时间序列(数据分析)
第11章 时间序列时间序列数据在很多领域都是重要的结构化数据形式,例如金融、经济、生态学、神经科学和物理学。在多个时间点观测或测量的数据形成了时间序列。许多时间序列是固定频率的,也就是说数据是根据相同的规则定期出现的,例如每15秒、每5分钟或每月1次。时间序列也可以是不规则的,没有固定的时间单位或单位间的偏移量。最简单和最广泛使用的时间序列是那些由时间戳索引的。11.1 日期和时间数据的类型及工具
目录
第11章 时间序列
时间序列数据在很多领域都是重要的结构化数据形式,例如金融、经济、生态学、神经科学和物理学。
在多个时间点观测或测量的数据形成了时间序列。
许多时间序列是固定频率的,也就是说数据是根据相同的规则定期出现的,例如每15秒、每5分钟或每月1次。
时间序列也可以是不规则的,没有固定的时间单位或单位间的偏移量。
最简单和最广泛使用的时间序列是那些由时间戳索引的。
11.1 日期和时间数据的类型及工具
Python标准库包含了日期和时间数据的类型,也包括日历相关的功能。
datetime、time和calendar模块是开始处理时间数据的主要内容。
datetime.datetime类型,或简写为datetime,是广泛使用的:
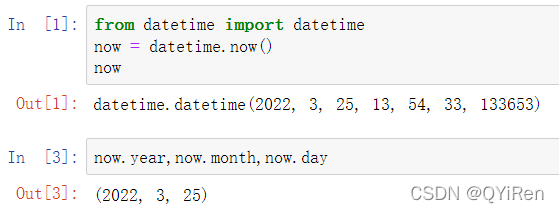
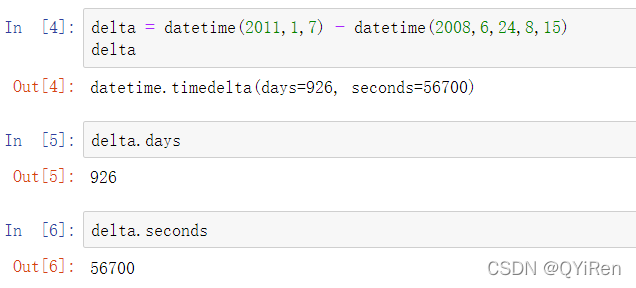
datetime既存储了日期,也存储了细化到微秒的时间。timedelta表示两个datetime对象的时间差:
datetime模块的数据类型:

11.1.1 字符串与datetime互相转换
