ibox pc端数据爬取逆向总结
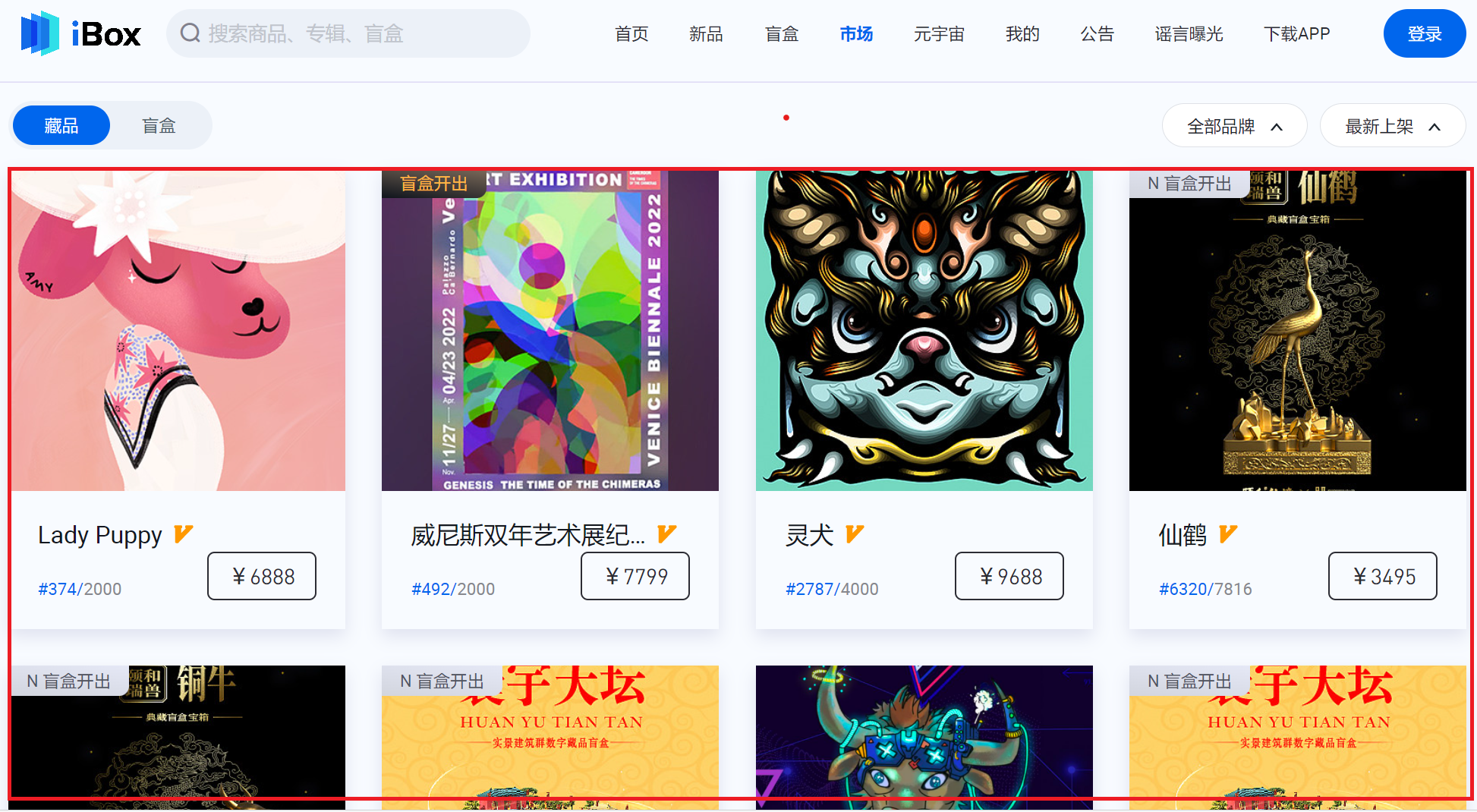
本文总结了针对ibox平台的PC端数据爬取的思路及方式。虽然最终并没有达到目标,但是通过对这么严格的网站的爬取,也有不少收获,特此做篇总结,在此抛砖引玉。爬取的目标是‘市场’这个tab页下每张图片的具体信息(图1),刷新几次页面,在devtools页面能看许多Ajax请求(图2),针对每个请求的request、response数据观察,初步断定目标请求为,因为该请求的出入参均为乱码,极有可能为关键
本文总结了针对ibox平台的PC端数据爬取的思路及方式。虽然最终并没有达到目标,但是通过对这么严格的网站的爬取,也有不少收获,特此做篇总结,在此抛砖引玉。
- 1、关键请求分析
- 2、逻辑梳理
- 3、python实现
- 4、遗留问题
1、关键请求分析
爬取的目标是‘市场’这个tab页下每张图片的具体信息,如下:



刷新几次页面,在devtools页面能看许多Ajax请求,针对每个请求的request、response数据观察,初步断定目标请求为https://web-001.cloud.servicewechat.com/wxa-qbase/container_service?token=58_3Z1Ivgc9xjXXug1DfvFa_xciBKRW8MM6i5KXI_UPIfr92biBmSjg-aFP16Lr1vLuO9ZtP633FMBoYrTr,因为该请求的出入参均为乱码,极有可能为关键数据,否则不至于这么隐蔽。至于究竟是什么宝藏,接着分析。
2、逻辑梳理
针对第一步的请求,观察该对应的调用链,即网络面板下的启动器,可以看到完整的调用链信息,打开最顶部的t.request,定位到该请求发起的那一刻所调用的方法,点击去查看源代码,左下角格式化后代码如下:


在这个方法处发起了request请求,但并没有相关的入参信息,说明参数的封装应该在之前,回到启动器的调用链中,找到调用栈中当前函数的上一个函数,再打开,如下:

在这里可以看到request的入参构造逻辑,url、header、data的核心逻辑就在这里,继续!
2.1 url的构造
URL对应的变量为M,其实就是这个Ajax请求对应的URL。
关键在于token参数的获取,有两种思路。一种是当前Ajax请求中构造token,另一种是之前的Ajax请求先获取token,再应用到之后的Ajax请求中。我们在当前的逻辑中可以看到url由变量i.url赋值,并且token也位于i.token之中,而i是函数的入参,整个逻辑梳理下来并没有发现token的生成逻辑,目前来看答案倾向于第2种思路。
顺着这个思路再排查下之前的Ajax请求,有多个https://web-001.cloud.servicewechat.com/wxa-qbase/jsoperatewxdata请求,为post方式,入参不同对应的response也不同,并且response中的data也都是密文,至于是什么数据以及什么加密方式我们暂时无法获知,但是能够发现排在最前面的/jsoperatewxdata请求中,response的data里有token,并且之后的Ajax请求所携带的token均为该值,进一步验证了第2种思路是正确的。

所以我们可以通过先发起这个请求来获取token,再构造目标请求。
对于这个前置的请求我们暂且不做深入分析,先把目标请求逻辑梳理清楚再来盘它。
2.2 header的构造
header对应的变量为E,顺藤摸瓜会发现E相关的逻辑只有2处,一处为初始化,一口气构造了7个属性,其中有2个属性值为变量,倒也不复杂,就是时间戳和超时时间,关于时间戳这个属性值其实暗含着逻辑,并不是随意生成的,这个后面再细说;另外一处构造了X-WX-REQUEST-CONTENT-ENCODING属性,即入参编码格式,至于是PB还是JSON,通过断点验证发现该属性值为后者JSON。

到此,header逻辑也梳理清楚了。
2.3 data的构造
data对应的变量为L,它的逻辑相对复杂些,如下图:

L变量依赖的变量及相关操作如下:
抽丝剥茧一层层来看:
①data对应字节数组L;
②L对应的是变量N进行AES加密后的结果,AES加密用到的秘钥和VI向量均为变量x
③x对应的是i.key,我们在获取url的token时也是从变量i中获取i.token,那么i.key也可能是同样的逻辑,回到/jsoperatewxdata请求中,发现i.key的值果然来源于这里,所以我们可以得出这样的结论:
/jsoperatewxdata请求目的在于获取 token 以及AES加密的秘钥key
④N对应的是变量b,即对b进行snappy压缩,减少数据传输的大小
⑤b对应的是多个变量,以字典结构构建,如下
b = new Uint8Array(s.stringToArrayBuffer(JSON.stringify({
