Pytorch基础(二)- Tensor数据类型
目录python和Pytorch数据类型pytorch数据类型pytorch类型推断维度为0的标量标量判断维度为1的向量Linear input维度为2的tensorLinear input batch维度为3的tensorRNN input维度为4的tensorCNN input其它的创建Tensor从numpy中引入 torch.from_numpy()从list中导入 torch.tenso
目录
python和Pytorch数据类型
pytorch不支持string.

处理string:
one-hot, Embedding,

pytorch数据类型

pytorch类型推断
tensor.type()
isinstance(a, torch.FloatTensor)

维度为0的标量

标量判断
返回tensor形状/维度,形状维度个数为0则为一个Tensor:
len(a.shape) == 0
len(a.size()) == 0

维度为1的向量 Linear input

维度为2的tensor Linear input batch

维度为3的tensor RNN input

维度为4的tensor CNN input

其它的
a.shape 获得形状
a.numel() 获得tensor占用内存
a.dim() 返回向量维度

创建Tensor
从numpy中引入 torch.from_numpy()
torch.from_numpy(a)
import numpy as np
import torch
a = np.array([1,2,3])
t = torch.from_numpy(a)
print(t)
print(t.type())
输出:
tensor([1, 2, 3], dtype=torch.int32)
torch.IntTensor
从list中导入 torch.tensor()
torch.tensor(list) 接受现有的数据创建tensor,如列表、numpy数组
torch.Tensor / torch.FloatTensor(list) 一般情况下大写的Tensor接受维度信息,但是输入list也可以, 但是为避免混淆,还是建议使用小写的tensor从现有数据创建tensor.
import torch
a = torch.tensor([1,2,3,4])
print(a)
print(a.type())
输出:
tensor([1, 2, 3, 4])
torch.LongTensor
生成未初始化的tensor torch.empty()
生成的tensor里面的数据是不规则的数据(非常大,非常小,或者为0)。
生成数据类型为pytorch默认的数据类型。

后续一定要将未初始化的tensor的数据覆盖掉,否则容易出现nan,inf的情况。

设置默认数据类型 torch.set_default_tensor_type()
torch.Tensor() 生成的数据为默认数据类型
torch.set_default_tensor_type() 设置默认的tensor数据类

生成随机初始化tensor torch.rand randn
torch.rand(shape) 生成数据为0-1之间的均匀分布
torch.rand_like(a) 将a的shape赋值给rand函数,生成与a形状一样的随机tensor
torch.randint( min, max,shape_list) 生成[min, max)之间的随机整数。
import torch
a = torch.rand(3,3)
b = torch.rand_like(a)
c = torch.randint(10,20,[3,3])
print(a)
print(b)
print(c)
输出:
tensor([[0.2608, 0.3953, 0.7723],
[0.1387, 0.5454, 0.2346],
[0.6234, 0.1312, 0.8868]])
tensor([[0.0888, 0.2244, 0.1465],
[0.9179, 0.8248, 0.4669],
[0.5843, 0.0690, 0.3438]])
tensor([[14, 14, 18],
[14, 16, 18],
[13, 16, 19]])
生成符合正太分布的随机数
torch.randn() 默认服从0-1正态分布。
torch.normal(mean,std) 指定均值和方差。
将tensor全服赋值为1个元素 torch.fulll
torch.full(shape, value) 生成元素全为value的指定shape的tensor
import torch
a = torch.full([2,3], 7)
b = torch.full([], 7) #生成一个标量,值7
print(a)
print(b)
print(a.type()
输出:
tensor([[7, 7, 7],
[7, 7, 7]])
tensor(7)
torch.LongTensor
递增递减生成等差数据 torch.arange
torch.arange(min, max, step) step为步长
import torch
a = torch.arange(0,10,2)
print(a)
输出:
tensor([0, 2, 4, 6, 8])
torch.linspace(left, right, steps) 生成等分数据 step为数据的数量
torch.logspace(left, right, steps) left到right之间切割 base参数可以设置为2,10,e等参数。
import torch
a = torch.linspace(0,10,3)
print(a)
a = torch.linspace(0,10,7) #0-10等分切割10个数
print(a)
b = torch.logspace(0,-1, 10) #生成10^0 ~ 10 ^(-1)之间的等分数据
print(b)
输出:
tensor([ 0., 5., 10.])
tensor([ 0.0000, 1.6667, 3.3333, 5.0000, 6.6667, 8.3333, 10.0000])
tensor([1.0000, 0.7743, 0.5995, 0.4642, 0.3594, 0.2783, 0.2154, 0.1668, 0.1292,
0.1000])
生成全零全一,单位矩阵的数据 torch.Ones/zeros/eye()
torch.Ones/zeros/eye()
import torch
a = torch.ones(3,4)
b = torch.zeros(3,3)
c = torch.eye(4)
print(a)
print(b)
print(c)
输出:
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
tensor([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
随机打散一个范围内的数据 torch.randperm
torch.randperm(n) 生成[0,n)之间的打乱的数据
import torch
idx = torch.randperm(5)
print(idx)
输出:
tensor([3, 0, 2, 4, 1])
Tensor的索引和切片
Tensor的索引和python的索引相似。
索引,首先索引第0维数据。
直接索引

