深入理解GBDT回归算法
点击上方“小白学视觉”,选择加"星标"或“置顶”重磅干货,第一时间送达来源:公众号Microstrong授权转载目录:1. GBDT简介2. GBDT回归算法2.1 GBDT回归算法推导2.2 GBDT回归算法实例3. 手撕GBDT回归算法3.1 用Python3实现GBDT回归算法3.2 用sklearn实现GBD...
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:公众号 Microstrong 授权转载
目录:
1. GBDT简介
2. GBDT回归算法
2.1 GBDT回归算法推导
2.2 GBDT回归算法实例
3. 手撕GBDT回归算法
3.1 用Python3实现GBDT回归算法
3.2 用sklearn实现GBDT回归算法
4. GBDT回归任务常见的损失函数
5. GBDT的正则化
6. 关于GBDT若干问题的思考
7. 总结
8. Reference
本文的主要内容概览:
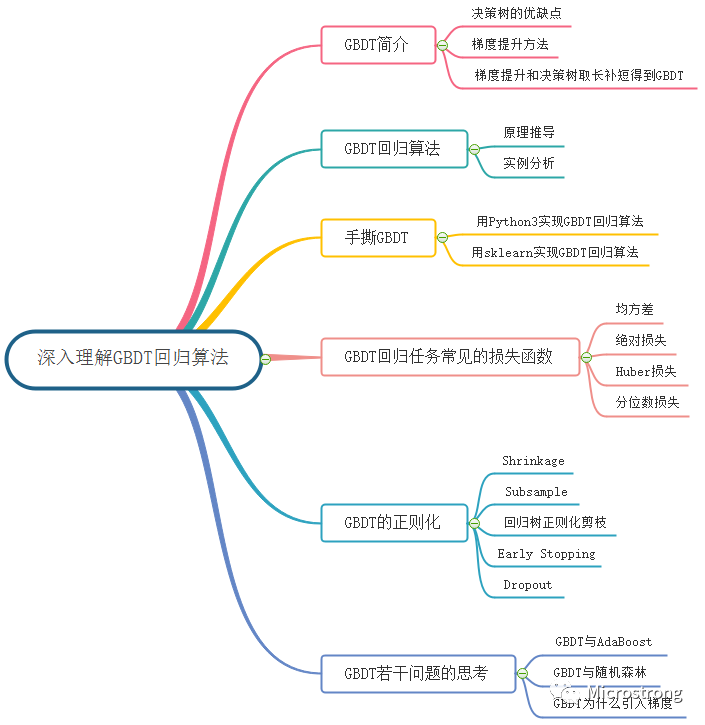
1. GBDT简介
Boosting、Bagging和Stacking是集成学习(Ensemble Learning)的三种主要方法。Boosting是一族可将弱学习器提升为强学习器的算法,不同于Bagging、Stacking方法,Boosting训练过程为串联方式,弱学习器的训练是有顺序的,每个弱学习器都会在前一个学习器的基础上进行学习,最终综合所有学习器的预测值产生最终的预测结果。
梯度提升(Gradient Boosting)算法是一种用于回归、分类和排序任务的机器学习技术,属于Boosting算法族的一部分。之前我们介绍过Gradient Boosting算法在迭代的每一步构建一个能够沿着梯度最陡的方向降低损失的学习器来弥补已有模型的不足。经典的AdaBoost算法只能处理采用指数损失函数的二分类学习任务,而梯度提升方法通过设置不同的可微损失函数可以处理各类学习任务(多分类、回归、Ranking等),应用范围大大扩展。梯度提升算法利用损失函数的负梯度作为残差拟合的方式,如果其中的基函数采用决策树的话,就得到了梯度提升决策树 (Gradient Boosting Decision Tree, GBDT)。
基于梯度提升算法的学习器叫做GBM(Gradient Boosting Machine)。理论上,GBM可以选择各种不同的学习算法作为基学习器。现实中,用得最多的基学习器是决策树。
决策树有以下优点:
决策树可以认为是if-then规则的集合,易于理解,可解释性强,预测速度快。
决策树算法相比于其他的算法需要更少的特征工程,比如可以不用做特征标准化。
决策树可以很好的处理字段缺失的数据。
决策树能够自动组合多个特征,也有特征选择的作用。
对异常点鲁棒
可扩展性强,容易并行。
决策树有以下缺点:
缺乏平滑性(回归预测时输出值只能输出有限的若干种数值)。
不适合处理高维稀疏数据。
单独使用决策树算法时容易过拟合。
我们可以通过抑制决策树的复杂性,降低单棵决策树的拟合能力,再通过梯度提升的方法集成多个决策树,最终能够很好的解决过拟合的问题。由此可见,梯度提升方法和决策树学习算法可以互相取长补短,是一对完美的搭档。
2. GBDT回归算法
2.1 GBDT回归算法推导
当我们采用的基学习器是决策树时,那么梯度提升算法就具体到了梯度提升决策树。GBDT算法又叫MART(Multiple Additive Regression),是一种迭代的决策树算法。GBDT算法可以看成是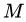 棵树组成的加法模型,其对应的公式如下:
棵树组成的加法模型,其对应的公式如下:
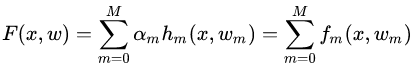
其中,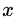 为输入样本;
为输入样本;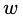 为模型参数;
为模型参数;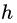 为分类回归树;