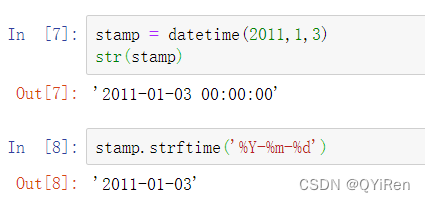
可以使用str方法或传递一个指定的格式给strftime方法来对datetime对象和pandas的Timestamp对象进行格式化:
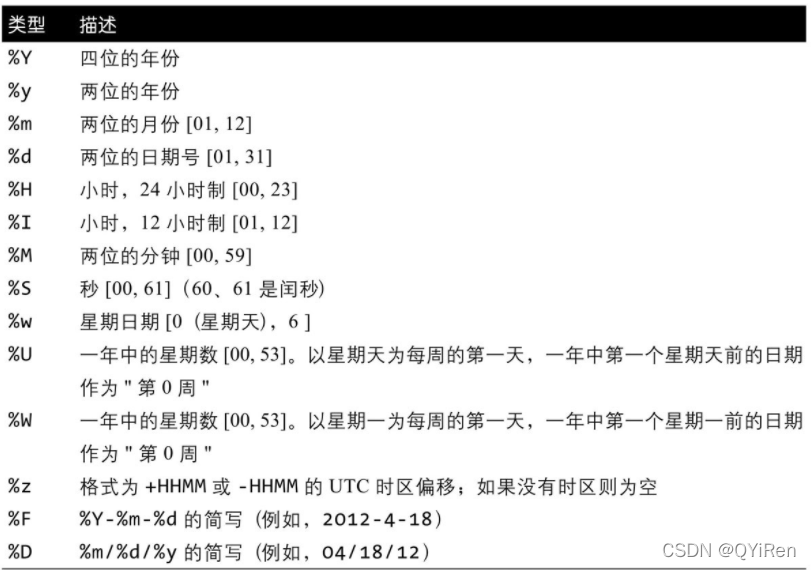
格式代码的完整列表:
可以使用datetime.strptime,将字符串转换日期:
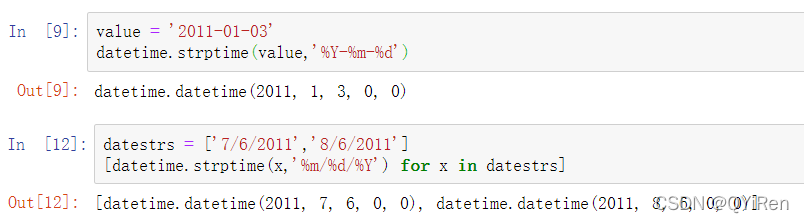
datetime.strptime是在已知格式的情况下转换日期的好方式。
每次都必须编写一个格式代码可能有点烦人,特别是对于通用日期格式,在这种情况下,使用第三方dateutil包的parser.parse方法:
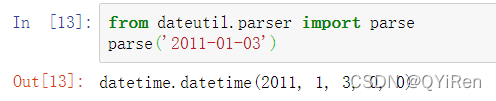
dateutil能够解析大部分人类可理解的日期表示:

在国际场合下,日期出现在月份之前很常见,因此你可以传递dayfirst=True来表明这种情况:

pandas主要是面向处理日期数组的,无论是用作轴索引还是用作DataFrame中的列。
to_datetime方法可以转换很多不同的日期表示格式。
标准日期格式,比如ISO8601可以非常快地转换:

to_datetime方法还可以处理那些被认为是缺失值的值(None、空字符串等):
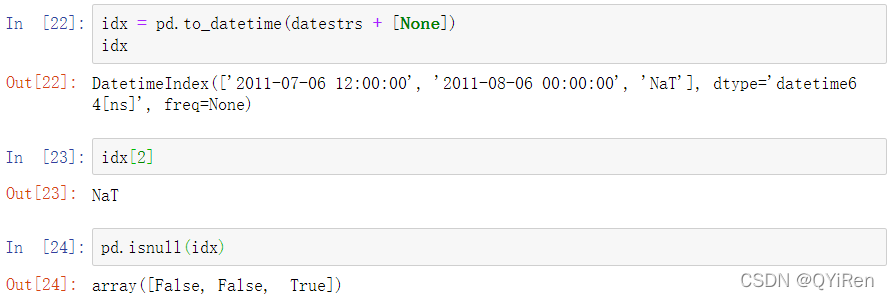
NaT(Not a time)是pandas中时间戳数据的是null值。