连续索引

索引+步长

…任意的维度
a[…] = a[:,:,:,:]
a[0,…] = a[0,:,:,:]
a[:,1, …] = a[:,1,:,:]
a[…,:2] = a[:,:,:,:2]
a[0,…,::2] = a[0,:,:,::2]

获取指定维度上的指定索引
a.index_select(dim, indexes) 表示在哪一个维度上进行索引
import torch
a = torch.randn(4,3,28,28)
b = a.index_select(2,torch.arange(20)) #选取所有图像前20行
c = a.index_select(0,torch.tensor([0,2])) #选取第0和第二2张图像, 第二个参数index必须为tensor
print(b.size())
print(c.size())
输出:
torch.Size([4, 3, 20, 28])
torch.Size([2, 3, 28, 28])
使用掩码的索引
torch.masked_select()
import torch
a = torch.randn(3,4)
mask = a.ge(0.5)
b = a.masked_select(mask)
print(a)
print(mask)
print(b)
输出:
tensor([[-1.4989, 0.7418, 1.5531, -0.4406],
[-0.2969, 0.3999, 0.4586, 1.0370],
[ 0.0624, 1.5981, 0.8669, 2.3349]])
tensor([[False, True, True, False],
[False, False, False, True],
[False, True, True, True]])
tensor([0.7418, 1.5531, 1.0370, 1.5981, 0.8669, 2.3349])
使用展平的的索引
torch.take() 将tensor先展平,然后通过展平后来索引,使用频率不高。
import torch
a = torch.randn(3,4)
b = a.take(torch.tensor([0,6]))
print(a)
print(b)
输出:
tensor([[ 0.0684, 0.1547, -0.0695, 1.0046],
[ 0.0481, -0.7794, 0.1260, 0.3270],
[ 0.1343, -0.3111, -1.1746, -0.6975]])
tensor([0.0684, 0.1260])
Tensor维度的变换
view/reshape在Tensor元素个数不变情况下,将一个shape转换为另一个shape。
Squeeze 删减维度 unsqueeze 增加维度
Transpose/t/permute
Expand/repeat 增加维度

shape转换 view/reshape
保证numel()一致就可以随意shape转换。
import torch
a = torch.randn(4, 1, 28, 28) #假设为MINIST数据集
print(a.shape)
b = a.view(4 ,28,28)
print(b.shape)
c = a.view(4,28*28) #将图像展平
print(c.shape)
d = a.view(4*28, 28) #关注所有图像所行
print(d.shape)
输出:
torch.Size([4, 1, 28, 28])
torch.Size([4, 28, 28])
torch.Size([4, 784])
torch.Size([112, 28])
增加维度 unsqueeze
unsqueeze操作用的非常频繁。
torch.unqueeze(a, pos) 如果pos大于等于0[正的索引], 则是在pos前插入一个维度
如果pos小于0[负的索引],则是在pos后插入一个维度。
pos的范围 [-a.dim()-1, a.dim()+1)
unsqueeze并不会增加数据,或者减少数据,只是为数据增加了一个组别。
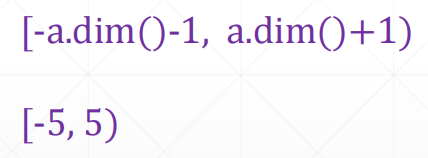


