Yolov5的3种tensorRT加速方式及3090测评结果(C++版和Python torchtrt版)
本文中,我想测评下tensorRT,看看它在不同方式下的加速效果。用Tensorrt加速有两种思路,一种是构建C++版本的代码,生成engine,然后用C++的TensorRT加速。另一种是用Python版本的加速,Python加速有两种方式,网络上基本上所有的方法都是用了C++生成的engine做后端,只用C++来做前端,这里我提供了另外一个用torchtrt加速的版本。一、安装Tensorrt
本文中,我想测评下tensorRT,看看它在不同方式下的加速效果。
用Tensorrt加速有两种思路,一种是构建C++版本的代码,生成engine,然后用C++的TensorRT加速。另一种是用Python版本的加速,Python加速有两种方式,网上基本上所有的方法都是用了C++生成的engine做后端,只用Python来做前端,这里我提供了另外一个用torchtrt加速的版本。
一、安装Tensorrt参考教程
所有工程前最苦恼的问题,配置环境。。以下是我参考的连接。
1、安装可以通过tar或者deb安装
https://blog.csdn.net/qq_33047753/article/details/101604686
2、安装后用lenet验证是否安装成功
https://github.com/wang-xinyu/tensorrtx/blob/master/tutorials/getting_started.md
二、Tensorrt加速yolov5参考教程
1、C++版本
参考连接:https://blog.csdn.net/weixin_41868104/article/details/114937498?spm=1001.2014.3001.5501
要安装下opencv,配置环境比较烦,配置了好几次,后来发现环境没有成功是需要重启!!!
sudo那两个命令有问题,可以用以下github中的连接实现。
https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
即(以yolov5s为例):
sudo ./yolov5 -s yolov5s.wts yolov5s.engine s
sudo ./yolov5 -d yolov5s.engine ../images
自测加速效果如下(RTX3090):
测试图片为MOT17_01前10张图片(输入为640x640),第一项为单张图片推理时间(不包含数据的预处理和NMS或者其他的后处理时间),第二项为GPU中所占用的显存。
| yolov5s | yolov5m | yolov5l | yolov5x | |
|---|---|---|---|---|
| 未加速(FP32/FP16) | 13.6ms/1767M | 14.9ms/1871M | 18.2ms/2119M | 22.8ms/2481M |
| TensorRT加速(FP32) | 2.2ms/1295M | 5ms/1379M | 9ms/1517M | 14ms/1783M |
| TensorRT加速(FP16) | 1.2ms/1049M | 2.1ms/1109M | 3.1ms/1223M | 4.2ms/1385M |
| TensorRT加速(INT8) | 1.1ms/1029M | 2.1ms/1063M | 3.1ms/1117M | 4.1ms/1203M |
⭐在使用INT8模型之前需要做一些校准(calibration),位数太少了,校准可以保证尽可能保证分布,但是校准对校准的数据集要求比较高,如果选取不好很难保证泛化性。
校准方法:https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
校准原理:https://arleyzhang.github.io/articles/923e2c40/

速度的增加和内存的减少还是挺可观的,FP16和FP32相对于原来的方法有很大的显存下降和推理速度的提高。而且从可视化来看基本上没有太大的差别。但是INT8就差上很多了,基本上丢失了很多的目标。一开始怀疑是校准没有弄好,但是用了三种方法(github给出的COCO校准/MOT同一个序列的100张图片/直接用测试的那10张图片),效果均差不多,这可能说明校准真的是个技术活。。INT8不咋丢失精度可能在检测上还比较难搞。
2、Python版本
Python加速这里介绍两种方法。
第一种依然来自于github:https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5