为分类回归树;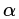 为每棵树的权重。GBDT算法的实现过程如下:
为每棵树的权重。GBDT算法的实现过程如下:
给定训练数据集: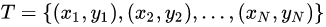 其中,
其中, 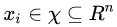 ,
,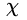 为输入空间,
为输入空间,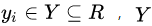 为输出空间,损失函数为
为输出空间,损失函数为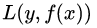 ,我们的目标是得到最终的回归树
,我们的目标是得到最终的回归树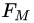 。
。
(1)初始化第一个弱学习器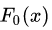 :
:
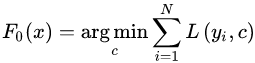
(2)对于建立M棵分类回归树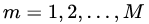 :
:
a)对 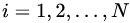 ,计算第
,计算第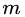 棵树对应的响应值(损失函数的负梯度,即伪残差):
棵树对应的响应值(损失函数的负梯度,即伪残差):
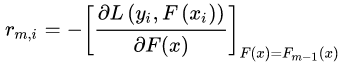
b)对于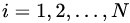 ,利用CART回归树拟合数据
,利用CART回归树拟合数据 ,得到第
,得到第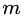 棵回归树,其对应的叶子节点区域为
棵回归树,其对应的叶子节点区域为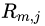 ,其中
,其中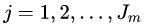 ,且
,且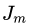 为第
为第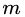 棵回归树叶子节点的个数。
棵回归树叶子节点的个数。
c)对于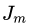 个叶子节点区域
个叶子节点区域 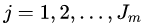 ,计算出最佳拟合值:
,计算出最佳拟合值:
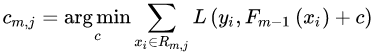
d)更新强学习器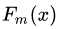 :
:
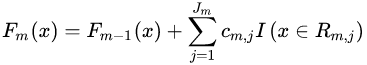
(3)得到强学习器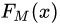 的表达式:
的表达式:
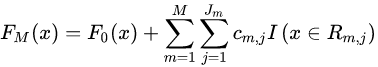
2.2 GBDT回归算法实例
(1)数据集介绍
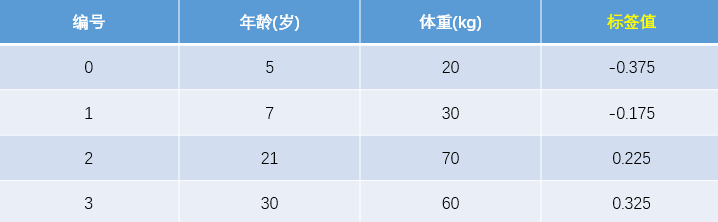
训练集如下表所示,一组数据的特征有年龄和体重,身高为标签值,共有4组数据。
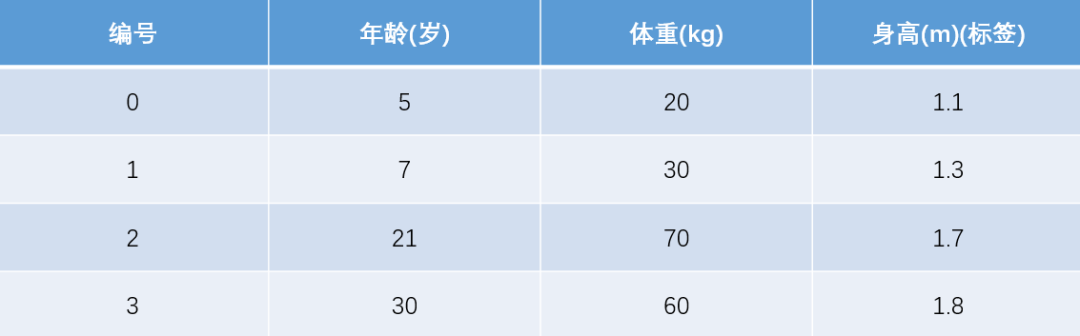
测试数据如下表所示,只有一组数据,年龄为25、体重为65,我们用在训练集上训练好的GBDT模型预测该组数据的身高值为多少。

(2)模型训练阶段
参数设置:
学习率:learning_rate = 0.1
迭代次数:n_trees = 5
树的深度:max_depth = 3
1)初始化弱学习器:
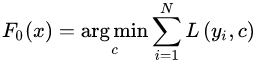
