arcface的前世今生
ArcFace/InsightFace(弧度)是伦敦帝国理工学院邓建康等在2018.01发表,在SphereFace基础上改进了对特征向量归一化和加性角度间隔,提高了类间可分性同时加强类内紧度和类间差异。论文链接:ArcFace: Additive Angular Margin Loss for Deep Face RecognitionLFW上99.83%,YTF上98.02%作为基于 soft
arcface调研
1.简介
1.1发表
ArcFace/InsightFace(弧度)是伦敦帝国理工学院邓建康等在2018.01发表,在SphereFace基础上改进了对特征向量归一化和加性角度间隔,提高了类间可分性同时加强类内紧度和类间差异。
论文链接:ArcFace: Additive Angular Margin Loss for Deep Face Recognition
1.2优点
- ArcFace loss:Additive Angular Margin Loss(加性角度间隔损失函数),对特征向量和权重归一化,对θ加上角度间隔m,角度间隔比余弦间隔在对角度的影响更加直接。几何上有恒定的线性角度margen。
- ArcFace中是直接在角度空间θ中最大化分类界限,而CosFace是在余弦空间cos(θ)中最大化分类界限。
1.3性能
LFW上99.83%,YTF上98.02%
2.arcface的前世今生
作为基于 softmax 改进的损失函数,arcface loss 的出现不是一簇而就的,在 arcface loss 之前有大量的前人的工作:
center loss,L-softmax loss,A-softmax loss,CosFace loss 等
2.1 softmax
公式:
L
1
=
−
1
N
∑
i
=
1
N
l
o
g
e
W
y
i
T
x
i
+
b
y
i
∑
j
=
1
N
W
y
i
T
x
i
+
b
y
i
L_{1} = - \frac{1}{N} \sum_{i=1}^{N} {log \frac{e^{W^{T}_{y_{i}} x_{i} + b_{y_{i}}}} {\sum_{j=1}^{N}{W^{T}_{y_{i}} x_{i} + b_{y_{i}}}}}
L1=−N1i=1∑Nlog∑j=1NWyiTxi+byieWyiTxi+byi
2.2center loss
论文:[ECCV 2016] A Discriminative Feature Learning Approach for Deep Face Recognition
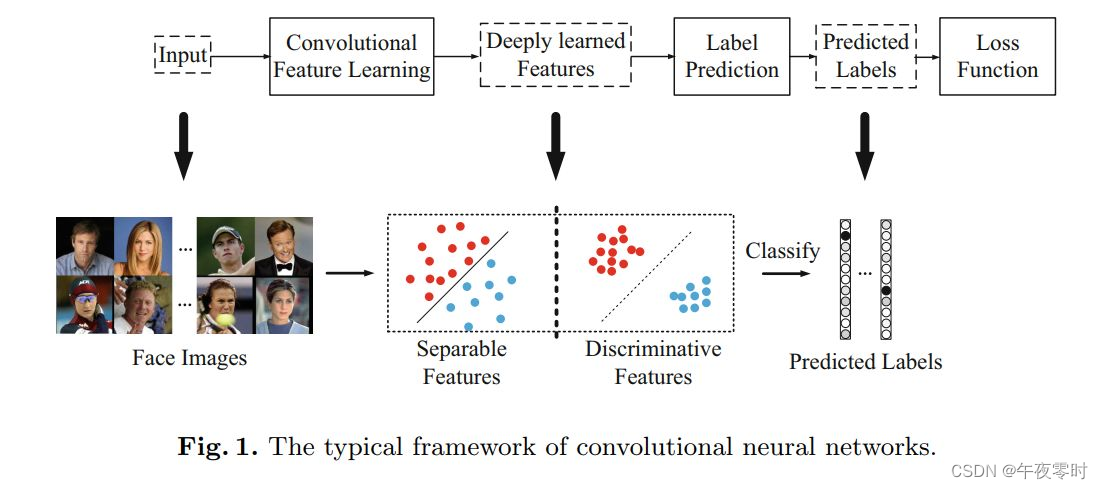
ECCV 2016的这篇文章主要是提出了一个新的Loss:Center Loss,用以辅助Softmax Loss进行人脸的训练,主要目的是利用softmax loss来分开不同类别,利用center loss来压缩同一类别,最终获取discriminative features。
其原理是增加惩罚项,约束每一类向中心聚集
公式:
L
1
=
−
1
N
∑
i
=
1
N
l
o
g
e
W
y
i
T
x
i
+
b
y
i
∑
j
=
1
N
W
y
i
T
x
i
+
b
y
i
+
λ
2
∑
i
=
1
N
∣
∣
x
i
−
c
y
i
∣
∣
2
L_{1} = - \frac{1}{N} \sum_{i=1}^{N} {log \frac{e^{W^{T}_{y_{i}} x_{i} + b_{y_{i}}}} {\sum_{j=1}^{N}{W^{T}_{y_{i}} x_{i} + b_{y_{i}}}}} + \frac{\lambda}{2} \sum_{i=1}^{N} {\mid\mid x_{i} - cy_{i} \mid\mid ^{2}}
L1=−N1i=1∑Nlog∑j=1NWyiTxi+byieWyiTxi+byi+2λi=1∑N∣∣xi−cyi∣∣2