method: c.method || "GET",
header: O,
body: v,
call_id: g
})))
变量b竟然也是一个request格式,通过断点调试会发现,b其实是真实的后台http请求。初步推断后台架构应该如下:
A节点的用户Ajax请求,也即我们在devtools面板看到的请求;请求发出后先到B节点的网关,用于鉴权和风控;B节点过滤掉恶意请求,正常请求转到C节点,获取数据。而变量b对应的就是这个到达C节点的请求信息。
⑥O对应的变量是y,y对应的变量c,c为函数入参,y其实内容打断点后就可以获取到,如下
Accept-Language: "zh-CN"
HOST: "api-h5-tgw.ibox.art"
IB-DEVICE-ID: "设备ID"
IB-PLATFORM-TYPE: "web"
IB-TRANS-ID: "事务ID"
User-Agent: ""
X-WX-CALL-ID: "0.0120842696790322_1657627670840" #随机数_时间戳
X-WX-CONTAINER-PATH: "/nft-mall-web/v1.2/nft/product/getResellList?type=0&origin=0&sort=0&page=1&pageSize=50" #真实的后台请求
X-WX-ENV: "ibox-3gldlr1u1a8322d4"
X-WX-EXCLUDE-CREDENTIALS: "unionid, cloudbase-access-token, openid"
X-WX-GATEWAY-ID: "gw-1-1g2n1gd143d56b56"
X-WX-REGION: "ap-beijing"
X-WX-RESOURCE-APPID: "你的APPID"
content-type: "application/json"
我们只需要把该替换的替换掉,就可以mock出1个真实的header。
注意:O为字典形式,并且key为小写,y为字符串形式。
⑦v对应的变量是"undefined",因为该请求为GET请求,所有参数都拼接在url中。v的值我们同样打断点就可以获取到。
⑧g由当前时间戳和随机数拼接而成
如上,我们已经把整体逻辑梳理完毕,接下来开始用Python实现
3、Python实现
以下逻辑实现了上面提到的2个Ajax请求,第1个Ajax请求用于获取token/key/timestamp,作为目标请求的入参。
至于为什么要用到
timestamp变量,这是因为服务端在进行AES解密的时候需要知道用哪个key。每个客户端的key并不相同,个人推断服务端做了 时间戳 和 key的关联,所以在用户把时间戳提交上去的时候,服务端就根据时间戳拿到了对应的key,然后进行解密。
所以第二次Ajax请求的timestamp不是随意赋值的。
import base64
import requests
import json
import time
from Crypto.Cipher import AES
import httpx
import snappy
from ibox.js.PyExecJsDemo import get_bytes
key_url = 'https://web-001.cloud.servicewechat.com/wxa-qbase/jsoperatewxdata'
def get_headers(timestamp):
headers_2 = {
'Content-Type': "application/octet-stream",
'X-WX-COMPRESSION': "snappy",
# AES秘钥key对应的时间戳
'X-WX-ENCRYPTION-TIMESTAMP': str(timestamp),
'X-WX-ENCRYPTION-VERSION': '2',
'X-WX-LIB-BUILD-TS': '1655460325335',
'X-WX-REQUEST-CONTENT-ENCODING': "JSON",
'X-WX-RESPONSE-CONTENT-ACCEPT-ENCODING': "PB, JSON",
'X-WX-USER-TIMEOUT': '30000'
}
return headers_2
def parse_compress_data():
headers_list = []
headers = {
'Accept-Language': "zh-CN",
'HOST': "api-h5-tgw.ibox.art",
'IB-DEVICE-ID': "9ad7fdb73e434a6daf339a1e6298a0ca",
'IB-PLATFORM-TYPE': "web",
'IB-TRANS-ID': "42e46cf8a01d4e2587d2c96cd31e3f3d",
