机器学习集成模型学习——Stacking集成学习(五)
stacking集成模型示例如下:stacking一般由2层堆叠构成Stacking集成算法思路上图为整体流程,思路如下:把原始数据切分成两部分:训练集D-train与测试集D-test,训练集部分用来训练整体的Stacking集成模型,测试集部分用来测试集成模型训练集D-train中又划分出两个部分:Training folds-训练集与Validation fold-验证集,其中Trainin
·
stacking集成模型示例如下:
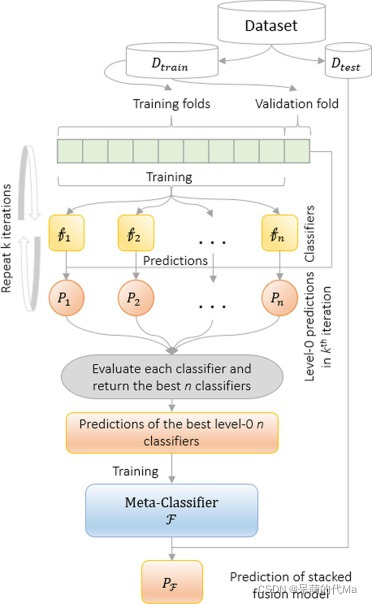
stacking一般由2层堆叠构成
Stacking集成算法思路
上图为整体流程,思路如下:
-
把原始数据切分成两部分:训练集
D-train与测试集D-test,训练集部分用来训练整体的Stacking集成模型,测试集部分用来测试集成模型 -
训练集
D-train中又划分出两个部分:Training folds-训练集与Validation fold-验证集,其中Training folds部分用来训练初级学习器(浅黄色的模型) -
下图中的
Learn对应上图Training folds,用来训练初级学习器;下图中的Predict对应上图Validation fold,用来通过初级训练器得到预测结果Predictions,这些预测结果将用来训练次级学习器Model2

-
Model2一般是逻辑回归,用来计算各个初级学习器的权重。 -
这一整套训练完成后,用
D-test来测试整个集成模型,得到模型的指标
代码示例
# _*_coding:utf-8 _*_
# Time: 2022/3/29
"""
"""
from sklearn.ensemble import StackingClassifier
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
def load_data(samples=1000):
"""
用来生成训练、测试数据
:param samples: 数据量
:return: 返回x与y或切分训练集后的x与y
"""
data_x, data_y = make_classification(n_samples=samples, n_classes=4, n_features=10, n_informative=8)
df_x = pd.DataFrame(data_x, columns=['f_1', 'f_2', 'f_3', 'f_4', 'f_5', 'f_6', "f_7", "f_8", "f_9", "f_10"])
df_y = pd.Series(data_y)
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, train_size=0.7, random_state=0, shuffle=True)
return x_train, x_test, y_train, y_test
def main():
x_train, x_test, y_train, y_test = load_data()
stacking_classifier = StackingClassifier(
estimators=[ # 初级学习器
('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
('svr', make_pipeline(StandardScaler(), SVC(random_state=42)))
],
final_estimator=LogisticRegression()) # 次级学习器
stacking_classifier.fit(x_train, y_train)
result_prediction = stacking_classifier.predict(x_test)
acc = accuracy_score(y_test, result_prediction) # 准确率
print("acc:", acc)
if __name__ == '__main__':
main()

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)