损失函数为平方损失,因为平方损失函数是一个凸函数,可以直接求导,令导数等于零,得到 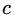 。
。
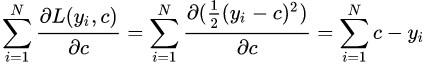
令导数等于0:
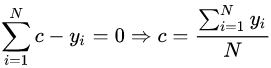
所以初始化时,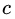 取值为所有训练样本标签值的均值。
取值为所有训练样本标签值的均值。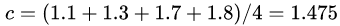 ,此时得到的初始化学习器为
,此时得到的初始化学习器为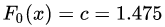 。
。
2)对于建立M棵分类回归树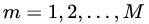 :
:
由于我们设置了迭代次数:n_trees=5,这就是设置了M=5。
首先计算负梯度,根据上文损失函数为平方损失时,负梯度就是残差,也就是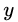 与上一轮得到的学习器
与上一轮得到的学习器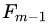 的差值:
的差值:

现将残差的计算结果列表如下:
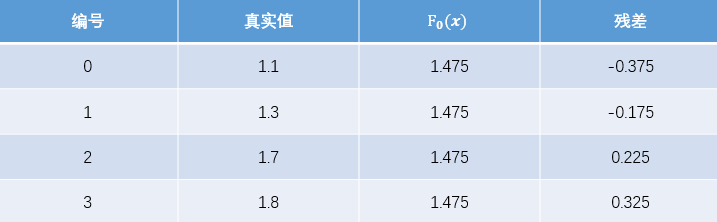
此时将残差作为样本的真实值来训练弱学习器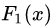 ,即下表数据:
,即下表数据:
接着寻找回归树的最佳划分节点,遍历每个特征的每个可能取值。从年龄特征值为5开始,到体重特征为70结束,分别计算分裂后两组数据的平方损失(Square Error), 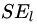 为左节点的平方损失,
为左节点的平方损失,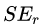 为右节点的平方损失,找到使平方损失和
为右节点的平方损失,找到使平方损失和 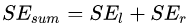 最小的那个划分节点,即为最佳划分节点。
最小的那个划分节点,即为最佳划分节点。
例如:以年龄7为划分节点,将小于7的样本划分为左节点,大于等于7的样本划分为右节点。左节点包括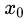 ,右节点包括样本
,右节点包括样本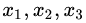 ,则
,则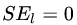 、
、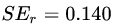 、
、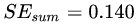 ,所有可能的划分情况如下表所示:
,所有可能的划分情况如下表所示:
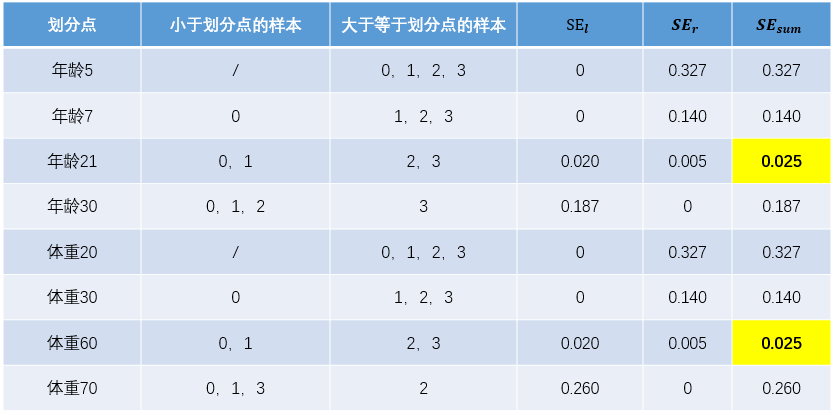
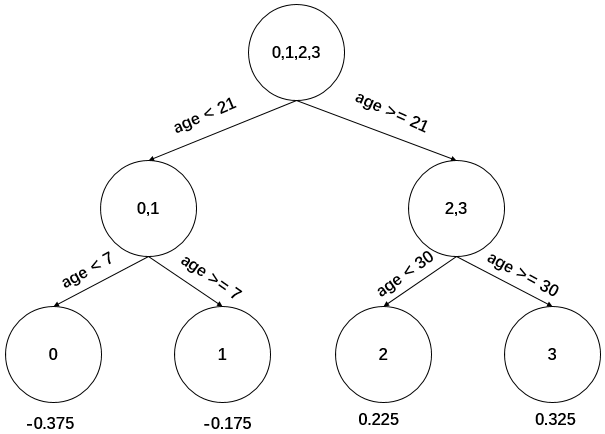
以上划分点的总平方损失最小为0.025有两个划分点:年龄21和体重60,所以随机选一个作为划分点,这里我们选年龄21。现在我们的第一棵树长这个样子:
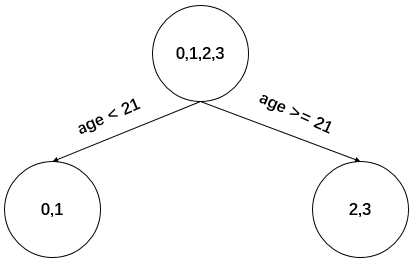
我们设置的参数中树的深度max_depth=3,现在树的深度只有2,需要再进行一次划分,这次划分要对左右两个节点分别进行划分:
对于左节点,只含有0,1两个样本,根据下表结果我们选择年龄7为划分点(也可以选体重30)。
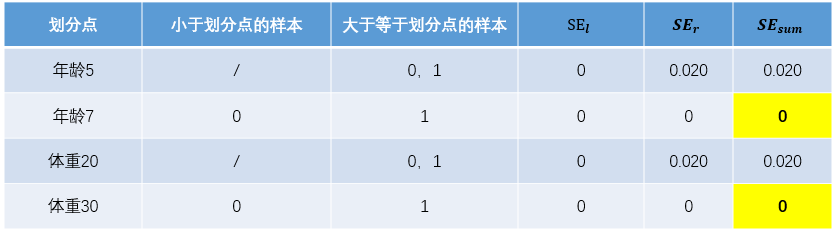
对于右节点,只含有2,3两个样本,根据下表结果我们选择年龄30为划分点(也可以选体重70)。
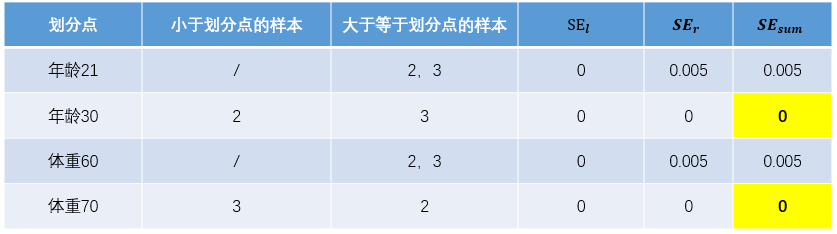
现在我们的第一棵回归树长下面这个样子:
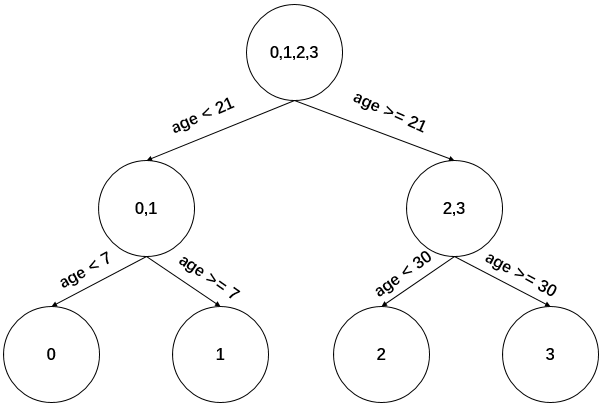
此时我们的树深度满足了设置,还需要做一件事情,给这每个叶子节点分别赋一个参数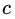 ,来拟合残差。
,来拟合残差。
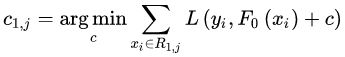
这里其实和上面初始化弱学习器是一样的,对平方损失函数求导,令导数等于零,化简之后得到每个叶子节点的参数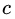 ,其实就是标签值的均值。这个地方的标签值不是原始的
,其实就是标签值的均值。这个地方的标签值不是原始的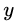 ,而是本轮要拟合的标残差
,而是本轮要拟合的标残差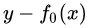 。
。
根据上述划分结果,为了方便表示,规定从左到右为第1,2,3,4个叶子结点,其计算值过程如下:

此时的树长这下面这个样子:
此时可更新强学习器,需要用到参数学习率:learning_rate=0.1,用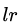 表示。更新公式为:
表示。更新公式为:
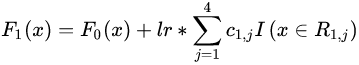
为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上拟合值 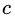 ,即学习率为1,很容易一步学到位导致GBDT过拟合。
,即学习率为1,很容易一步学到位导致GBDT过拟合。
重复此步骤,直到  结束,最后生成5棵树。
结束,最后生成5棵树。
下面将展示每棵树最终的结构,这些图都是我GitHub上用Python3实现GBDT代码生成的,感兴趣的同学可以去运行一下代码。地址:https://github.com/Microstrong0305/WeChat-zhihu-csdnblog-code/tree/master/Ensemble%20Learning/GBDT_Regression
第一棵树:
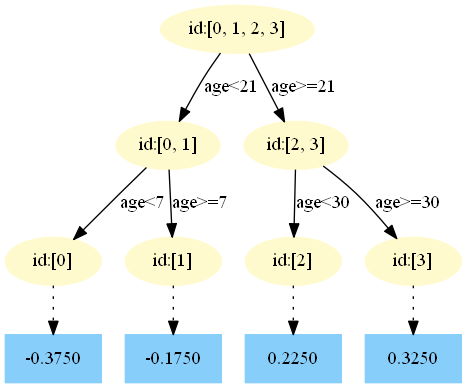
第二棵树:
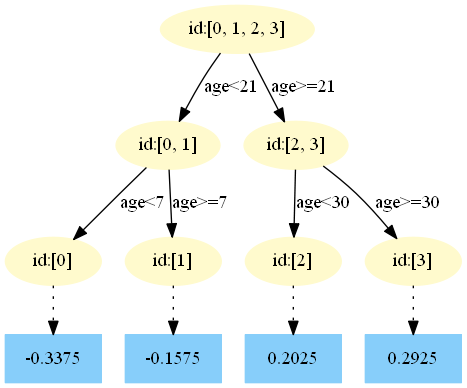
第三棵树:
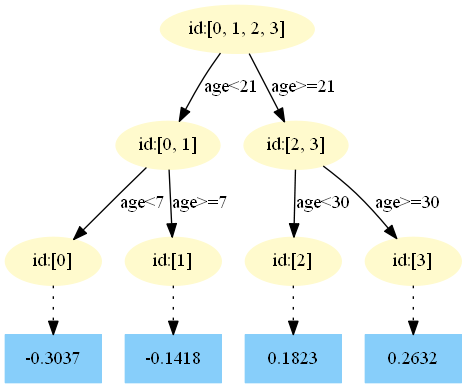
第四棵树:

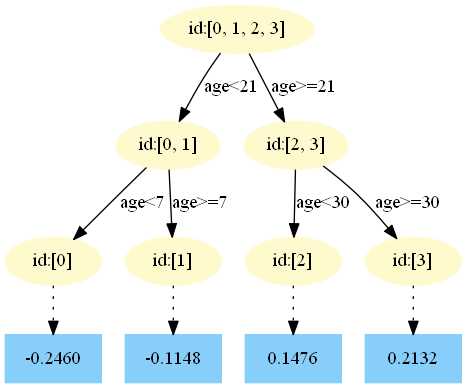
第五棵树:
3)得到最后的强学习器:
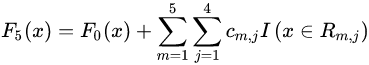
(3)模型预测阶段
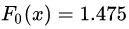
在
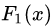 中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.2250。
中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.2250。在
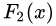 中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.2025。
中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.2025。在
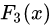 中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.1823。
中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.1823。在
