Pandas中 的 rank() 函数 和 groupby 的 rank() 函数用法
一、pandas中的rank()函数首先随机初始化一组数,然后data = pd.Series([1,2,3,4,5])print(data)data = data.rank()print(data)这里的rank()函数打印出来虽然和原数组没区别,但是这里rank表示的是次序,所以这里的1.0,2.0表示的是第一名和第二名如果有重复值的话data = pd.Series([1,1,2,2,3,3
一、pandas中的rank()函数
首先随机初始化一组数,然后
data = pd.Series([1,2,3,4,5])
print(data)
data = data.rank()
print(data)
这里的rank()函数打印出来虽然和原数组没区别,但是这里rank表示的是次序,所以这里的1.0,2.0表示的是第一名和第二名
如果有重复值的话
data = pd.Series([1,1,2,2,3,3,4,4,5])
print(data)
data = data.rank()
print(data)
这里的的数组首先是有序的,所以数组里的第一个1的名次是第一名,表示1.0,第二个1的名次是第二名,表示2.0,重复值的话,默认求平均,所以它俩的名次平均值就是(1.0+2.0)/2 = 1.5,同理,第一个2是第三名,表示3.0,第二个2是第四名,表示4.0,平均值是(3.0+4.0)/2 = 3.5.
rank函数提供了method的参数,通过设置method参数,可以控制自己想要的排名方式。
如果说这个rank函数要解决的是考试排名的问题,现在出现了有两个同学并列第一的情况:method='average' (默认设置):那么这两个人就占据了前两名,分不出谁第 1,谁第 2,就把两人的名次算个平均数,都算 1.5 名,这样下一个人就是第3名。
method='max':两人并列第 2 名,下一个人是第 3 名。
method='min':两人并列第 1 名,下一个人是第 3 名。
method='dense':两人并列第 1 名,但下一个人是第 2 名。
method='first':那么试卷先被改出来的人是第 1 名,试卷后被改出来的是第 2 名。(这个例子并不严谨,实际会按照本来序列的显示顺序先后来排名)
二、groupby中的rank()函数
groupby是聚合函数,对于某一列或多列进行聚合,可以看Pandas教程 | 超好用的Groupby用法详解 - 知乎
进行学习
假设随机初始化几列数
import pandas as pd
list1 = [1, 3, 1,0,7,4,0]
list2 = [3, 3, 2,0,4,4,5]
list3 = [3, 3, 3,3,4,4,6]
df1 = pd.DataFrame({'col1':list1,'col2':list2,'col3':list3})
print(df1)
df1 = df1.groupby(['col3']).rank(ascending=False)
print(df1)我们对col3进行聚合,然后再排名,其中ascending=False表示降序,打印一下结果

首先看col1这一列。col1和col3可以分为三块,分别是
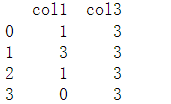
![]()
![]()
由于是降序,那么排完序之后就变成了

![]()
![]()
注意:这里的排序是每一块内单独排序,所以rank()函数的排名也是每一块的单独排名。
对于第一个块中,3现在是第一名,表示为1.0,第一个1是第二名,表示为2.0,第二个1是第三名,表示为3.0,method默认为平均,所以它俩的名次是(2.0+3.0)/2 = 2.5,0是第四名,表示为4.0。所以结果为

它这个结果是将排序后的顺序放在一开始分块后的结果上,意思就是
顺序是放在 这个结果上面,所以结果是
对于第二个块中,7是第一名,表示为1.0,4是第二名,表示为2.0,所以结果为

其他都同理。
其中groupby的rank函数也有method参数,用法与rank函数相同,这里不做介绍。
参考:
Pandas | rank()函数_Code_Porter的专栏-CSDN博客_pandas rank函数
Pandas —— rank( )函数进行排名_starter_____的博客-CSDN博客_dataframe rank

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)