dateutil.parser是一个有用但并不完美的工具。值得注意的是,它会将一些字符串识别为你并不想要的日期——例如,'42’将被解析为2042年的当前日期。
11.2 时间序列基础
pandas中的基础时间序列种类是由时间戳索引的Series,在pandas外部则通常表示为Python字符串或datetime对象:
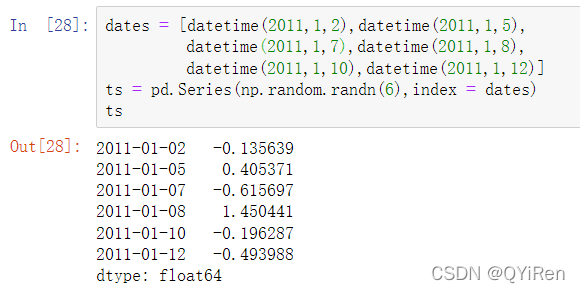
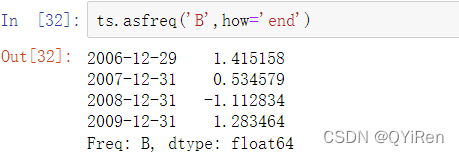
在这种情况下,这些datetime对象可以被放入DatetimeIndex中:

和其他Series类似,不同索引的时间序列之间的算术运算在日期上自动对齐:
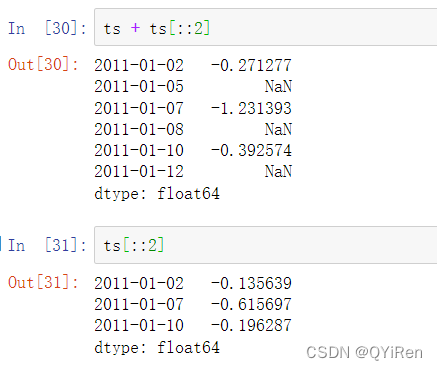
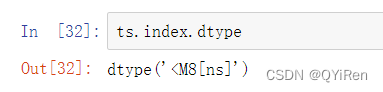
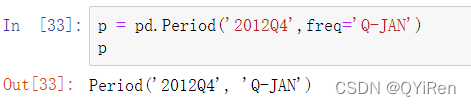
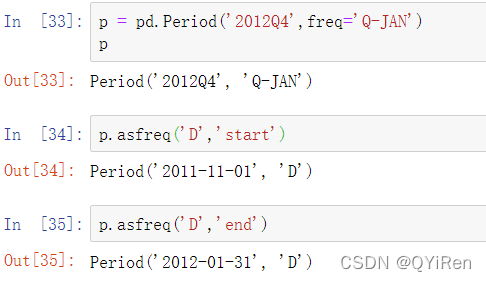
pandas使用NumPy的datetime64数据类型在纳秒级的分辨率下存储时间戳:
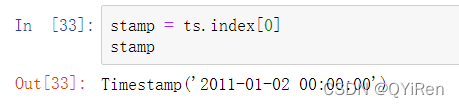
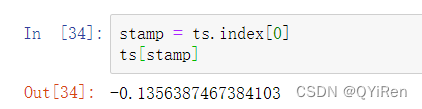
DatetimeIndex中的标量值是pandas的Timestamp对象:
所有使用datetime对象的地方都可以用Timestamp。
此外,Timestamp还可以存储频率信息(如果有的话)并了解如何进行时区转换和其他类型操作。
11.2.1 索引、选择、子集