其中: y i y_{i} yi 代表第 i 类的中心。 y i y_{i} yi的求解过程相对复杂。
在训练的初始, y i y_{i} yi由Xavier初始化,即刚开始并不指向类中心,然后每个iterator更新一次 y i y_{i} yi。
其更新方式类似于反向传播。
通过对
x
i
−
c
y
i
x_{i} - cy_{i}
xi−cyi求导,得到下述表达式:
Δ
c
y
i
=
∑
i
=
1
N
δ
(
y
i
=
j
)
(
c
j
−
x
i
)
1
+
∑
i
=
1
N
δ
(
y
i
=
j
)
\Delta cy_{i} = \frac{\sum_{i=1}^{N} {\delta (y_{i=j})(c_{j} - x_{i}) } } {1 + \sum_{i=1} ^{N} {\delta(y_{i=j})} }
Δcyi=1+∑i=1Nδ(yi=j)∑i=1Nδ(yi=j)(cj−xi)
按导数值
Δ
c
y
i
\Delta cy_{i}
Δcyi随着训练逐渐逼近类中心点。
- 贡献:
能够更好的区分细节,即当两个输入样本十分相似时,能够对细节更好的建模。
在一定程度上提升了类间距,缩小类内距。提出了 softmax 的类间距较小的问题,开启优化softmax的先河 - 缺点:
训练不稳定,收敛慢,容易过拟合。
center loss 和 softmax 的对比:

2.2 L-softmax
决策边界的概念
论文:Large-Margin Softmax Loss for Convolutional Neural Networks
假设只有两个类的情况下(方便分析,推广到多类别同样适用)
softmax:
L
1
=
−
1
N
∑
i
=
1
N
l
o
g
e
W
y
i
T
x
i
+
b
y
i
∑
j
=
1
N
W
y
i
T
x
i
+
b
y
i
L_{1} = - \frac{1}{N} \sum_{i=1}^{N} {log \frac{e^{W^{T}_{y_{i}} x_{i} + b_{y_{i}}}} {\sum_{j=1}^{N}{W^{T}_{y_{i}} x_{i} + b_{y_{i}}}}}
L1=−N1i=1∑Nlog∑j=1NWyiTxi+byieWyiTxi+byi
由 softmax 的公式可知,当类别为二的时候,分类为1和2的概率p分别为
p
1
=
e
W
1
T
x
+
b
1
p_{1} = e^{W^{T}_{1} x + b_{1}}
p1=eW1Tx+b1 和
p
2
=
e
W
2
T
x
+
b
2
p_{2} = e^{W^{T}_{2} x + b_{2}}
p2=eW2Tx+b2,当p1 > p2 的时候判断为类1, 当p1 < p2时判断为类2 。因此判断边界为
p
1
=
=
p
2
p_{1} == p_{2}
p1==p2, 即
W
1
T
x
+
b
1
=
W
2
T
x
+
b
2
W^{T}_{1} x + b_{1} = W^{T}_{2} x + b_{2}
W1Tx+b1=W2Tx+b2。因此其决策边界依赖于 W 和 b 两个矩阵。
L-softmax 引入参数W的归一化,并将偏置 b置为零。决策边界
W
1
T
x
+
b
1
=
W
2
T
x
+
b
2
W^{T}_{1} x + b_{1} = W^{T}_{2} x + b_{2}
W1Tx+b1=W2Tx+b2变为
∥
x
∥
c
o
s
(
θ
1
)
=
∥
x
∥
c
o
s
(
θ
2
)
\lVert x \rVert cos(\theta_{1}) = \lVert x \rVert cos(\theta_{2})
∥x∥cos(θ1)=∥x∥cos(θ2) ,softmax的边界
∥
W
1
T
∥
∥
x
∥
c
o
s
(
θ
1
)
=
∥
W
2
T
∥
∥
x
∥
c
o
s
(
θ
2
)
