关于python数据处理dataframe中列里面str转化为可识别int、float类别
关于python数据处理dataframe中列里面str转化为可识别int、float类别
·
描述问题
当我们在机器学习中做tree模型或者逻辑回归分类问题或者其他模型时,输入的特征值为不可判别str种类,此时需要将特征值转化为可识别int或者float种类,
例如在原始数据中可以看到如下图:

在Mfg这一列,分别是雪佛兰,别克,奥迪等汽车品牌,做一个特征值输入,但是这类字符串在模型构建过程中不能被识别,那么现在就需要对这一列进行处理,那考虑到之后的数据可能也会出现类似情况,那么我们将处理函数做成一个类似插件的函数模式,
function convent_columns(X, list_name)
#将不可处理的列中的str转换成int
y = names(X)#读取列名
X = Array(X)#将Julia格式的dataframe转化为array格式
py"""
import pandas as pd
def lasso_my (X, y, list_name):
X = pd.DataFrame(X)#将array转化为python格式的dataframe
data1 = X.dropna()#处理缺失值
data1 = data1.copy()#这一行是后面补上的,涉及到深浅拷贝的问题,不加会有警告
for i in range(len(y)):
data1.rename(columns={i: y[i]}, inplace=True)#对列名赋值
df1 = data1[list_name]
liit_key = list(set(df1.values))
list_val = list(range(len(liit_key)))
dic = dict(zip(liit_key,list_val))#将我们需要处理的列处理成字典,
column = []
for i in range(len(df1.values)):
for k in dic.keys():
if df1.values[i] == k:
column.append(dic[k])
data1[list_name] = column#拿到新的列
return data1.iloc[:,:-1], data1.iloc[:,-1], dic
"""
return py"lasso_my"(X, y, list_name)
end上面的代码段是julia来调用python函数,因为我输入是julia格式的dataframe,如果是python环境可以直接取中间代码即可,
我们现在看一下处理之后的数据,
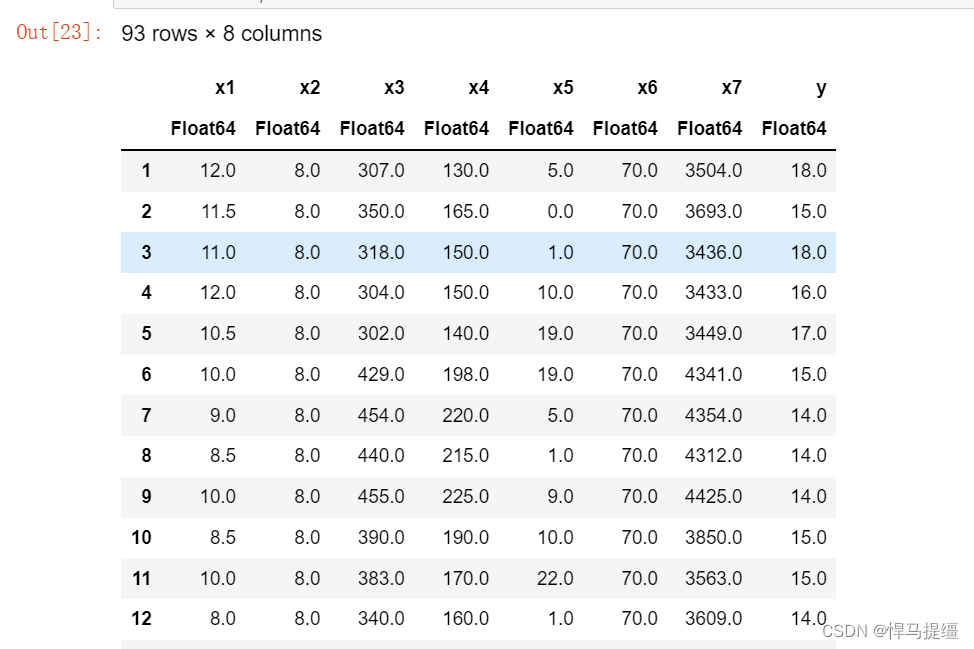
可以看到我们模型识别不了的字符串类型已经转化成int,
我们也可以取出字典来了解对应的汽车品牌,如下图

到这里本期分享就结束了,
记录自己第一次发布文章,2022.11.2_悍马提缰

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)