python数据预处理—数据清洗、数据集成、数据变换、数据归约
进行数据分析时,需要预先把进入模型算法的数据进行数据预处理。一般我们接收到的数据很多都是“脏数据”,里面可能包含缺失值、异常值、重复值等;同时有效标签或者特征需要进一步筛选,得到有效数据,最终把原始数据处理成符合相关模型算法的输入标准,从而进行数据分析与预测。
进行数据分析时,需要预先把进入模型算法的数据进行数据预处理。一般我们接收到的数据很多都是“脏数据”,里面可能包含缺失值、异常值、重复值等;同时有效标签或者特征需要进一步筛选,得到有效数据,最终把原始数据处理成符合相关模型算法的输入标准,从而进行数据分析与预测。下面将介绍数据预处理中的四个基本处理步骤:
目录
一、数据清洗
数据清洗主要将原始数据中的缺失值、异常值、重复值进行处理,使得数据开始变得“干净”起来。
1.缺失值
1.1缺失值可视化
运用python中的missingno库,此库需要下载导入
#提前进行这一步:pip install missingno
#导入相关库
import missingno as msno
import pandas as pd
import numpy as np可视化方法一:无效矩阵的数据密集显示
#读取文件
df=pd.read_csv('C:/Users/27812/Desktop/1-Advertising.csv')
#缺失值的无效矩阵的数据密集显示
fig1=msno.matrix(df,labels=True)
b=fig1.get_figure()
b.savefig('C:/Users/27812/Desktop/a.png',pdi=500)#保存图片
注意:其中白色的横条表示为缺失值,黑色部分表示有值的部分
可视化方法二:运用列的无效简单可视化
#缺失值的条形图显示
fig2=msno.bar(df)
b=fig2.get_figure()
b.savefig('C:/Users/27812/Desktop/b.png',pdi=500)#保存图片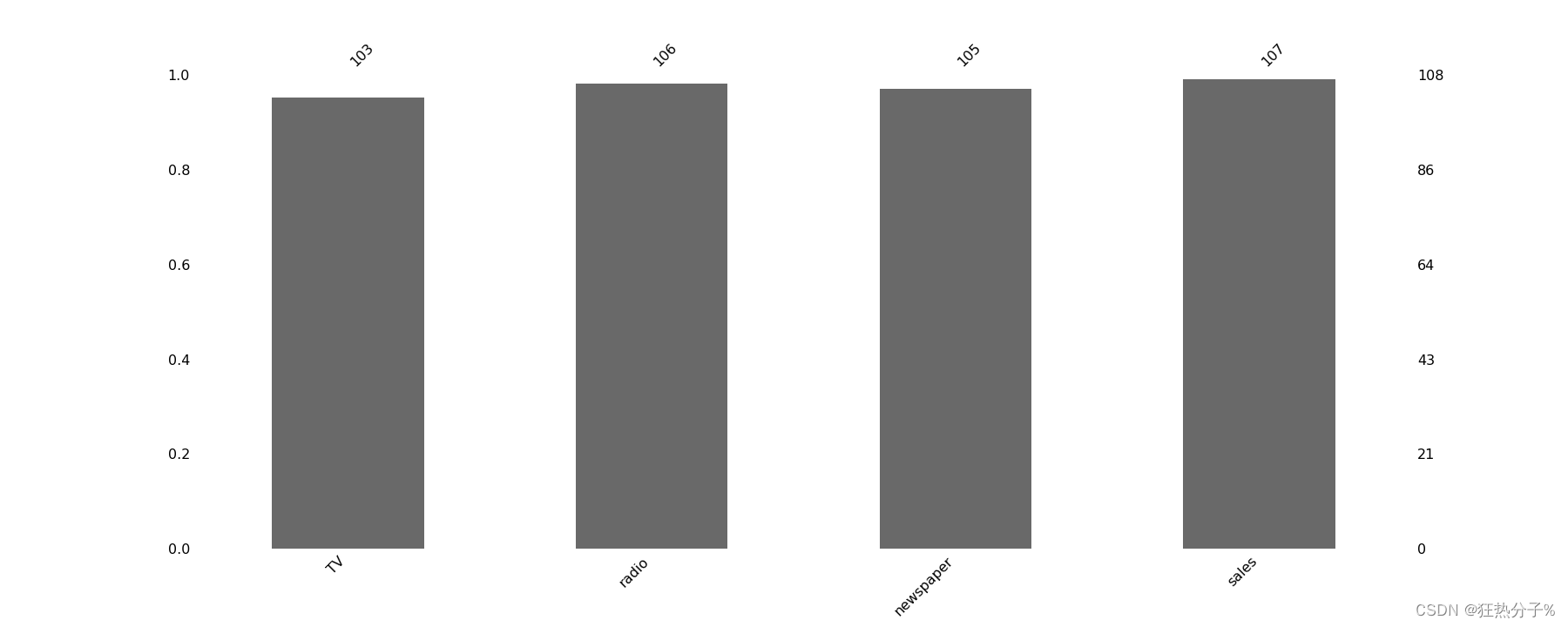
1.2缺失值处理
方法一:当缺失率少且重要度较高时,运用pandas里面的fillna函数进行填充。
方法二:当缺失率高且重要度较低时,可以运用pandas里面的dropna函数直接进行删除。
方法三:当缺失率高且重要度高时,运用插补法或建模法。其中插补法有:随机插补法、多重插补法、热平台插补、拉格朗日插值法、牛顿插值法等;建模法:利用回归、贝叶斯、决策树等模型对缺失数据进行预测。
2.异常值
异常值的来源主要分为人为误差和自然误差,例如:数据输入错误、测量误差、故意异常值、抽样错误、自然异常值、数据处理错误等等。
2.1异常值可视化
主要运用python里面的seaborn库绘制箱线图,查看异常值,如何绘制请详看上期文章
2.2异常值识别
方法一:Z-score方法
# 通过Z-Score方法判断异常值,阙值设置为正负2
# 复制一个用来存储Z-score得分的数据框,常用于原始对象和复制对象同时进行操作的场景
df_zscore = df.copy()
for col in all_colums:
df_col = df[col]
z_score = (df_col - df_col.mean()) / df_col.std() # 计算每列的Z-score得分
df_zscore[col] = z_score.abs() > 2 # 判断Z-score得分绝对值是否大于2,大于2即为异常值
print(df_zscore)#显示为True的表示为异常值
# 剔除异常值所在的行
print(df[df_zscore['列名一'] == False])
print(df[df_zscore['列名二'] == False])
print(df[df_zscore['列名三'] == False])方法二:基于正态分布的离群点检测(3原则)
#查看是否服从正态分布
# pvalue大于0.05则认为数据呈正态分布
from scipy import stats
mean = df['列名一'].mean()
std = df['列名一'].std()
