辨率的NAFNet变体结构,该网络为NAFNet-SR。NAFNet-SR在NTIRE 2022 超分辨率比赛中荣获冠军方案。本文将从模型的组成、主要结构以及代码的训练和配置等方面进行详细介绍!
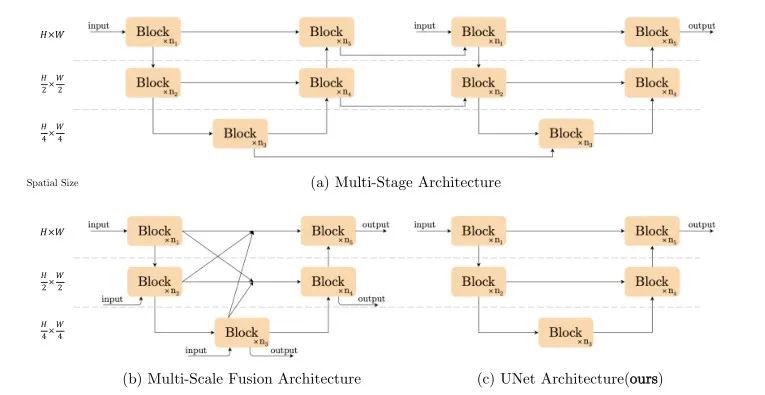
上图给出了三种主流的图像恢复主流网络架构设计方案,包含多阶段特征提取、多尺度融合架构以及经典的UNet架构。本文为了最大化减少模型每个模块间进行交互的复杂度,直接采用了含有Short Cut的UNet架构。NAFNet在网络架构上实现了最大精简原则!
代码复现
项目地址:https://github.com/murufeng/FUIR
核心模块图与代码
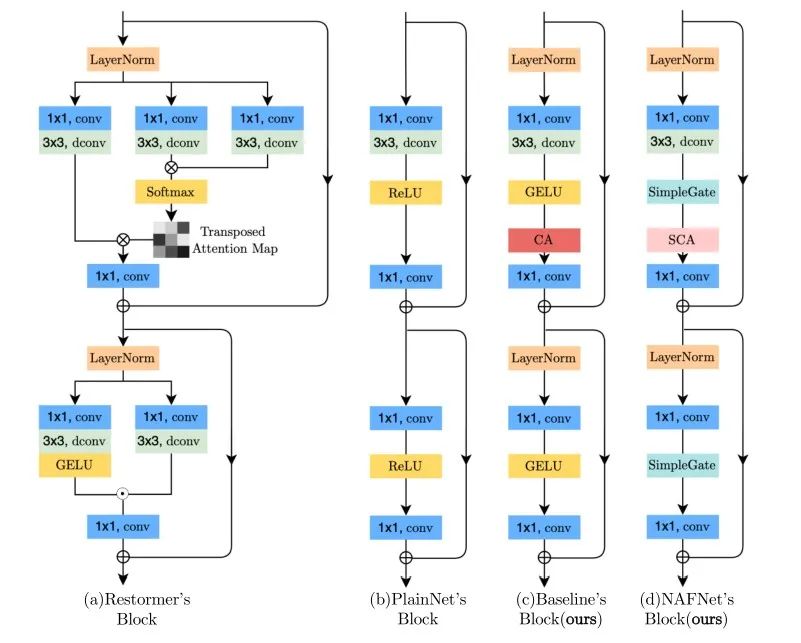
基于Restormer的模块示意图,NAFNet设计另一种最简洁的模块方案,具体体现在:
借鉴Trasnformer中使用LN可以使得训练更平滑。NAFNet同样引入LN操作,在图像去噪和去模糊数据集上带来了显著的性能增益。
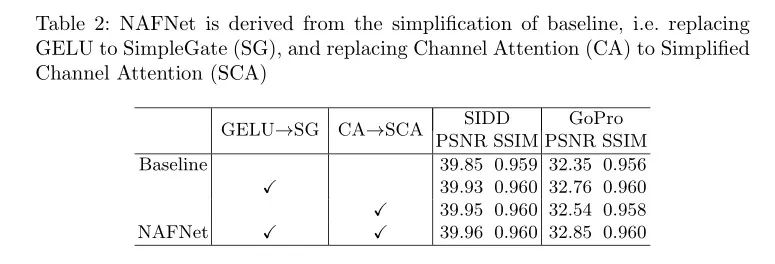
在Baseline方案中使用GELU和CA联合替换ReLU,GELU可以保持降噪性能相当且大幅提升去模糊性能。
由于通道注意力的有效性已在多个图像复原任务中得到验证。本文提出了两种新的注意力模块组成即CA和SCA模块,具体如下所示:

其中SCA(见上图b)直接利用1x1卷积操作来实现通道间的信息交换。而SimpleGate(见上图c)则直接将特征沿通道维度分成两部分并相乘。采用所提SimpleGate替换第二个模块中的GELU进行,实现了显著的性能提升。

NAFBlock构成代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from basicsr.models.archs.arch_util import LayerNorm2d
from basicsr.models.archs.local_arch import Local_Base
class SimpleGate(nn.Module):
def forward(self, x):
x1, x2 = x.chunk(2, dim=1)
return x1 * x2
class NAFBlock(nn.Module):
def __init__(self, c, DW_Expand=2, FFN_Expand=2, drop_out_rate=0.):
super().__init__()
dw_channel = c * DW_Expand
self.conv1 = nn.Conv2d(in_channels=c, out_channels=dw_channel, kernel_size=1, padding=0, stride=1, groups=1, bias=True)
self.conv2 = nn.Conv2d(in_channels=dw_channel, out_channels=dw_channel, kernel_size=3, padding=1, stride=1, groups=dw_channel,
bias=True)
self.conv3 = nn.Conv2d(in_channels=dw_channel // 2, out_channels=c, kernel_size=1, padding=0, stride=1, groups=1, bias=True)
# Simplified Channel Attention
self.sca = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels=dw_channel // 2, out_channels=dw_channel // 2, kernel_size=1, padding=0, stride=1,
groups=1, bias=True),
)
# SimpleGate
self.sg = SimpleGate()
ffn_channel = FFN_Expand * c
self.conv4 = nn.Conv2d(in_channels=c, out_channels=ffn_channel, kernel_size=1, padding=0, stride=1, groups=1, bias=True)
self.conv5 = nn.Conv2d(in_channels=ffn_channel // 2, out_channels=c, kernel_size=1, padding=0, stride=1, groups=1, bias=True)
self.norm1 = LayerNorm2d(c)
self.norm2 = LayerNorm2d(c)
self.dropout1 = nn.Dropout(drop_out_rate) if drop_out_rate > 0. else nn.Identity()
self.dropout2 = nn.Dropout(drop_out_rate) if drop_out_rate > 0. else nn.Identity()
self.beta = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)
self.gamma = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)
def forward(self, inp):
x = inp
x = self.norm1(x)
x = self.conv1(x)
x = self.conv2(x)
x = self.sg(x)
x = x * self.sca(x)
x = self.conv3(x)
x = self.dropout1(x)
y = inp + x * self.beta
x = self.conv4(self.norm2(y))
x = self.sg(x)
x = self.conv5(x)
x = self.dropout2(x)
return y + x * self.gamma模型训练与实验结果
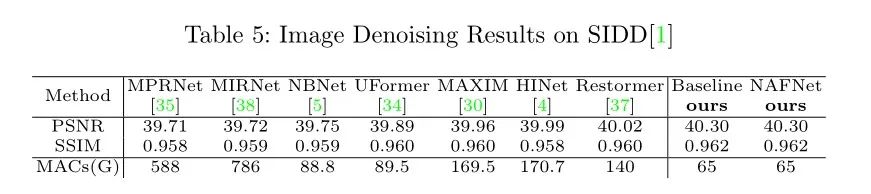
图像去噪任务(SIDD数据集):
训练命令如下:
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 basicsr/train.py -opt options/train/SIDD/NAFNet-width32.yml --launcher pytorch实验结果图:

图像去模糊任务(GoPRO数据集):
模型训练命令如下:
python -m torch.distributed.launch --nproc_per_node=8 --master_port=4321 basicsr/train.py -opt options/train/GoPro/NAFNet-width32.yml --launcher pytorch实验结果图:


更多项目细节见:https://github.com/murufeng/FUIR
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)