import torch
a = torch.randn(4, 1, 28, 28) #假设为MINIST数据集
print('a',a.shape)
b = torch.unsqueeze(a, 0) #在0维度前面插入一个维度 没有增加数据
print('b', b.shape)
c = a.unsqueeze(4) #在4维度前面插入一个维度
print('c', c.shape)
d = a.unsqueeze(2) #在第2个维度前面插入一个维度
print('d', d.shape)
e = a.unsqueeze(-1) #在最后-1维度后面插入一个维度
print('e',e.shape)
f = a.unsqueeze(-3) #在-3维度后面之后插入一个维度
print('f',f.shape)
输出:
a torch.Size([4, 1, 28, 28])
b torch.Size([1, 4, 1, 28, 28])
c torch.Size([4, 1, 28, 28, 1])
d torch.Size([4, 1, 1, 28, 28])
e torch.Size([4, 1, 28, 28, 1])
f torch.Size([4, 1, 1, 28, 28])
偏置和图像叠加:
import torch
bias = torch.randn(32)
f = torch.rand(4, 32, 14,14) #bias相当于每个通道上的偏置
# 将bias叠加在f上
b = bias.unsqueeze(0).unsqueeze(2).unsqueeze(3) #[1,32]->[1,32,1]->[1,32,1,1]
print(b.shape)
输出:
torch.Size([1, 32, 1, 1])
维度挤压 squeeze
squeeze(dim) 挤压所有dim上为1的维度。
import torch
bias = torch.randn(32)
f = torch.rand(4, 32, 14,14) #bias相当于每个通道上的偏置
# 将bias叠加在f上
b = bias.unsqueeze(0).unsqueeze(2).unsqueeze(3) #[1,32]->[1,32,1]->[1,32,1,1]
print('b', b.shape)
c = b.squeeze() #挤压掉所有为1的维度
print('c', c.shape)
d = b.squeeze(0) #挤压掉0维数据
print('d', d.shape)
e = b.squeeze(1) #挤压掉第1维数据 如果第1维大小不为1,则挤压失败,返回原来的维度
print('e', e.shape)
f = b.squeeze(-4) #挤压第-4维维度
print('f', f.shape)
输出:
b torch.Size([1, 32, 1, 1])
c torch.Size([32])
d torch.Size([32, 1, 1])
e torch.Size([1, 32, 1, 1])
f torch.Size([32, 1, 1])
维度扩展 Expand/repeat
Expand:只是改变了理解方式,并没有增加数据,参数为扩展到多少维度
repeat:实实在在增加了数据(复制了内存),参数为要拷贝的次数
最终的效果是等效的,Expand只会在有需要的时候复制数据。