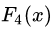 中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.1640。
中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.1640。在
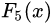 中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.1476。
中,测试样本的年龄为25,大于划分节点21岁,又小于30岁,所以被预测为0.1476。
最终预测结果为:
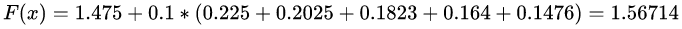
3. 手撕GBDT回归算法
本篇文章所有数据集和代码均在我的GitHub中,地址:https://github.com/Microstrong0305/WeChat-zhihu-csdnblog-code/tree/master/Ensemble%20Learning
3.1 用Python3实现GBDT回归算法
需要的Python库:
pandas、PIL、pydotplus、matplotlib其中pydotplus库会自动调用Graphviz,所以需要去Graphviz官网下载graphviz-2.38.msi安装,再将安装目录下的bin添加到系统环境变量,最后重启计算机。
由于用Python3实现GBDT回归算法代码量比较多,我这里就不列出详细代码了,感兴趣的同学可以去我的GitHub中看一下,地址:https://github.com/Microstrong0305/WeChat-zhihu-csdnblog-code/tree/master/Ensemble%20Learning/GBDT_Regression
3.2 用sklearn实现GBDT回归算法
import numpy as np
from sklearn.ensemble import GradientBoostingRegressor
gbdt = GradientBoostingRegressor(loss='ls', learning_rate=0.1, n_estimators=5, subsample=1
, min_samples_split=2, min_samples_leaf=1, max_depth=3
, init=None, random_state=None, max_features=None
, alpha=0.9, verbose=0, max_leaf_nodes=None
, warm_start=False
)
train_feat = np.array([[1, 5, 20],
[2, 7, 30],
[3, 21, 70],
[4, 30, 60],
])
train_id = np.array([[1.1], [1.3], [1.7], [1.8]]).ravel()
test_feat = np.array([[5, 25, 65]])
test_id = np.array([[1.6]])
print(train_feat.shape, train_id.shape, test_feat.shape, test_id.shape)
gbdt.fit(train_feat, train_id)
pred = gbdt.predict(test_feat)
total_err = 0
for i in range(pred.shape[0]):
print(pred[i], test_id[i])
err = (pred[i] - test_id[i]) / test_id[i]
total_err += err * err
print(total_err / pred.shape[0])用sklearn中的GBDT库实现GBDT回归算法的难点在于如何更好的调节下列参数:

用sklearn实现GBDT回归算法的GitHub地址:https://github.com/Microstrong0305/WeChat-zhihu-csdnblog-code/tree/master/Ensemble%20Learning/GBDT_Regression_sklearn
