图解Pandas的排序sort_values函数
图解Pandas的排序sort_values函数大家好,我是Peter~在上一篇pandas的文章中已经介绍排名机制中rank函数的使用。其实在实现排名的过程,已经顺带实现了排序的功能;但是pandas中还有一个重要的方法来解决排序问题:sort_values。Pandas连载Pandas文章已经形成连载,前10篇文章分别是:参数解释DataFrame.sort_values(by,axis=0,
图解Pandas的排序sort_values函数
大家好,我是Peter~
在上一篇pandas的文章中已经介绍排名机制中rank函数的使用。其实在实现排名的过程,已经顺带实现了排序的功能;但是pandas中还有一个重要的方法来解决排序问题:sort_values。

Pandas连载
Pandas文章已经形成连载,前10篇文章分别是:

参数解释
DataFrame.sort_values(by,
axis=0,
ascending=True,
inplace=False,
kind='quicksort',
na_position='last', # last,first;默认是last
ignore_index=False,
key=None)
参数的具体解释为:
- by:表示根据什么字段或者索引进行排序,可以是一个或多个
- axis:排序是在横轴还是纵轴,默认是纵轴axis=0
- ascending:排序结果是升序还是降序,默认是升序
- inplace:表示排序的结果是直接在原数据上的就地修改还是生成新的DatFrame
- kind:表示使用排序的算法,快排quicksort,,归并mergesort, 堆排序heapsort,稳定排序stable ,默认是 :快排quicksort
- na_position:缺失值的位置处理,默认是最后,另一个选择是首位
- ignore_index:新生成的数据帧的索引是否重排,默认False(采用原数据的索引)
- key:排序之前使用的函数


参数案例说明
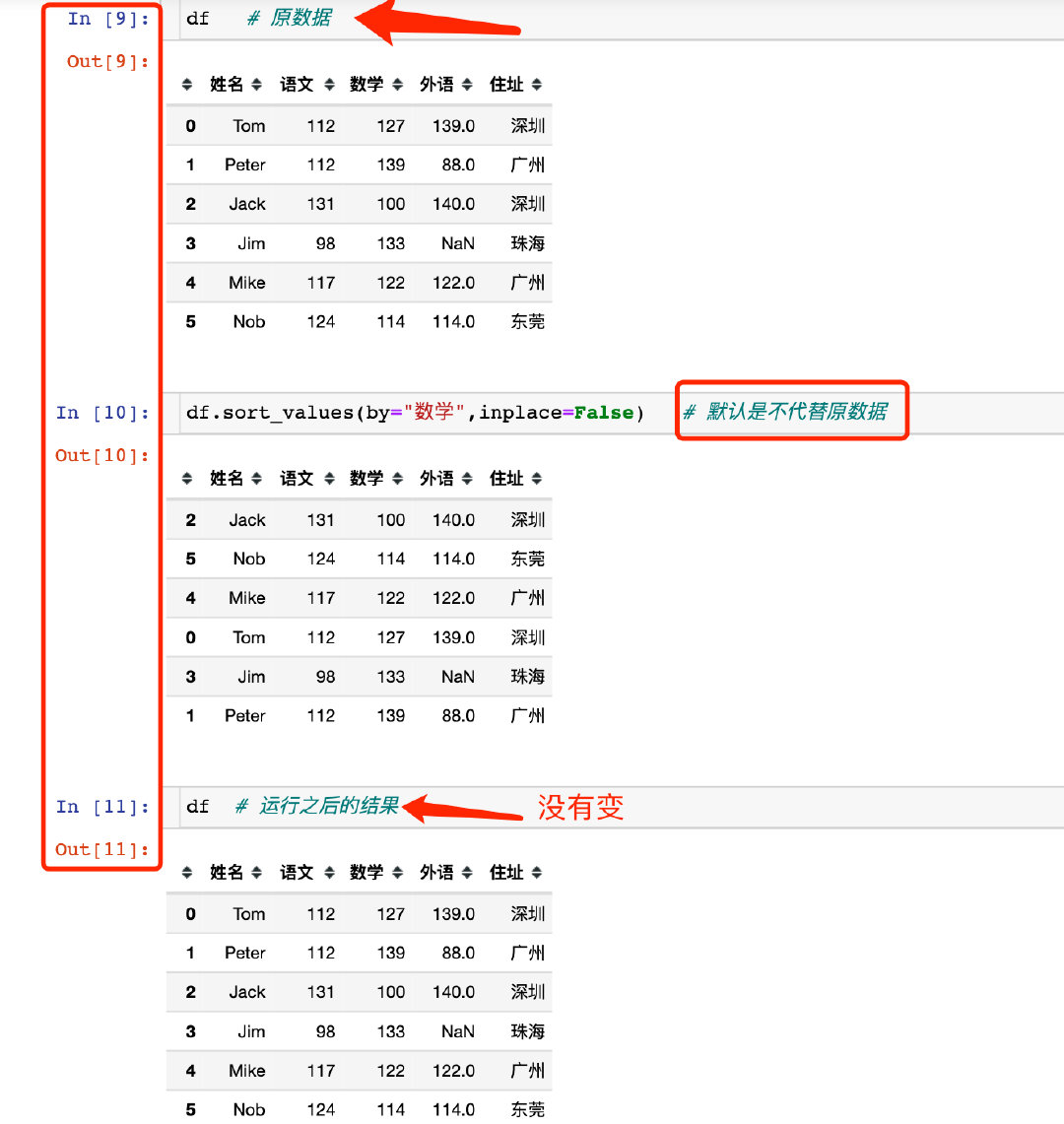
下面会通过不同的案例来说明各个参数的使用方法和含义,模拟的第一份数据如下,里面有一个缺失值:
df = pd.DataFrame({
'姓名': ['Tom', 'Peter', 'Jack', 'Jim', 'Mike', 'Nob'],
'语文': [112, 112, 131, 98, 117, 124],
'数学': [127, 139, 100, 133, 122, 114],
'外语': [139, 88, 140, np.nan, 122, 114], # 存在缺失值