expand测试
import torch
bias = torch.randn(32)
f = torch.rand(4, 32, 14,14) #bias相当于每个通道上的偏置
# 将bias叠加在f上
b = bias.unsqueeze(0).unsqueeze(2).unsqueeze(3) #[1,32]->[1,32,1]->[1,32,1,1]
print('b', b.shape)
# c = b.expand(4,10,1,1) #扩展第0个维度 第1个维度不为1,所以该扩展失败(报错),其余维度不变
d = b.expand(4,32,14,14) #扩展所有维度
print(d.shape)
e = b.expand(100,32,1,1)
print(e.shape)
输出:
b torch.Size([1, 32, 1, 1])
torch.Size([4, 32, 14, 14])
torch.Size([100, 32, 1, 1])
repeat测试
import torch
bias = torch.randn(32)
f = torch.rand(4, 32, 14,14) #bias相当于每个通道上的偏置
# 将bias叠加在f上
b = bias.unsqueeze(0).unsqueeze(2).unsqueeze(3) #[1,32]->[1,32,1]->[1,32,1,1]
print('b', b.shape)
c = b.repeat(4,32,14,14) #[1,32,1,1] -> [14,32,14,14] 拷贝
print('after repeat all dim:', b.shape)
d = b.repeat(10,32,1,1) #[1,32,1,1]->[1*10,32*32,1,1]拷贝第一个维度10次,第二个维度拷贝32次, 其余的拷贝一次
print('repeat dim 0,1:', d.shape)
输出:
b torch.Size([1, 32, 1, 1])
after repeat all dim: torch.Size([1, 32, 1, 1])
repeat dim 0,1: torch.Size([10, 1024, 1, 1])
tensor转置
只会在维度为2的tensor上进行转置.t()操作。
import torch
b = torch.randn(3,4)
print('b', b.shape)
c = b.t()
print('b.t()', c.shape)
输出:
b torch.Size([3, 4])
b.t() torch.Size([4, 3])
transpose() 交换两个维度
view()会导致维度顺序关系变模糊,所以需要人为跟踪。view了维度之后,一定要记住view之前维度的先后顺序。
contiguous()将数据重新申请一片连续的内存并将数据复制过来。一般使用transppose(),permute()函数过后需要view()操作,就需要使用contiguous()函数使数据内存连续。
import torch
a = torch.randn(4,3,32,32)
b = a.transpose(1,3).contiguous().view(4,3*32*32).view(4,3,32,32) #数据污染了
c = a.transpose(1,3).contiguous().view(4,3*32*32).view(4,32,32,3).transpose(1,3)
d = a.transpose(1,3).contiguous().view(-1) #使用a.transpose(1,3).view(-1)会报错, 必须要加一个contiguous()函数
permute转置
[b,h,w,c]是numpy图片的格式。需要将[b,c,h,w]转换为[b,h,w,c]才能导出为numpy.
MINIST数据集是numpy格式,那么需要用到torchvision.transforms.Totensor()将维度进行变换,并且转为tensor.
#将tensor图像数据转换为numpy图像数据
#将tensor图像数据转换为numpy图像数据
import torch
a = torch.randn(4,3,32,32)
print(a.shape)
b = a.transpose(1,3).transpose(1,2) #[b,c,h,w]->[b,w,h,c]->[b,h,w,c]
print(b.shape)
c = a.permute(0,2,3,1)
print(c.shape)
输出:
torch.Size([4, 3, 32, 32])
torch.Size([4, 32, 32, 3])
torch.Size([4, 32, 32, 3])
Tensor的广播/自动扩展
Broadcasting:(自动)维度扩展,不需要拷贝数据

Broadcasting自动扩展的步骤:
从最小维度(shape从最右维度)开始匹配,如果匹配维度前面没有维度,则插入一个新的维度(没有增加数据)。(unsqueeze)
然后将扩展的维度变成相同的size。(expand)
[4,32,14,14]与[32,1,1]
第一个匹配的维度是前一个数据的第二维,size为32,对应第二个数据的第零维,则需要在第二个数据前面扩展维一个维度,使之与第一个数据匹配。


#tensor自动扩张
import torch
a = torch.randn(2,3,3)
b = torch.tensor([5.0])
print(a)
print(a+b)
输出:
tensor([[[ 1.3627, -0.3175, 0.9737],
[-1.0720, 0.3555, -1.0382],
[ 0.4370, -1.2669, 1.8456]],
[[-0.2490, 2.1087, -1.2171],
[ 0.1234, -0.7962, -0.0916],
[-0.2550, 0.2806, -1.1539]]])
tensor([[[6.3627, 4.6825, 5.9737],
[3.9280, 5.3555, 3.9618],
[5.4370, 3.7331, 6.8456]],
[[4.7510, 7.1087, 3.7829],
[5.1234, 4.2038, 4.9084],
[4.7450, 5.2806, 3.8461]]])