4. GBDT回归任务常见的损失函数
对于GBDT回归模型,sklearn中实现了四种损失函数,有均方差'ls', 绝对损失'lad', Huber损失'huber'和分位数损失'quantile'。默认是均方差'ls'。一般来说,如果数据的噪音点不多,用默认的均方差'ls'比较好。如果是噪音点较多,则推荐用抗噪音的损失函数'huber'。而如果我们需要对训练集进行分段预测的时候,则采用'quantile'。下面我们具体来了解一下这四种损失函数。
(1)均方差,这个是最常见的回归损失函数了,公式如下:
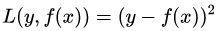
对应的负梯度误差为:
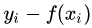
(2)绝对损失,这个损失函数也很常见,公式如下:
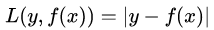
对应的负梯度误差为:
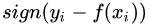
(3)Huber损失,它是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下:
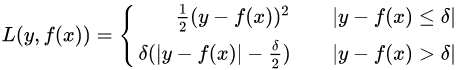
对应的负梯度误差为:
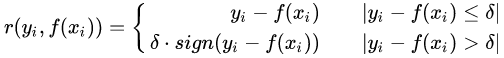
(4)分位数损失,它对应的是分位数回归的损失函数,表达式为:
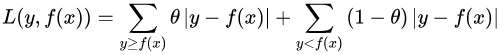
其中,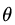 为分位数,需要我们在回归前指定。对应的负梯度误差为:
为分位数,需要我们在回归前指定。对应的负梯度误差为:
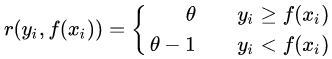
对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
5. GBDT的正则化
为了防止过拟合,GBDT主要有五种正则化的方式。
(1)“Shrinkage”:这是一种正则化(regularization)方法,为了防止过拟合,在每次对残差估计进行迭代时,不直接加上当前步所拟合的残差,而是乘以一个系数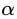 。系数
。系数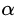 也被称为学习率(learning rate),因为它可以对梯度提升的步长进行调整,也就是它可以影响我们设置的回归树个数。对于前面的弱学习器的迭代:
也被称为学习率(learning rate),因为它可以对梯度提升的步长进行调整,也就是它可以影响我们设置的回归树个数。对于前面的弱学习器的迭代:
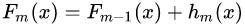
如果我们加上了正则化项,则有:
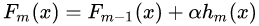
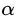 的取值范围为
的取值范围为 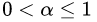 。对于同样的训练集学习效果,较小的
。对于同样的训练集学习效果,较小的 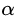 意味着我们需要更多的弱学习器的迭代次数。通常我们用学习率和迭代最大次数一起来决定算法的拟合效果。即参数learning_rate会强烈影响到参数n_estimators(即弱学习器个数)。learning_rate的值越小,就需要越多的弱学习器数来维持一个恒定的训练误差(training error)常量。经验上,推荐小一点的learning_rate会对测试误差(test error)更好。在实际调参中推荐将learning_rate设置为一个小的常数(e.g. learning_rate <= 0.1),并通过early stopping机制来选n_estimators。