print(stats.kstest(df['列名一'],'norm',(mean,std)))
# 选取小于3个标准差的数据
df = df[np.abs(df['列名一']- mean) <= 3*std]
#若不成正态分布,用远离平均值的多少倍标准差来筛选异常值
# 定义远离平均值4倍标准差为异常值
a = mean + std*4
b = mean - std*4
df = df[(df['Age'] <= a) & (df['Age'] >= b)]方法三:箱线图分析(四分位法)
# 算出上界和下届
q1 = df["列名一"].quantile(0.25)
q3 = df["列名一"].quantile(0.75)
iqr = q3 - q1
bottom = q1 - 1.5*iqr
upper = q3 + 1.5*iqr
# 去除异常值
df[(df['列名一'] >= bottom) & (df['列名一'] <= upper)]方法四:简单统计分析
主要是运用pandas里面的describe函数进行查看
#读取文件
df=pd.read_csv('C:/Users/27812/Desktop/1-Advertising.csv')
print(df.describe())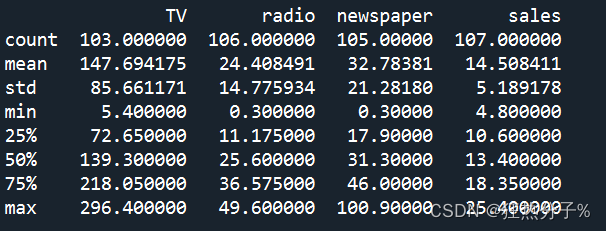
2.3异常值处理
方法一:当异常值较少时,可删除
方法二:不处理(看算法是否对异常值敏感)
方法三:用平均值代替
方法四:视为缺失值,以处理缺失值的方法进行处理
3.重复值
3.1重复值处理
运用pandas里面的duplicated函数去重
#查看是否有重复值
print(df[columns].nunique())
#检测重复值
print(df.duplicated())#出现为TRUE的则是重复值
#提取重复值
print(df[df.duplicated()])
#如果有重复值,则用df.drop_duplicated()方法去重二、数据集成
数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。
利用pandas合并数据:
1.运用merge函数合并数据
import pandas as pd
symble=pd.DataFrame({'cat':['a','b','c','d'],'color':['red','yellow','blue','black']})
age=pd.DataFrame({'cat':['a','b','c','d'],'age':[2,4,6,8]})
print(pd.merge(symble, age))
'''结果如下
cat color age
0 a red 2
1 b yellow 4
2 c blue 6
3 d black 8
'''2.运用concat函数进行数据连接
import pandas as pd
symble=pd.DataFrame({'cat':['a','b','c','d'],'color':['red','yellow','blue','black']})
age=pd.DataFrame({'cat':['a','b','c','d'],'age':[2,4,6,8]})
print(pd.concat([symble,age],axis=0))
'''结果如下
cat color age
0 a red NaN
1 b yellow NaN
2 c blue NaN
3 d black NaN
0 a NaN 2.0
1 b NaN 4.0
2 c NaN 6.0
3 d NaN 8.0
'''3.运用combine_first函数合并数据
此函数需要合并的两个DataFrame存在重复索引
import pandas as pd
symble=pd.DataFrame({'cat':['a','b','c','d'],'color':['red','yellow','blue','black']})
age=pd.DataFrame({'cat':['a','b','c','d'],'age':[2,4,6,8]})
print(symble.combine_first(age))
