多尺度动态图卷积神经网络----Multi-scale Dynamic Graph Convolutional Network for Hyperspectral Image Classificati
一、摘要卷积神经网络(CNN)在表示高光谱图像和实现高光谱图像分类方面表现出令人印象深刻的能力。然而,传统的CNN模型只能对固定大小和权重的规则正方形图像区域进行卷积,因此不能普遍适用于具有不同对象分布和几何外观的不同局部区域。因此,它们的分类性能仍有待提高,尤其是在类边界方面。为了缓解这一缺点,我们考虑采用最近提出的图卷积网络(GCN)进行高光谱图像分类,因为它可以对任意结构的非欧几里德数据进行
一、摘要
卷积神经网络(CNN)在表示高光谱图像和实现高光谱图像分类方面表现出令人印象深刻的能力。然而,传统的CNN模型只能对固定大小和权重的规则正方形图像区域进行卷积,因此不能普遍适用于具有不同对象分布和几何外观的不同局部区域。因此,它们的分类性能仍有待提高,尤其是在类边界方面。为了缓解这一缺点,我们考虑采用最近提出的图卷积网络(GCN)进行高光谱图像分类,因为它可以对任意结构的非欧几里德数据进行卷积,并且适用于由图拓扑信息表示的不规则图像区域。与常用的GCN模型工作在固定图上不同,我们使图能够随着图卷积过程动态更新,从而使这两个步骤相互受益,逐渐产生有区别的嵌入特征以及细化的图。此外,为了综合利用高光谱图像继承的多尺度信息,我们建立了具有不同邻域尺度的多输入图,以广泛利用多尺度上的多样光谱空间相关性。因此,我们的方法被称为“多尺度动态图卷积网络”(MDGCN)。在三个典型基准数据集上的实验结果有力地证明了所提出的MDGCN在定性和定量方面优于其他最先进的方法。
二、创新点
1、提出了一种新的动态图卷积运算,它可以减少不良预定义图的影响。
2、利用多尺度图卷积来广泛利用空间信息,获得更好的特征表示。
3、在提出的MDGCN框架中引入了超像素技术,大大降低了模型训练的复杂性。
三、模型结构

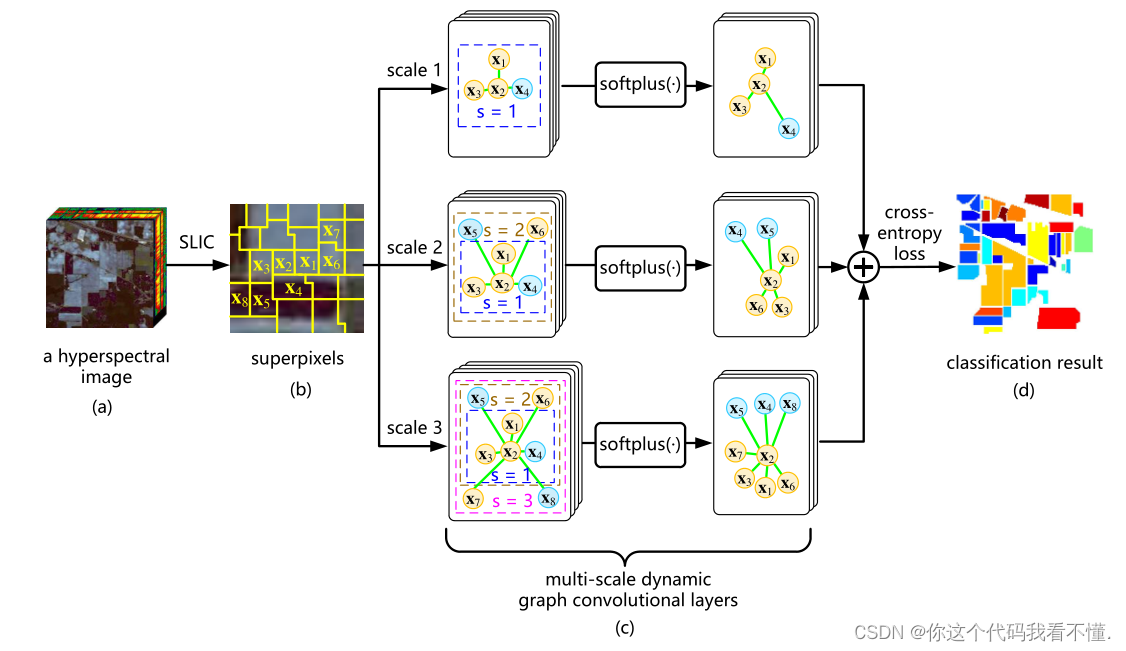
圆圈和绿线分别代表图形节点和边,其中节点的不同颜色代表不同的土地覆盖类型。具体地说,在每个尺度上,边权重随着图节点上的卷积而逐渐更新,从而可以动态地细化图。这里,每个标度使用两个动态图卷积层,其中softplus被用作激活函数。在(d)中,通过对多尺度输出进行积分获得分类结果,并使用交叉熵损失惩罚输出和种子超像素之间的标签差异。
其实模型的结构比较容易理解,在降维之后,文章采用SLIC无监督分割算法对图像进行分割,这个分割的区域数量是可以自己确定的,也是超像素图卷积神经网络需要调参的一个点。还有一些分割算法可以参考如下:
[1] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P . Fua, and S. Süsstrunk,“SLIC superpixels compared to state-of-the-art superpixel methods,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 11, pp. 2274–2282,Nov. 2012.
[2] A. V edaldi and S. Soatto, “Quick shift and kernel methods for mode seeking,” in Proc. Eur. Conf. Comput. Vis. (ECCV). Berlin, Germany: Springer, 2008, pp. 705–718.
[3] P. F. Felzenszwalb and D. P. Huttenlocher, “Efficient graph-based image segmentation,” Int. J. Comput. Vis., vol. 59, no. 2, pp. 167–181, Sep. 2004.
[4] Z. Li and J. Chen, “Superpixel segmentation using linear spectral clustering,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 1356–1363.
[5] M. V an den Bergh, X. Boix, G. Roig, and L. V an Gool, “SEEDS: Superpixels extracted via energy-driven sampling,” Int. J. Comput. Vis., vol. 111, no. 3, pp. 298–314, Feb. 2015.
分割完之后,使用超像素作为图的节点参与训练,可能很多人不清楚超像素如何做图节点的,可以看下下面这篇文章中的图。这篇文章的名字是:CNN-Enhanced Graph Convolutional Network With Pixel- and Superpixel-Level Feature Fusion for Hyperspectral Image Classification
看上图的构造,首先将整个像素构造一个矩阵,多个像素对应一个超像素区域,这样可以将矩阵区域选择出来作为输入,具体操作可以查看代码,代码在GitHub上面搜论文可以搜到。至于超像素的标签,有两种方法可以确定,第一个是取超像素中心像素的标签,第二个是后面随机选取训练样本的时候,训练样本在哪个超像素里,这个超像素就是哪个标签。
图的构造说完了,说下多尺度和动态的含义。可以看下下面这幅图的解释。

文章也验证了多尺度与动态的作用,结果图如下

前面三个是动态更替的次数,第四个是加上多尺度。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)