这个实际上和之前的没有改变啥好像,就是依然需要写C++的后端才行,只是把后处理这些放到python中了,依然不利于python的直接部署。这种方法加速后的效果和之前的C++的没有太大的区别。
第二种网上没有提供,是基于torchtrt的,这里也提供它的教程和测评结果。
1、根据下列github安装好torchtrt,把demo跑通,保证安装成功。
https://github.com/NVIDIA-AI-IOT/torch2trt
测试代码如下:
import torch
from torch2trt import torch2trt
from torchvision.models.alexnet import alexnet
import time
# create some regular pytorch model...
model = alexnet(pretrained=True).eval().cuda()
# create example data
x = torch.ones((1, 3, 224, 224)).cuda()
# convert to TensorRT feeding sample data as input
model_trt = torch2trt(model, [x])
t0 = time.time()
y = model(x)
t1 = time.time()
y_trt = model_trt(x)
t2 = time.time()
print(t2-t1,t1-t0)
# check the output against PyTorch
print(torch.max(torch.abs(y - y_trt)))
用这个方法来加速模型看起来很简单,只需要用torch2trt对模型进行转换就可以了,但是实际操作下来还是要debug一堆东西。
问题一: 这个库不支持多输出(网上据说可以改,但是我还没找到,有大佬懂得麻烦指点一下),所以需要把很多计算从模型中拿出来在外面算。
问题二: 自定义的tensor或者list都没有_trt这个属性,这个很坑,也要把这部分拿出来外面算。
Debug了好久,终于解决了问题,先把yolov5的工程(https://github.com/ultralytics/yolov5)下下来跑通,然后修改如下:
1) 修改模型(models/yolo.py)
修改里面的Detect的forward,把不能加速的拿出来,修改前如图:
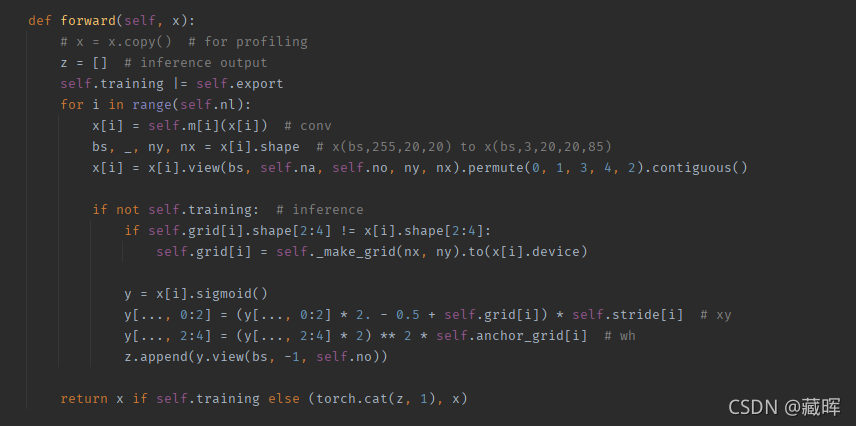
修改后如图:
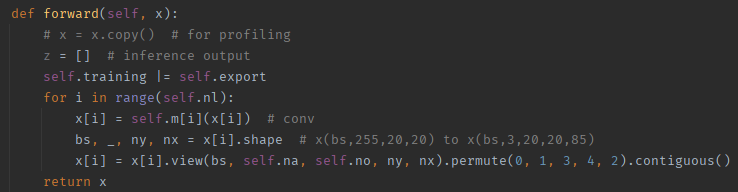
2) 修改Demo(detect.py)
先引入需要的库和之前引出来的代码写成函数备用,有很多懒得从网络读了比如stride,就直接定义了。
from torch2trt import torch2trt
import yaml
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
def translate_to_pred(x,anchor):
z = []
stride = [8,16,32]
for i in range(len(x)):
bs, na, ny, nx, no = x[i].shape
grid = _make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + grid) * stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * anchor[i] # wh
z.append(y.view(bs, -1, no))
return torch.cat(z, 1)
在进入处理之前读取下anchor和设置下状态变量
# for tensorRT
set_model = 1 #为了在第一张图片完成模型转换,后面就不处理了。
with open("models/hub/anchors.yaml") as f:
yaml_inf = yaml.load(f, Loader=yaml.SafeLoader)
anchors = torch.tensor(yaml_inf["anchors_p5_640"]).float().view(3, 1, -1, 1, 1, 2).cuda()
# for path, img, im0s, vid_cap in dataset: 加在这一句之前
最后一步修改,修改模型推理
# pred = model(img, augment=opt.augment)[0] 注释掉这一句,加上如下code
if set_model == 1:
model_trt = torch2trt(model, [img])
set_model = 0
pred = model_trt(img)
pred = translate_to_pred(pred,anchors)
这基本就完成了,但是还发现了一些小的bug,比如在NMS步骤会报错

这个是index超维度了,如果报这个错误直接在报错前加个tolist():
# 我报错是这个
output[xi] = x[i]
# 修改为
i = i.tolist()
output[xi] = x[i]
Python版本自测加速效果如下(RTX3090):
测试图片为MOT17_01前10张图片(输入为640x640),指标为单张图片推理时间(不包含数据的预处理和NMS或者其他的后处理时间),因为这次要加载之前的模型,显存占用量不大准确就不做参考了。
| yolov5s | yolov5m | yolov5l | yolov5x | |
|---|---|---|---|---|
| 未加速 | 13.6ms | 14.9ms | 18.2ms | 22.8ms |
| TensorRT加速 | 5.9ms | 6.8ms | 10.1ms | 17.1ms |
⭐基本上也可以提速很多,相比于C++版本的提高较弱,但是比较好的地方是不需要自己会写C的yolov5工程,在原来的模型上就可以很快完成修改。但是限制也很多,很多自定义的网络或者变量不一定可以直接加速。。
三、关于Tensorrt加速自己的工作
上述已经提供了两种TensorRT加速的思路,都可以起到很好的加速效果。
C++的加速效果更好,但是涉及到要会用C++把自己的工作写一遍才行,现在开源出来包括网上很多方法都是用C++来加速的,这个方法更加灵活,适应性更强(多输入多输出之类),而且最终只会生成一个engine,看起来很简洁。
这部分如果有C++基础的真的强烈推荐,可以参考如下工程:
yolov5:https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
yoloX:https://github.com/Megvii-BaseDetection/YOLOX
不会C++可以考虑用Torchtrt来加速,上述就提供了一个加速yolov5的例子,当然需要把一些加速不了的东西拿出来。此外,这个方法遇到多输入多输出也可以用一些折中的方法进行加速,比如把可以加速的部分划分成多个模型加速,加速不了的用原来的方法计算,这样依然可以获得很高的速度收益。
这类方法简单有效,适合不精通C++但需要加速的人群,可以参考如下工程:
yoloX:https://github.com/Megvii-BaseDetection/YOLOX
Ocean:https://github.com/researchmm/TracKit/blob/master/lib/tutorial/Ocean/ocean.md

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)