什么情况下可以使用broadcasting
小维度指定,大维度随意。
1.缺失维度,扩展至同一维度,扩展至统一大小
2.维度不缺失,dim_size =1, 扩展至相同大小

例子:
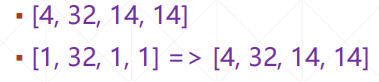


必须要从最小维度开始匹配:


Tensor的合并与分割
tensor的拼接与拆分

cat操作
torch.cat(Tensors, dim) cat拼接的tensor必须在非cat维度上一致。


#tensor拼接
import torch
a = torch.rand(4,32,8)
b = torch.rand(5,32,8)
c = torch.cat((a,b),dim=0)
print(c.shape)
输出:
torch.Size([9, 32, 8])
stack操作
stack会创建一个新的维度,这个新建的维度的概念取决于具体的场景。并且stack的tensor的维度必须完全一摸一样。
#tensor堆叠
import torch
a = torch.rand(4,32,8)
b = torch.rand(4,32,8)
c = torch.stack((a,b),dim=0)
print(c.shape)
输出:
torch.Size([2, 4, 32, 8])
split操作
torch.split根据指定块的长度拆分。
#tensor拆分
import torch
a = torch.rand(4,3,3)
aa,bb = torch.split(a,[1,3], dim=0)
print(aa.shape)
print(bb.shape)
cc,dd = torch.split(a, 2, dim = 0) #在0维度上按照单元长度为2进行拆分
print(cc.shape)
print(dd.shape)
输出:
torch.Size([1, 3, 3])
torch.Size([3, 3, 3])
torch.Size([2, 3, 3])
torch.Size([2, 3, 3])
chunk操作
torc.chunk根据数量拆分。指定要拆分成多少个块
#tensor拆分
import torch
a = torch.rand(4,3,3)
bb,cc,dd,ee = torch.chunk(a,4,dim=0) #将零维度拆分为4个块
print(bb.shape)
print(cc.shape)
print(dd.shape)
print(ee.shape)
输出:
torch.Size([1, 3, 3])
torch.Size([1, 3, 3])
torch.Size([1, 3, 3])
torch.Size([1, 3, 3])
Tensor的数学运算

加减乘除操作 element-wise
+ - * / 操作:逐元素计算
torch.add
torch.sub
torch.mul
torch.div

矩阵乘法
torch.mm 只适用于2维矩阵的乘法
torch.matmul
@ 等同于torch.matmul 写法更简洁
#tensor矩阵乘法
import torch
a = torch.full((2,2),3.)
b = torch.ones((2,2))
c = a.mm(b) #只适用于2维矩阵的乘法
d = torch.mm(a,b)
e = torch.matmul(a,b) #推荐使用这个方法,更加易懂
f = a@b #@符号更加简洁
print(a)
print(b)
print(c)
print(d)
print(e)
print(f)
输出:
tensor([[3., 3.],
[3., 3.]])
tensor([[1., 1.],
[1., 1.]])
tensor([[6., 6.],
[6., 6.]])
tensor([[6., 6.],
[6., 6.]])
tensor([[6., 6.],
[6., 6.]])
tensor([[6., 6.],
[6., 6.]])
神经网络线性层乘法:
#tensor线性层矩阵乘法
import torch
x = torch.rand(4,784)
w = torch.rand(512, 784)
out = x.matmul(w.t()) #.t()只适合二维的转置,如果是高维的矩阵,则使用transpose进行转置
print(out.shape)
out = x@w.t()
print(out.shape)
输出:
torch.Size([4, 512])
torch.Size([4, 512])
高维的神经网络数据乘法:
不能使用torch.mm,使用torch.matmul,torch.matmul只取最后两维数据进行计算。
#tensor高维矩阵乘法
import torch
x = torch.rand(4,3,28,64)
w = torch.rand(4,3,64,32)
w2 = torch.rand(4,1,64,128)
out = torch.matmul(x,w)
print(out.shape)
out2 = torch.matmul(x,w2) #w2通过广播机制转换为[4,3,64,128]
print(out2.shape)
输出:
torch.Size([4, 3, 28, 32])
torch.Size([4, 3, 28, 128])
幂运算
Tensor每个元素做幂运算/取平方根/平方根的倒数。
** 幂运算
torch.pow 幂运算
torch.sqrt 取平方根
torch.rsqrt取平方根的倒数
#tensor高维矩阵乘法
import torch
a = torch.full((2,2),3)
b = a**2
c = a.pow(2)
print(a)
print(b)
print(c)
d = b.sqrt()
e = b.rsqrt()
print(d)
print(e)
输出:
tensor([[3, 3],
[3, 3]])
tensor([[9, 9],
[9, 9]])
tensor([[9, 9],
[9, 9]])
tensor([[3., 3.],
[3., 3.]])
tensor([[0.3333, 0.3333],
[0.3333, 0.3333]])
exp log
import torch
a = torch.exp(torch.full((2,2),1))
print(a)
print(torch.log(a)) #以e为取log, 此外还有log2(以2为底) log10(以10为底)
输出:
tensor([[2.7183, 2.7183],
[2.7183, 2.7183]])
tensor([[1., 1.],
[1., 1.]])
近似值
torch.floor() tensor数值向下取整
torch.ceil() tensor数值向上取整
torch.round() tensor数值取四舍五入
torch.trunc() tensor数值取整数部分
torch.frac() tensor的小数部分