'User-Agent': "",
'X-WX-CALL-ID': "0.9000717952766866_1657361554363",
'X-WX-CONTAINER-PATH': "/nft-mall-web/v1.2/nft/product/getResellList?type=0&origin=0&sort=0&page=1&pageSize=50",
'X-WX-ENV': "ibox-3gldlr1u1a8322d4",
'X-WX-EXCLUDE-CREDENTIALS': "unionid, cloudbase-access-token, openid",
'X-WX-GATEWAY-ID': "gw-1-1g2n1gd143d56b56",
'X-WX-REGION': "ap-beijing",
'X-WX-RESOURCE-APPID': "wxe77e91c2fdb64e85",
'content-type': "application/json",
}
call_id = "0.9000717952766867_" + str(int(time.time() * 1000))
for k, v in headers.items():
k = k.lower()
if 'x-wx-call-id' == k:
v = call_id
headers_list.append({
'key': k,
'value': v
# k: v
})
header_body = {
"method": "GET",
"header": headers_list,
"body": "undefined",
"call_id": call_id
}
header_body_arr = bytes(json.dumps(header_body).encode('utf-8'))
header_body_c = snappy.compress(header_body_arr)
return header_body_c
# 需要补位,str不是16的倍数那就补足为16的倍数
def add_to_16_byte(value):
while len(value) % 16 != 0:
value += b'\0'
return value
def aes_encrypt(key_bytes, text):
# 增加vi向量
aes = AES.new(key_bytes, AES.MODE_CBC, key_bytes)
bytes = aes.encrypt(add_to_16_byte(text))
return bytes
def get_key_token():
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '626',
'Content-Type': 'application/json',
'Host': 'web-001.cloud.servicewechat.com',
'Origin': 'https://www.ibox.art',
'Pragma': 'no-cache',
'Referer': 'https://www.ibox.art/',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': 'Windows',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
data = {
"appid": "wxe77e91c2fdb64e85",
"data": {
"qbase_api_name": "tcbapi_get_service_info",
"qbase_req": "{\"client_random\":\"0.2826657173143865_1657318155306\",\"system\":\"\"}",
"qbase_options": {
"identityless": "true",
"resourceAppid": "wxe77e91c2fdb64e85",
"resourceEnv": "ibox-3gldlr1u1a8322d4",
"config": {
"database": {
"realtime": {
"maxReconnect": 5,
"reconnectInterval": 5000,
"totalConnectionTimeout": "null"
}
}
},
"appid": "wxe77e91c2fdb64e85",
"env": "ibox-3gldlr1u1a8322d4"
},
"qbase_meta": {
# "session_id": "1657318155315",
"session_id": str(int(time.time() * 1000)),