\lVert W^{T}_{1}\rVert \lVert x \rVert cos(\theta_{1}) = \lVert W^{T}_{2} \rVert \lVert x \rVert cos(\theta_{2})
∥W1T∥∥x∥cos(θ1)=∥W2T∥∥x∥cos(θ2)既依赖于权重向量的大小,又依赖于角度的余弦值,从而导致余弦空间中的决策区域重叠(重叠就是margin < 0)。因此,L-softmax仅以角度(angular) 作为决策边界优于原softmax依赖于 W 和
θ
\theta
θ判断边界。
注:
θ
\theta
θ代表
W
W
W和
x
x
x的夹角
L-softmax:
L
1
=
−
1
N
∑
i
=
1
N
l
o
g
e
∥
x
i
∥
c
o
s
(
m
θ
y
i
,
i
)
e
∥
x
i
∥
c
o
s
(
m
θ
y
i
,
i
)
+
∑
i
≠
j
e
∥
x
i
∥
c
o
s
(
θ
i
,
j
)
L_{1} = - \frac{1}{N} \sum_{i=1}^{N} {log \frac{e^{\lVert x_{i} \rVert cos(m \theta_{y_{i,i}})} } {e^{\lVert x_{i} \rVert cos(m \theta_{y_{i,i}} ) }+\sum_{i \neq j}^{}{ e^{ \lVert x_{i} \rVert cos( \theta_{i,j})} }}}
L1=−N1i=1∑Nloge∥xi∥cos(mθyi,i)+∑i=je∥xi∥cos(θi,j)e∥xi∥cos(mθyi,i)
引入
c
o
s
(
m
θ
y
i
,
i
)
cos(m \theta_{y_{i,i}})
cos(mθyi,i) 参数m作为角边距来调参控制训练的类间距。
- 贡献:
用夹角 θ \theta θ来控制决策边界,引入角边距m。优化了扩大类间距的算法。
注:论文中并没有归一化W矩阵,这里是为了简化计算。真正开始归一化矩阵W的是下一节的A-softmax。
L-softmax 和 softmax:

左边第一个是softmax,右边三个是取m不同的L-softmax。
2.3A-softmax
在L-softmax loss (large margin softmax loss)的基础上再添加限制条件||W||=1(权重归一化)和b=0就会使得预测仅取决于W和x之间的角度θ,这样便得到了angular softmax loss,简称A-softmax loss。上述L-softmax中,为了简化推理,已经使用了||W||=1(权重归一化)和b=0的假设。实际上,原论文并没有这样做。
原L-softmax的公式:
L
1
=
−
1
N
∑
i
=
1
N
l
o
g
e
∥
W
i
∥
∥
x
i
∥
c
o
s
(
m
θ
y
i
,
i
)
+
b
i
e
∥
W
i
∥
∥
x
i
∥
c
o
s
(
m
θ
y
i
,
i
)
+
b
i
+
∑
i
≠
j
e
∥
W
i
∥
∥
x
i
∥
c
o
s
(
θ
i
,
j
)
+
b
i
L_{1} = - \frac{1}{N} \sum_{i=1}^{N} {log \frac{e^{\lVert W_{i} \rVert \lVert x_{i} \rVert cos(m \theta_{y_{i,i}}) + b_{i}} } {e^{\lVert W_{i} \rVert \lVert x_{i} \rVert cos(m \theta_{y_{i,i}} ) + b_{i}}+\sum_{i \neq j}^{}{ e^{\lVert W_{i} \rVert \lVert x_{i} \rVert cos( \theta_{i,j}) + b_{i}} }}}
L1=−N1i=1∑Nloge∥Wi∥∥xi∥cos(mθyi,i)+bi+∑i=je∥Wi∥∥xi∥cos(θi,j)+bie∥Wi∥∥xi∥cos(mθyi,i)+bi
A-softmax的公式(添加W归一化,b=0 的L-softmax):
L
1
=
−
1