'住址': ['深圳', '广州', '深圳', '珠海', '广州', '东莞']}
)
df

by
by参数是必需的,也是最简单的参数:我们必须指定按照哪个列属性或者行索引来排序,可以是一个或多个,by关键字可以省略。
df.sort_values(by="数学")
df.sort_values(by=["语文","数学"]) # 多个字段的排序
axis
axis参数表示的是在哪个方向上排序,axis=0纵轴,axis=1横轴,看一份新的模拟数据:
data = pd.DataFrame({'a':[7,4,6,3],
'b':[4,3,2,1],
'c':[8,9,5,1]})
data
# 结果
a b c
0 7 4 8
1 4 3 9
2 6 2 5
3 3 1 1
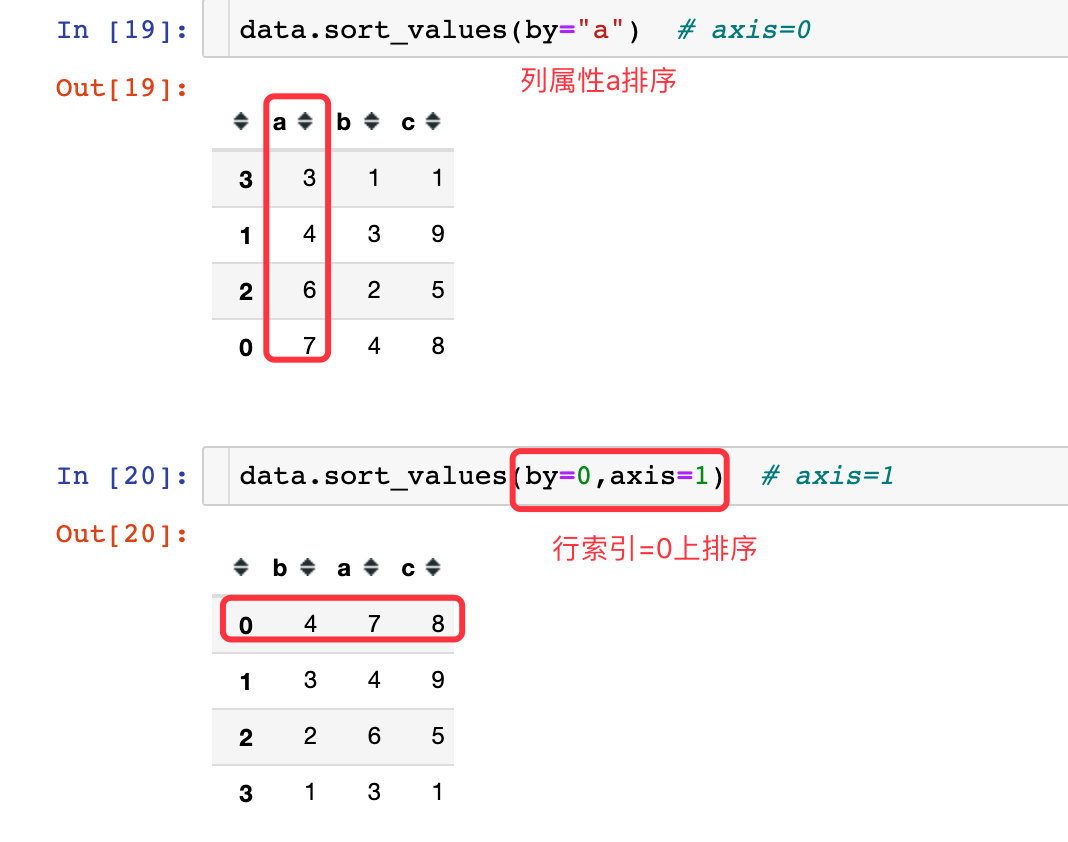
inplace
当inplace=True的时候,原数据在排序之后会直接修改:
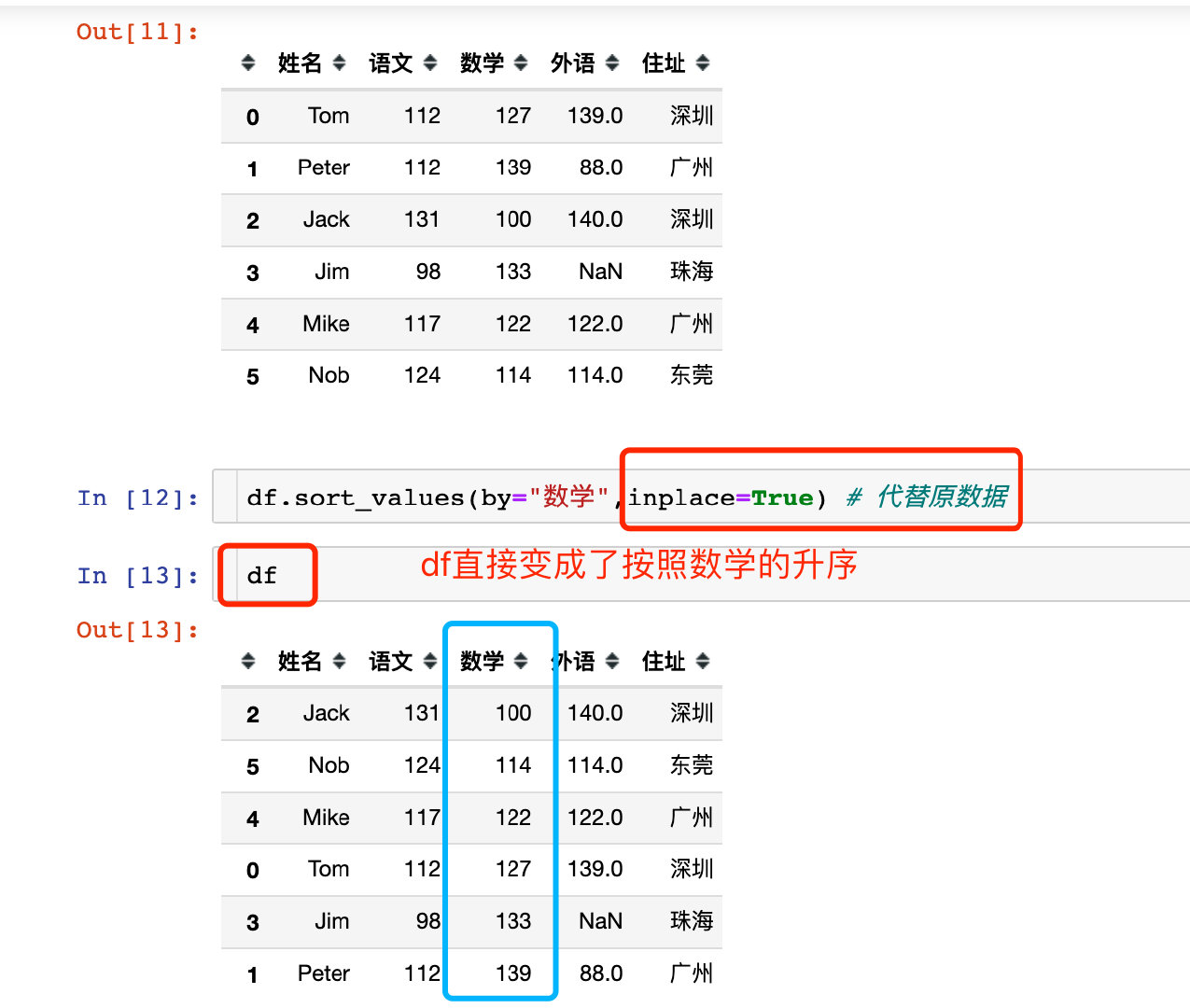
ascending
可以是一个或者多个字段的排序,通过列表的形式指定:
df.sort_values(by="数学",ascending=False) # 一个字段排序
df.sort_values(by=["语文","数学"], # 多个字段的不同排序方式