"sdk_version": "wx-web-sdk/WEBDOMAIN_1.0.0 (1655460325000)",
"filter_user_info": False
},
"cli_req_id": str(int(time.time() * 1000)) + "_0.5101258021009685"
}
}
response = requests.post(url=key_url, headers=headers, json=data)
content = json.loads(response.content)
if content:
data = json.loads(content.get('data'))
token = data.get('token')
key = data.get('key')
timestamp = data.get('timestamp')
print(token, key, timestamp)
return key, token, timestamp
def get_request():
base_url = 'https://web-001.cloud.servicewechat.com/wxa-qbase/container_service?token='
key, token, timestamp = get_key_token()
base_url += token
data = parse_compress_data()
key_bytes = get_bytes(key)
aes_data = aes_encrypt(key_bytes, data)
headers = get_headers(timestamp)
with httpx.Client(http2=True) as client:
response = client.post(base_url, headers=headers, content=aes_data)
print(response.content)
if __name__ == '__main__':
get_request()
在AES加密环节使用的是秘钥key的byte格式,但并不是简单的字符串转bytes,而是按照自定义的规则进行转换,鉴于python实现比较复杂,于是这里使用了python的pyexecjs库来模拟执行js代码,逻辑如下:
import execjs
print(execjs.get().name)
js_method = '''
var y = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
function base64ToArrayBufferMock(e) {
for (var t = function(e) {
var t = String(e).replace(/=+$/, "")
, r = "";
if (t.length % 4 == 1)
throw new Error('"atob" failed');
for (var n = 0, i = void 0, o = void 0, a = 0;
o = t.charAt(a++);
~o && (i = n % 4 ? 64 * i + o : o, n++ % 4) ? r += String.fromCharCode(255 & i >> (-2 * n & 6)) : 0)
o = y.indexOf(o);
return r
}(e), r = t.length, n = new Uint8Array(r), i = 0; i < r; i++)
n[i] = t.charCodeAt(i);
return n
}
'''
loader = execjs.compile(js_method)
def get_bytes(secret_key):
result = loader.call('base64ToArrayBufferMock', secret_key)
arr = []
for k, v in result.items():
arr.append(v)
secret_key_bytes = bytes(arr)
return secret_key_bytes
if __name__ == '__main__':
result = get_bytes("zkXsdQURgkDefISbA6prjw==")
print(result)
注意:pyexecjs库依赖JavaScript运行环境,所以需要安装好node.js
4、遗留问题
- 如上的逻辑并不能绕过目标网站的反爬机制,这里抛砖引玉,哪位同学有更好的思路也希望不吝赐教。
- 核心js文件的console.log()打印不生效,目前未定位到是如何禁用的。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)