N
∑
i
=
1
N
l
o
g
e
∥
x
i
∥
c
o
s
(
m
θ
y
i
,
i
)
e
∥
x
i
∥
c
o
s
(
m
θ
y
i
,
i
)
+
∑
i
≠
j
e
∥
x
i
∥
c
o
s
(
θ
i
,
j
)
L_{1} = - \frac{1}{N} \sum_{i=1}^{N} {log \frac{e^{\lVert x_{i} \rVert cos(m \theta_{y_{i,i}})} } {e^{\lVert x_{i} \rVert cos(m \theta_{y_{i,i}} ) }+\sum_{i \neq j}^{}{ e^{ \lVert x_{i} \rVert cos( \theta_{i,j})} }}}
L1=−N1i=1∑Nloge∥xi∥cos(mθyi,i)+∑i=je∥xi∥cos(θi,j)e∥xi∥cos(mθyi,i)
2.4Cosface
- A-softmax的缺点:
由决策边界: ∥ x ∥ c o s ( m θ 1 ) = ∥ x ∥ c o s ( θ 2 ) \lVert x \rVert cos(m\theta_{1}) = \lVert x \rVert cos(\theta_{2}) ∥x∥cos(mθ1)=∥x∥cos(θ2) 可知, 当 ∥ x ∥ c o s ( m θ 1 ) > ∥ x ∥ c o s ( θ 2 ) \lVert x \rVert cos(m \theta_{1}) > \lVert x \rVert cos(\theta_{2}) ∥x∥cos(mθ1)>∥x∥cos(θ2)时,x被分类到类1。
A-Softmax的margin在所有θ值上都不一致:当θ减小时, margin变小,当θ= 0时,margin完全消失。

softmax在类c1、c2的区分上有重叠;NLS(即W归一化)c1、c2之间没有重叠也没有距离margin;A-softmax c1、c2之间有margin但随着角度 θ \theta θ减小到0;LMCL(CosFace) c1、c2之间有清晰的边界。
A-softmax容易导致两个潜在的问题: - 首先,对于视觉上相似因此在W1和W2之间具有较小角度的困难类别C1和C2,margin很小。
- 其次,从技术上讲,必须采用额外的技巧用ad-hoc piecewise function来克服计算余弦相似度时的非单调性困难( c o s θ cos\theta cosθ递增区间和递减区间)。
因此,cosface loss改进了A-sofamax,W权重L2归一化,x输入向量归一化到一个固定值s,让cos(θ)加上m。对cosface来说,s需要足够大。
公式:
c
o
s
(
m
θ
)
⇒
c
o
s
(
θ
)
+
m
x
=
s
⋅
x
∗
∥
x
∗
∥
⇒
∥
x
∥
=
s
cos(m\theta) \Rightarrow cos(\theta) + m \\\\ x = s \cdot \frac{x^{*}}{\lVert x_{*} \rVert} \\\\ \Rightarrow \lVert x \rVert = s
cos(mθ)⇒cos(θ)+mx=s⋅∥x∗∥x∗⇒∥x∥=s
推导出新的损失函数
L
1
=
−
1
N
∑
i
=
1
N
l
o
g
e
s
(
c
o
s
(
θ
y
i
,
i
)
−
m
)
e
s
(
c
o
s
(
θ
y
i
,
i
)
−
m
)
+
∑
i
≠
j
e
∥
x
i
∥
c
o
s
(
θ
i
,
j
)
L_{1} = - \frac{1}{N} \sum_{i=1}^{N} {log \frac{e^{s (cos(\theta_{y_{i,i}}) - m)} } {e^{s (cos(\theta_{y_{i,i}} ) - m) }+\sum_{i \neq j}^{}{ e^{ \lVert x_{i} \rVert cos( \theta_{i,j})} }}}
