数据清洗:Python将一列数据拆分成多列
最近在处理数据的时候遇到这样一个问题,原始数据中有些字段以(key:value)形式存储的数据,如表中Sex一列取值[F: Female],其中F是key、Female是具体的value。为了简化数据,利用pandas.Series.str.split(pat=None, n=-1, expand=False)进行数据拆分,只取其中的value。
·
最近在处理数据的时候遇到这样一个问题,原始数据中有些字段以(key:value)存储的数据,如表中SEX:Sex一列取值[F: Female],其中F是key、Female是具体的value。为了简化数据,想利用Python把数据进行拆分,只取其中的value。
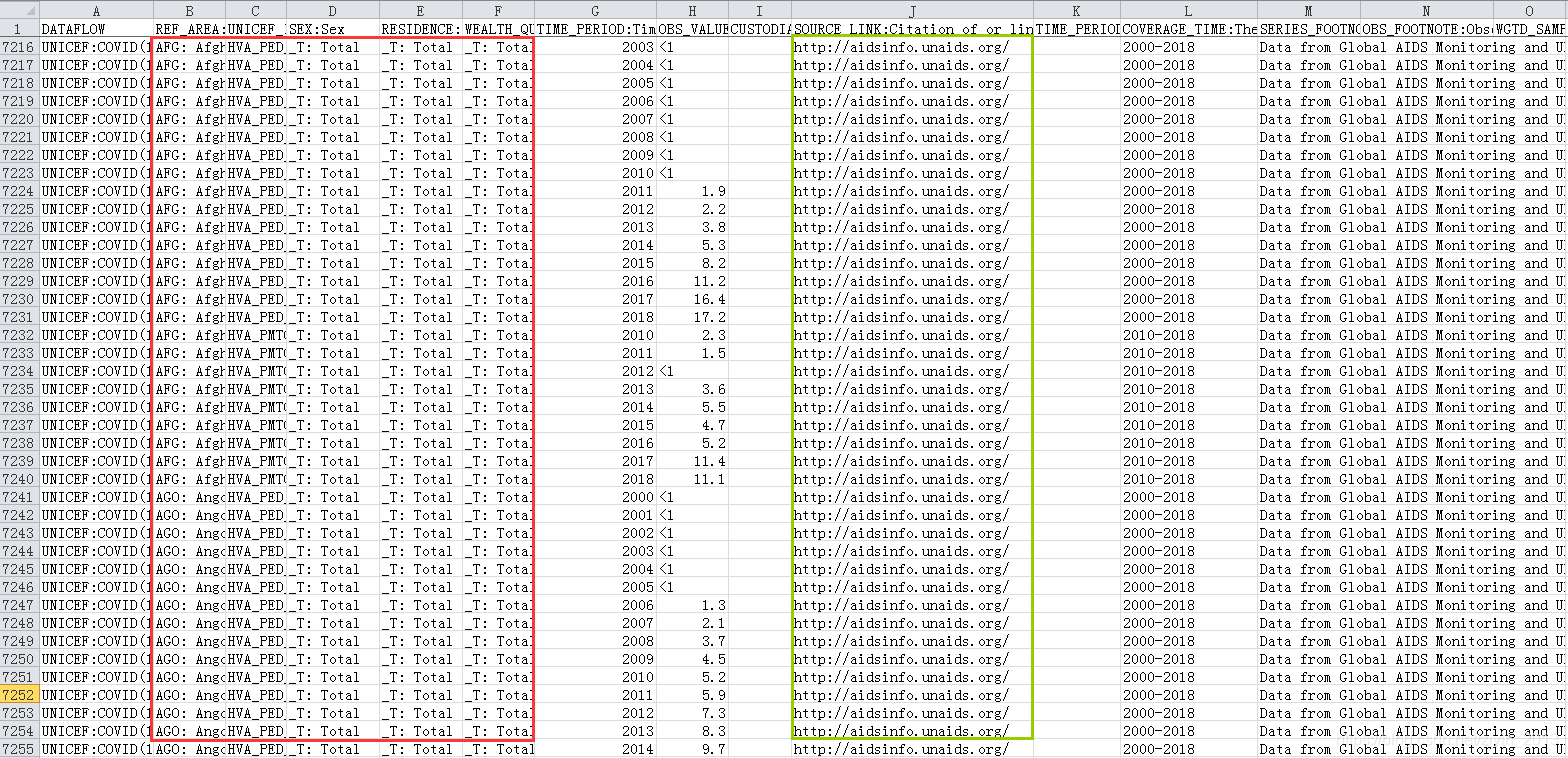
观察数据发现,有些字段的取值均为key:value形式,比如SEX:Sex字段,需要进行拆分;而有些字段是不需要进行拆分的,比如TIME_PERIOD:Time period字段,再比如SOURCE_LINK:Citation of or link to the data source字段,取值为链接也不用拆分。按以下思路进行数据处理:
- 读取数据,查看数据的基本情况;
import pandas as pd
file='fusion_COVID_UNICEF__all.csv' ##所在文件夹目录
data=pd.read_csv(file,encoding='utf-8',sep=None,delimiter=",",error_bad_lines=False)
columns=data.columns.tolist() ##获取字段
print(columns)
data.head()
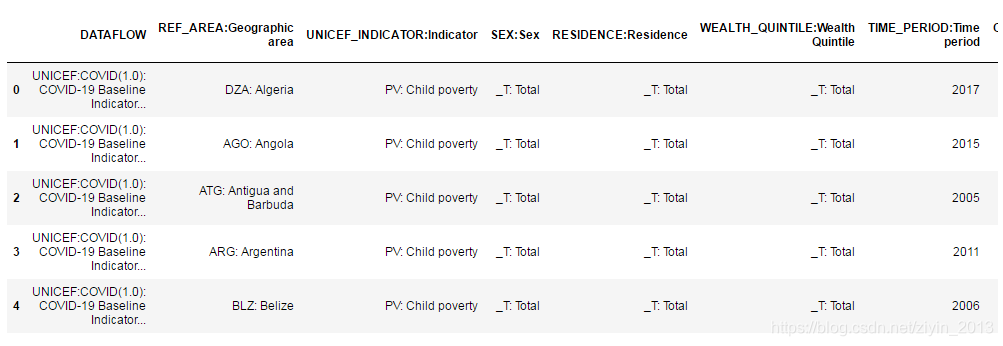
- 统计需要进行拆分的字段:如果某一列所有非空取值均包含“:”,而不包含“http:”和“https:”,则需要拆分;
##判断字段是否需要拆分
split_col=[] ##记录需要拆分的字段
for i in columns:
num=0
#print(i)
#print(data[i])
temp=data[i].dropna() ##去掉字段中的空值