import torch
a = torch.tensor([3.14, 5.67, 10])
print('*'*10)
print(a.floor())
print('*'*10)
print(a.ceil())
print('*'*10)
print(a.trunc())
print('*'*10)
print(a.frac())
print('*'*10)
print(a.round())
输出:
**********
tensor([ 3., 5., 10.])
**********
tensor([ 4., 6., 10.])
**********
tensor([ 3., 5., 10.])
**********
tensor([0.1400, 0.6700, 0.0000])
**********
tensor([ 3., 6., 10.])
clamp裁剪
clamp函数用于裁剪,比如梯度裁剪。梯度弥散就是梯度接近于0,一般可通过修改网络来解决,梯度爆炸就是梯度非常大,比如100,10^3…
可以通过w.grad.norm(2) 打印梯度的模(l2范数)来查看。一般10左右小于10是合适的。

import torch
grad = torch.rand(2,3)*15
print(grad.median())
print(grad.norm(2))
clip_grad = grad.clamp(10) #将梯度小于10的设置为10
print(clip_grad)
clip_grad = grad.clamp(5,10) #将梯度设置为5-10之间
print(clip_grad)
输出:
tensor(3.1846)
tensor(21.2192)
tensor([[14.6256, 10.0000, 10.8478],
[10.0000, 10.0000, 10.0000]])
tensor([[10.0000, 5.0000, 10.0000],
[ 5.0000, 9.7487, 5.0000]])
Tensor的统计属性

求范数 norm
 norm指的是范数,不是normalize;
norm指的是范数,不是normalize;
向量范数和矩阵范数:

norm-p
import torch
a = torch.full([8],1, dtype = torch.float)
b = a.view(2,4)
c = a.view(2,2,2)
print(a.norm(1), b.norm(1), c.norm(1))
print(a.norm(2), b.norm(2), c.norm(2))
print(b.norm(1, dim = 1))
print(c.norm(2, dim = 0))
输出:
tensor(8.) tensor(8.) tensor(8.)
tensor(2.8284) tensor(2.8284) tensor(2.8284)
tensor([4., 4.])
tensor([[1.4142, 1.4142],
[1.4142, 1.4142]])
常见统计属性 mean,sum,min,max,prod
prod 累乘函数
mean,max,min等如果没有指定维度,则会将tensor展平,然后再统计。
import torch
a = torch.arange(8).view(2,4).float()
print(a.min(), a.max())
print(a.sum(), a.mean())
print(a.prod())
print(a.argmax(), a.argmin())
输出:
tensor(0.) tensor(7.)
tensor(28.) tensor(3.5000)
tensor(0.)
tensor(7) tensor(0)
dim指定维度
import torch
t = torch.arange(8).reshape(2,4).float()
print('**Caculate after flatten..')
print(t.max())
print(t.min())
print(t.sum())
print(t.mean())
print(t.prod())
print('**Get the position of the max/min elements on all dim..')
print(t.argmax())
print(t.argmin())
print('**Gaculate on special dim..')
print(t.mean(1))
print(t.max(1))
print(t.min(0))
print(t.sum(0))
print(t.prod(1))
输出:
**Caculate after flatten..
tensor(7.)
tensor(0.)
tensor(28.)
tensor(3.5000)
tensor(0.)
**Get the position of the max/min elements on all dim..
tensor(7)
tensor(0)
**Gaculate on special dim..
tensor([1.5000, 5.5000])
torch.return_types.max(
values=tensor([3., 7.]),
indices=tensor([3, 3]))
torch.return_types.min(
values=tensor([0., 1., 2., 3.]),
indices=tensor([0, 0, 0, 0]))
tensor([ 4., 6., 8., 10.])
tensor([ 0., 840.])
keepdim保持维度
import torch
t = torch.arange(8).reshape(2,4).float()
print('**Gaculate on special dim..')
print(t.max(1, keepdim=True))
print(t.min(0, keepdim=True))
print(t.sum(0, keepdim=True))
输出:
**Gaculate on special dim..
torch.return_types.max(
values=tensor([[3.],
[7.]]),
indices=tensor([[3],
[3]]))
torch.return_types.min(
values=tensor([[0., 1., 2., 3.]]),
indices=tensor([[0, 0, 0, 0]]))
tensor([[ 4., 6., 8., 10.]])
top-k k-th
topk:比max提供了更多的信息
kthvalue:第K小的值
import torch
t = torch.arange(8).reshape(2,4).float() #K大值
t2 = t.topk(3, dim=1)
print(t2)
t3 = t.topk(3, dim=1, largest=False) #K小值
print(t3)
print('*'*20)
t4 = t.kthvalue(2, dim=1)
print(t4)
输出:
torch.return_types.topk(
values=tensor([[3., 2., 1.],
[7., 6., 5.]]),
indices=tensor([[3, 2, 1],
[3, 2, 1]]))
torch.return_types.topk(
values=tensor([[0., 1., 2.],
[4., 5., 6.]]),
indices=tensor([[0, 1, 2],
[0, 1, 2]]))
********************
torch.return_types.kthvalue(
values=tensor([1., 5.]),
indices=tensor([1, 1]))
compare
-
,>=,<,<=,==,!=
- torch.eq(a,b) torch.equal(a,b)
import torch
a = torch.arange(8).reshape(2,4).float() #K大值
r = a>0
print(r)
r2 = torch.gt(a,1)
print(r2)
#判断每个元素是否相等
r3 = torch.eq(a,a)
#判断两个Tensor是否每个元素都相等
r4 = torch.equal(a,a)
print(r3)
print(r4)
b = torch.ones(2,4)
r5 = torch.eq(a,b) #bool和0,1进行比较
r6 = torch.equal(a,b)
print(r5)
print(r6)
输出:
tensor([[False, True, True, True],
[ True, True, True, True]])
tensor([[False, False, True, True],
[ True, True, True, True]])
tensor([[True, True, True, True],
[True, True, True, True]])
True
tensor([[False, True, False, False],
[False, False, False, False]])
False
Tensor的高阶操作
where

赋值语句高度并行
import torch
cond = torch.tensor([[0.6,0.7],[0.8,0.4]])
a = torch.ones(2,2)
b = torch.zeros(2,2)
c = torch.where(cond>0.6, a,b)
print(c)
输出:
tensor([[0., 1.],
[1., 0.]])
gather
根据提供的表和索引收集数据

import torch
table = torch.arange(4,8)
index = torch.tensor([0,2,1,0,3,0])
t = torch.gather(table,dim=0,index=index)
print(t)
输出:
tensor([4, 6, 5, 4, 7, 4])

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)