L1=−N1i=1∑Nloges(cos(θyi,i)−m)+∑i=je∥xi∥cos(θi,j)es(cos(θyi,i)−m)
决策边界
c
o
s
(
θ
1
)
−
m
=
c
o
s
(
θ
2
)
cos(\theta_{1}) - m = cos(\theta_{2})
cos(θ1)−m=cos(θ2),距离margin由m调节。
- 贡献:
引入数据x的归一化,优化 θ \theta θ的边界问题。
2.5 arcface
在 x x x和 W i W_{i} Wi之间的θ上加上角度间隔m(注意是加在了角θ上),以加法的方式惩罚深度特征与其相应权重之间的角度,从而同时增强了类内紧度和类间差异。
比如训练时降到某一固定损失值时,有Margin和无Margin的e指数项是相等的,则有Margin的 θ i \theta_{i} θi就需要相对的减少了。这样来看有 Margin的训练就会把 i 类别的输入特征和权重间的夹角 θ i \theta_{i} θi缩小了,从一些角度的示图中可以看出,Margin把 θ i \theta_{i} θi挤得更类内聚合了, θ i \theta_{i} θi和其他 θ \theta θ类间也就更分离了。
公式:
L
1
=
−
1
N
∑
i
=
1
N
l
o
g
e
s
(
c
o
s
(
θ
y
i
,
i
+
m
)
)
e
s
(
c
o
s
(
θ
y
i
,
i
+
m
)
)
+
∑
i
≠
j
e
∥
x
i
∥
c
o
s
(
θ
i
,
j
)
L_{1} = - \frac{1}{N} \sum_{i=1}^{N} {log \frac{e^{s (cos(\theta_{y_{i,i}} + m) )} } {e^{s (cos(\theta_{y_{i,i}} + m) ) }+\sum_{i \neq j}^{}{ e^{ \lVert x_{i} \rVert cos( \theta_{i,j})} }}}
L1=−N1i=1∑Nloges(cos(θyi,i+m))+∑i=je∥xi∥cos(θi,j)es(cos(θyi,i+m))
决策边界:
c
o
s
(
θ
1
+
m
)
=
c
o
s
(
θ
2
)
cos(\theta_{1} + m) = cos(\theta_{2})
cos(θ1+m)=cos(θ2)
决策边界:
ArcFace:Additive Angular Margin,加法角度间隔
SphereFace(A-softmax):Multiplicative Angular Margin,乘法角度间隔
CosFace:Additive Cosine margin,加法余弦间隔

3.参考
论文
- center softmaxA Discriminative Feature Learning Approach for Deep Face Recognition
- L-softmax Large-Margin Softmax Loss for Convolutional Neural Networks
- A-softmaxDeep Hypersphere Embedding for Face Recognition
- CosfaceLarge Margin Cosine Loss for Deep Face Recognition
- ArcfaceAdditive Angular Margin Loss for Deep Face Recognition
博客
- center softmax人脸识别论文再回顾之一:Center Loss
- L-softmax 深度学习–Large Marge Softmax Loss损失
- A-softmax深度学习—A-softmax原理+代码
- Cosface人脸识别合集 | 9 CosFace解析
- Arcface人脸识别合集 | 10 ArcFace解析

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)