#print(len(data[i]),len(temp))
if len(temp)>0: ##对于有取值的字段,判断是否需要进行拆分
for j in temp:
if ":" in str(j) and "http:" not in str(j) and "https:" not in str(j):
num+=1
if num==len(temp):
#print("需拆分:",i)
split_col.append(i)
print("需要拆分的字段:",split_col)

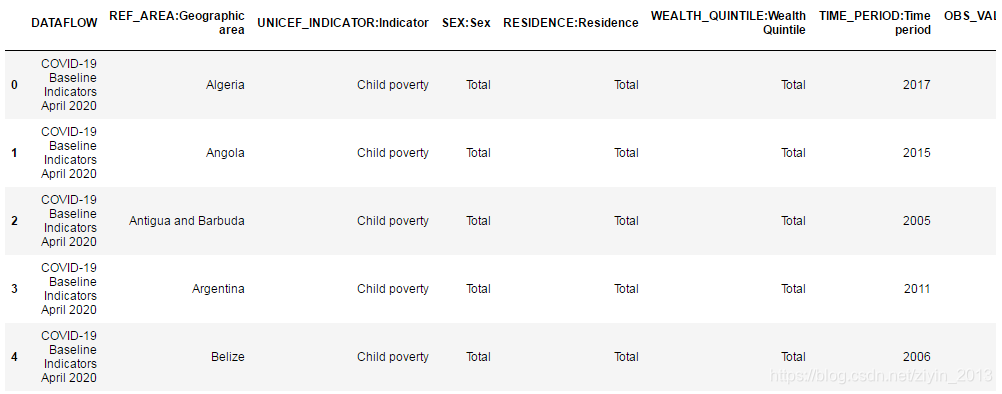
- 拆分数据并进行保存。
利用pandas.Series.str.split(pat=None, n=-1, expand=False)函数进行数据拆分。其中,pat表示分隔符,默认以空格分隔;n表示分割次数,默认为 -1,即分隔所有;expand为true,表示会把切割出来的内容当做一列,产生多列,若为False,则把切割后的内容当作一个列表。
##将数据进行拆分并保存
cleaned=pd.DataFrame()
for i in columns:
if i in split_col:
#print(i)
temp=data[i].str.split(": ",expand=True)
#print(temp[1])
cleaned[i]=temp[1]
else:
cleaned[i]=data[i]
cleaned.to_csv("data/result_UNICEF_COVID.csv",encoding='utf-8',index=0)
print ('--- End ---')
cleaned.head()
附:完整代码和数据可通过以下链接自行下载。
链接:https://pan.baidu.com/s/1noQYAmxr9KNSKbtDfr_XwQ
提取码:e8z7
ps:初衷是通过撰写博文记录自己所学所用,实现知识的梳理与积累;将其分享,希望能够帮到面临同样困惑的小伙伴儿。如发现博文中存在问题,欢迎随时交流~~

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)