意味着我们需要更多的弱学习器的迭代次数。通常我们用学习率和迭代最大次数一起来决定算法的拟合效果。即参数learning_rate会强烈影响到参数n_estimators(即弱学习器个数)。learning_rate的值越小,就需要越多的弱学习器数来维持一个恒定的训练误差(training error)常量。经验上,推荐小一点的learning_rate会对测试误差(test error)更好。在实际调参中推荐将learning_rate设置为一个小的常数(e.g. learning_rate <= 0.1),并通过early stopping机制来选n_estimators。
(2)“Subsample”:第二种正则化的方式是通过子采样比例(subsample),取值为 (0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但会增加样本拟合的偏差,因此取值不能太低。推荐在 [0.5, 0.8]之间。
使用了子采样的GBDT有时也称作随机梯度提升树 (Stochastic Gradient Boosting Tree, SGBT)。由于使用了子采样,程序可以通过采样分发到不同的任务去做Boosting的迭代过程,最后形成新树,从而减少弱学习器难以并行学习的弱点。
(3)对于弱学习器即CART回归树进行正则化剪枝。这一部分在学习决策树原理时应该掌握的,这里就不重复了。
(4)“Early Stopping”:Early Stopping是机器学习迭代式训练模型中很常见的防止过拟合技巧,具体的做法是选择一部分样本作为验证集,在迭代拟合训练集的过程中,如果模型在验证集里错误率不再下降,就停止训练,也就是说控制迭代的轮数(树的个数)。在sklearn的GBDT中可以设置参数n_iter_no_change实现early stopping。
(5)“Dropout”:Dropout是deep learning里很常用的正则化技巧,很自然的我们会想能不能把Dropout用到GBDT模型上呢?AISTATS2015有篇文章《DART: Dropouts meet Multiple Additive Regression Trees》进行了一些尝试。文中提到GBDT里会出现over-specialization的问题:前面迭代的树对预测值的贡献比较大,后面的树会集中预测一小部分样本的偏差。Shrinkage可以减轻over-specialization的问题,但不是很好。作者想通过Dropout来平衡所有树对预测的贡献。
具体的做法是:每次新加一棵树,这棵树要拟合的并不是之前全部树ensemble后的残差,而是随机抽取的一些树ensemble;同时新加的树结果要规范化一下。对这一部分感兴趣的同学可以阅读一下原论文。
6. 关于GBDT若干问题的思考
(1)GBDT与AdaBoost的区别与联系?
AdaBoost和GBDT都是重复选择一个表现一般的模型并且每次基于先前模型的表现进行调整。不同的是,AdaBoost是通过调整错分数据点的权重来改进模型,GBDT是通过计算负梯度来改进模型。因此,相比AdaBoost, GBDT可以使用更多种类的目标函数,而当目标函数是均方误差时,计算损失函数的负梯度值在当前模型的值即为残差。
(2)GBDT与随机森林(Random Forest,RF)的区别与联系?
相同点:都是由多棵树组成,最终的结果都是由多棵树一起决定。
不同点:1)集成的方式:随机森林属于Bagging思想,而GBDT是Boosting思想。2)偏差-方差权衡:RF不断的降低模型的方差,而GBDT不断的降低模型的偏差。3)训练样本方式:RF每次迭代的样本是从全部训练集中有放回抽样形成的,而GBDT每次使用全部样本。4)并行性:RF的树可以并行生成,而GBDT只能顺序生成(需要等上一棵树完全生成)。5)最终结果:RF最终是多棵树进行多数表决(回归问题是取平均),而GBDT是加权融合。6)数据敏感性:RF对异常值不敏感,而GBDT对异常值比较敏感。7)泛化能力:RF不易过拟合,而GBDT容易过拟合。
(3)我们知道残差=真实值-预测值,明明可以很方便的计算出来,为什么GBDT的残差要用负梯度来代替?为什么要引入麻烦的梯度?有什么用呢?