'''结果如下
age cat color
0 2 a red
1 4 b yellow
2 6 c blue
3 8 d black
'''三、数据变换
数据变换即对数据进行规范化处理,以便后续的信息挖掘。常见的数据变换有:特征归一化、特征二值化、连续特征变换、定性特征哑编码等。
python的sklearn库中的Preprocessing(预处理)模块,几乎包含数据预处理的所有内容。
1.特征归一化
特征归一化也叫数据无量纲化,主要包括:总和标准化、标准差标准化、极大值标准化、极差标准化。注意:基于树的方法是不需要进行特征归一化的,例如GBDT、bagging、boosting等,而基于参数的模型或基于距离的模型,则都需要进行特征归一化。
1.1总和标准化
总和标准化处理后的数据介于(0,1)之间,并且它们的和为1。总和标准化的步骤和公式也非常简单:分别求出各聚类要素所定义的数据的总和,以各要素的数据除以该要素的数据总和。
1.2标准差标准化
标准差标准化处理后所得到的新数据,各要素(指标)的平均值为0,标准差或方差为1。
from sklearn import preprocessing
x_scale=preprocessing.scale(df)1.3极大值标准化
极大化标准化后的新数据,各要素的最大值为1,其余各项都小于1。(为稀疏矩阵数据设计)
1.4极差标准化(区间放缩法、0-1标准化、最值归一化)
经过极差标准化处理后的新数据,各要素的极大值为1,极小值为0,其余值均在0到1之间。如果数据中有离群点,对数据进行均值和方差的标准化效果并不好,这时候可以使用robust_scale和RobustScaler作为代替,它们有对数据中心化和数据的缩放鲁棒性更强的参数。
from sklearn import preprocessing
min_max_scaler=preprocessing.MinMaxScaler()
x_minmax=min_max_scaler.fit_transform(df)#极差标准化
#对后面测试数据进行训练
x_test_minmax=min_max_scaler.transform(df_test)2.特征二值化
特征二值化的核心在于设定一个阈值,将特征与该阈值进行比较后,转换为0或1,它的目的是将连续数值细颗粒度的度量转换为粗粒度的度量。
from sklearn.preprocessing import Binarizer
Binarizer=Binarizer(threshold=20).fit_transform(df)#阈值设置视情况而定3.连续特征变换
连续特征变换的常用方法有三种:基于多项式的数据变换、基于指数函数的数据变换、基于对数函数的数据变换。连续特征变换能够增加数据的非线性特征捕获特征之间的关系,有效提高模型的复杂度。
4.定性特征哑编码:One-hot编码
one-hot编码又称为独热编码,即一位代表一种状态,及其信息中,对于离散特征,有多少个状态就有多少个位,且只有该状态所在位为1,其他位都为0。
from sklearn.preprocessing import OneHotEncoder
enc=OneHotEncoder().fit_transform(df['列名'])四、数据归约(特征选择)
数据归约指在尽可能保持数据原貌的前提下,最大限度地精简数据量。数据归约主要有两个途径:属性选择和数据采样,分别针对原始数据集中的属性和记录。
数据归约的策略:
1.数据立方体聚集:聚集操作用于数据集中的数据。
2.维归约:可以检测并删除不相关、弱相关或冗余的属性或维度。
3.数据压缩:使用编码机制压缩数据集。
4.数值归约:用替代的、较小的数据表示代替或估计数据,如参数模型(只需要存放校型参数,而不是实际数据)或非参数方法,如聚类、选样和使用直方图。
5.离散化和概念分层生产:属性的原始值用区间值或较高层的概念替换,概念分层允许挖掘多个抽象层上的数据,是数据挖掘的一种强有力的工具。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 2
2- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)