ascending=[True,False]
)

na_position
缺失值的位置处理:默认是最后,也可以放到最前面:
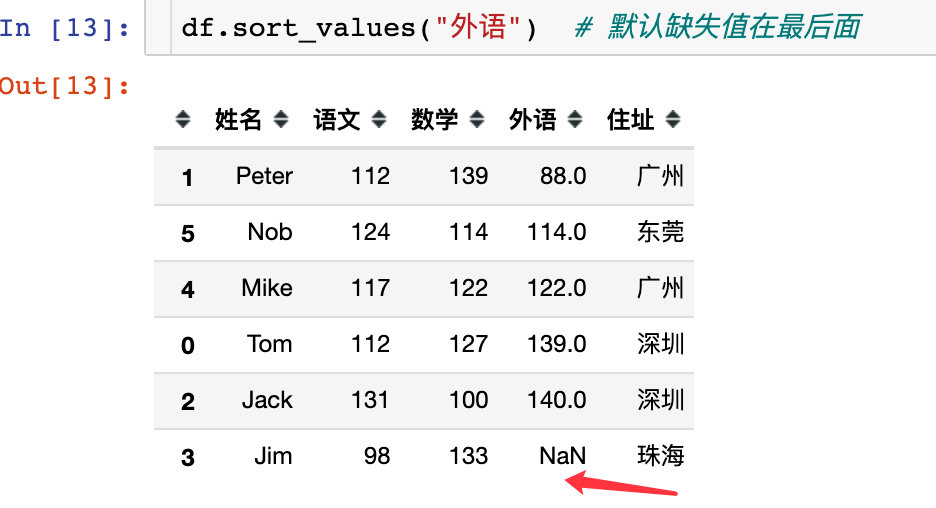
上面默认是在末尾。也可以放在首位:

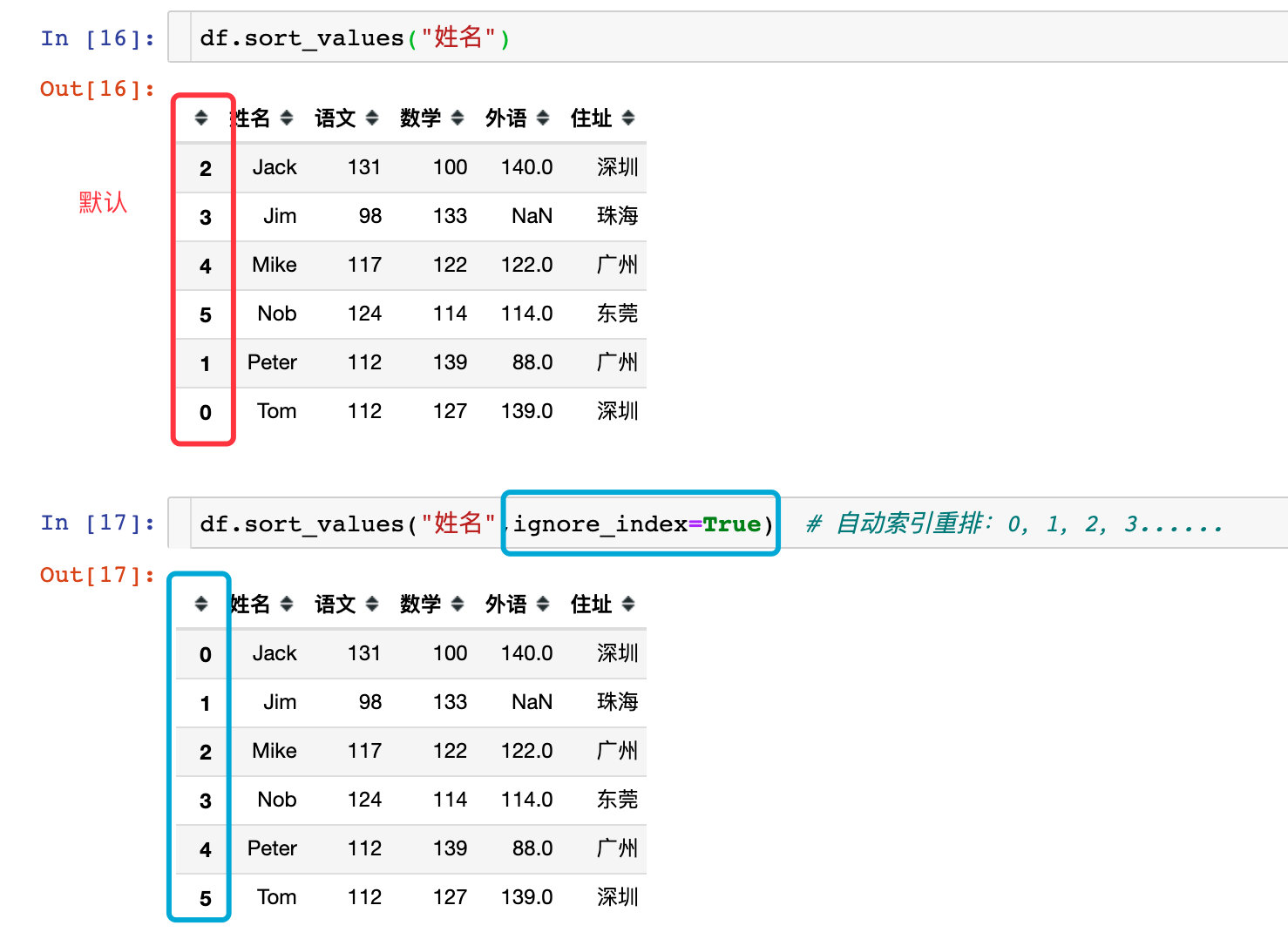
ignore_index
表示新生成的数据中的索引是采用原数据的索引还是新生成的0,1,2,3……
key
表示在排序之前使用的函数:
Apply the key function to the values before sorting. This is similar to the key argument in the builtin
sorted()function, with the notable difference that this key function should be vectorized. It should expect aSeriesand return a Series with the same shape as the input. It will be applied to each column in by independently.