回答第一小问:在GBDT中,无论损失函数是什么形式,每个决策树拟合的都是负梯度。准确的说,不是用负梯度代替残差,而是当损失函数是均方损失时,负梯度刚好是残差,残差只是特例。
回答二、三小问:GBDT的求解过程就是梯度下降在函数空间中的优化过程。在函数空间中优化,每次得到增量函数,这个函数就是GBDT中一个个决策树,负梯度会拟合这个函数。要得到最终的GBDT模型,只需要把初始值或者初始的函数加上每次的增量即可。我这里高度概括的回答了这个问题,详细推理过程可以参考:梯度提升(Gradient Boosting)算法,地址:https://mp.weixin.qq.com/s/Ods1PHhYyjkRA8bS16OfCg
7. 总结
在本文中,我们首先引出回归树与梯度提升算法结合的优势;然后详细推导了GBDT回归算法的原理,并用实际案例解释GBDT回归算法;其次不仅用Python3实现GBDT回归算法,还用sklearn实现GBDT回归算法;最后,介绍了GBDT回归任务常见的损失函数、GBDT的正则化和我对GBDT回归算法若干问题的思考。GBDT中的树是回归树(不是分类树),GBDT可以用来做回归预测,这也是我们本文讲的GBDT回归算法,但是GBDT调整后也可以用于分类任务。让我们期待一下GBDT分类算法,在分类任务中的表现吧!
8. Reference
由于参考的文献较多,我把每一部分都重点参考了哪些文章详细标注一下。
GBDT简介与GBDT回归算法:
【1】Friedman J H . Greedy Function Approximation: A Gradient Boosting Machine[J]. The Annals of Statistics, 2001, 29(5):1189-1232.
【2】Friedman, Jerome & Hastie, Trevor & Tibshirani, Robert. (2000). Additive Logistic Regression: A Statistical View of Boosting. The Annals of Statistics. 28. 337-407. 10.1214/aos/1016218223.
【3】机器学习-一文理解GBDT的原理-20171001 - 谋杀电视机的文章 - 知乎 https://zhuanlan.zhihu.com/p/29765582
【4】GBDT算法原理深入解析,地址:https://www.zybuluo.com/yxd/note/611571
【5】GBDT的原理和应用 - 文西的文章 - 知乎 https://zhuanlan.zhihu.com/p/30339807
【6】ID3、C4.5、CART、随机森林、bagging、boosting、Adaboost、GBDT、xgboost算法总结 - yuyuqi的文章 - 知乎 https://zhuanlan.zhihu.com/p/34534004
【7】GBDT:梯度提升决策树,地址:https://www.jianshu.com/p/005a4e6ac775
【8】机器学习算法中 GBDT 和 XGBOOST 的区别有哪些?- wepon的回答 - 知乎 https://www.zhihu.com/question/41354392/answer/98658997
【9】http://wepon.me/files/gbdt.pdf
【10】GBDT详细讲解&常考面试题要点,地址:https://mp.weixin.qq.com/s/M2PwsrAnI1S9SxSB1guHdg
【11】Gradient Boosting Decision Tree,地址:http://gitlinux.net/2019-06-11-gbdt-gradient-boosting-decision-tree/
【12】《推荐系统开发实战》之基于点击率预估的推荐算法介绍和案例开发实战,地址:https://mp.weixin.qq.com/s/2VATflDlelfxhOQkcXHSqw
【13】GBDT算法原理以及实例理解,地址:https://blog.csdn.net/zpalyq110/article/details/79527653
手撕GBDT回归算法:
【14】GBDT_Simple_Tutorial(梯度提升树简易教程),GitHub地址:https://github.com/Freemanzxp/GBDT_Simple_Tutorial
【15】SCIKIT-LEARN与GBDT使用案例,地址:https://blog.csdn.net/superzrx/article/details/47073847
【16】手写原始gbdt,地址:https://zhuanlan.zhihu.com/p/82406112?utm_source=wechat_session&utm_medium=social&utm_oi=743812915018104832
GBDT回归任务常见的损失函数与正则化:
【17】Regularization on GBDT,地址:http://chuan92.com/2016/04/11/regularization-on-gbdt
【18】Early stopping of Gradient Boosting,地址:https://scikit-learn.org/stable/auto_examples/ensemble/plot_gradient_boosting_early_stopping.html
【19】Rashmi K V, Gilad-Bachrach R. DART: Dropouts meet Multiple Additive Regression Trees[C]//AISTATS. 2015: 489-497.
关于GBDT若干问题的思考:
【20】关于adaboost、GBDT、xgboost之间的区别与联系,地址:https://blog.csdn.net/HHTNAN/article/details/80894247
【21】[校招-基础算法]GBDT/XGBoost常见问题 - Jack Stark的文章 - 知乎 https://zhuanlan.zhihu.com/p/81368182
【22】gbdt的残差为什么用负梯度代替?- 知乎 https://www.zhihu.com/question/63560633
【23】gbdt的残差为什么用负梯度代替?- 奥奥奥奥噢利的回答 - 知乎 https://www.zhihu.com/question/63560633/answer/581670747
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)