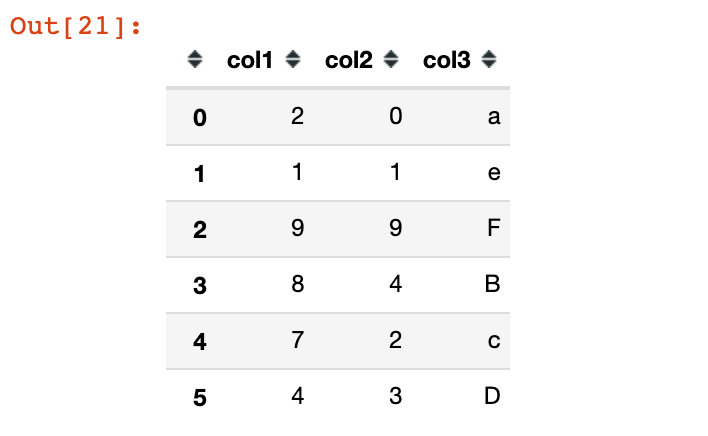
为了解释key参数,我们再模拟一份数据:
data1 = pd.DataFrame({
'col1': [2, 1, 9, 8, 7, 4],
'col2': [0, 1, 9, 4, 2, 3],
'col3': ['a', 'e', 'F', 'B', 'c', 'D']
})
data1

上面的例子很好地显示了参数key的使用,解释下上面两行代码的运行结果,我们对col3字段排序:
- 默认情况下,字母是按照它们对应的ASCII码进行比较的(A-65,a-97);所以升序的结果就是:BDFace
- 加上了key参数,我们写了一个匿名函数lambda,作用是将col3中的字符串全部变成小写字母,这样升序自然是aBcDeF,因为此时的BDF变成了bdf
总结
排序sort_values函数在平时使用的频率是非常高的,经常需要对销售数据做TopN分析。它能够很快地运用于电商领域,包含TopN的销售额、用户、商品、销售员业绩等;不同学科的排名,学生的成绩等诸多场景,希望对读者有所帮助。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 18
18 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)