当你基于标签进行索引和选择时,时间序列的行为和其他的pandas.Series类似:
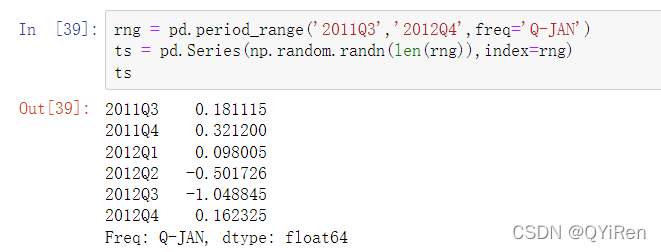
为了方便,你还可以传递一个能解释为日期的字符串:
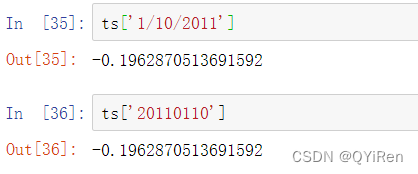
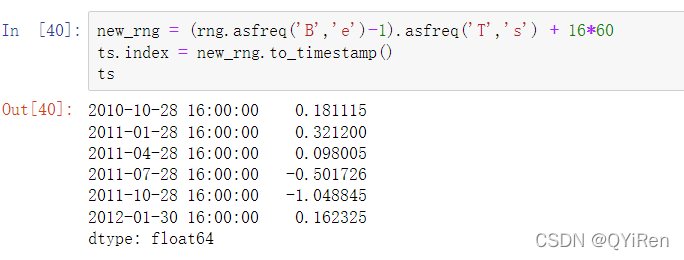
对一个长的时间序列,可以传递一个年份或一个年份和月份来轻松地选择数据的切片:
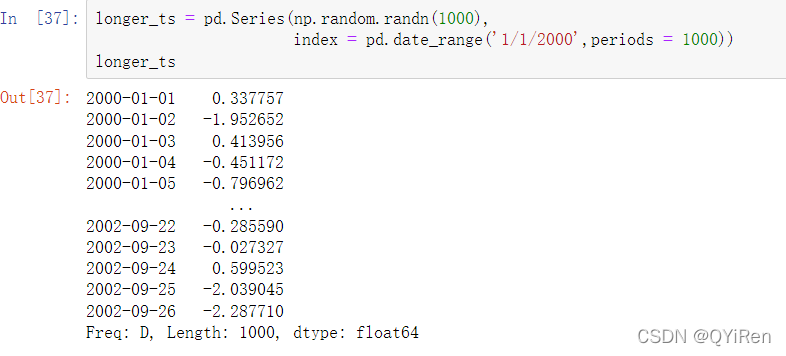
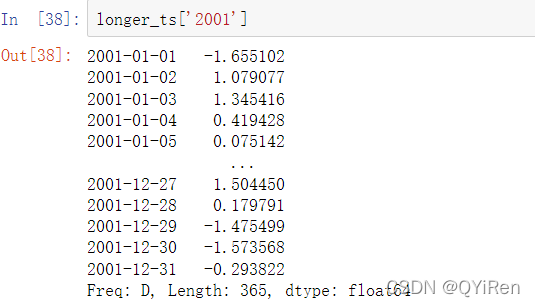
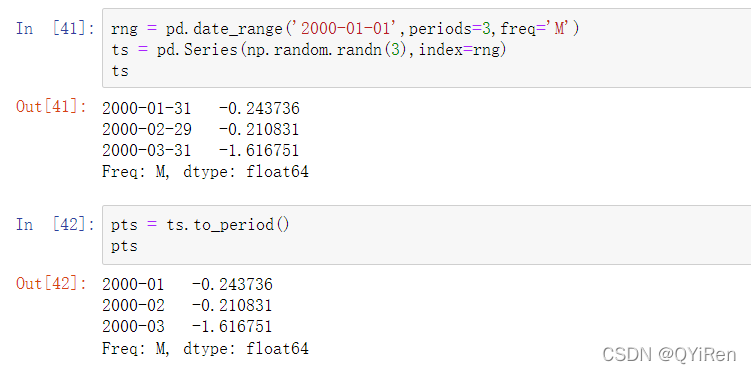
如果你指定了月份也是有效的:
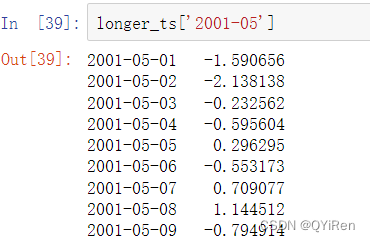
使用datetime对象进行切片也是可以的:
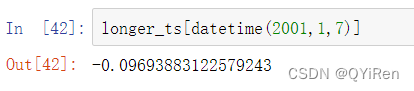
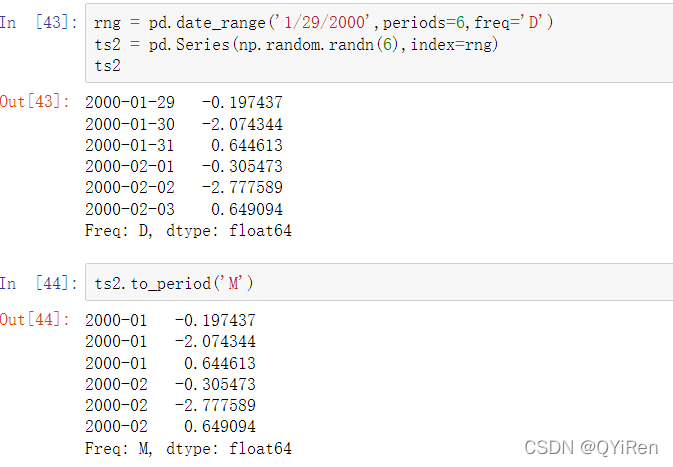
大部分的时间序列数据是按时间顺序排序的,你可以使用不包含在时间序列中的时间戳进行切片,以执行范围查询:
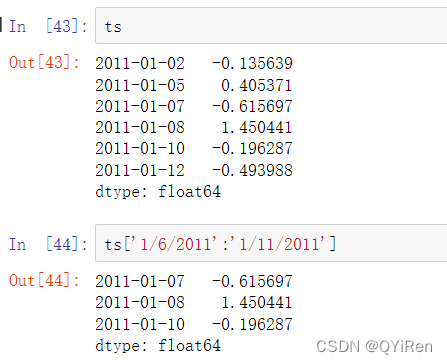
和之前一样,你可以传递一个字符串的日期、datetime对象或者时间戳。请记住通过这种方式的切片产生了原时间序列的视图,类似于NumPy的数组。这意味着没有数据被复制,并且在切片上的修改会反映在原始数据上。
有一个等价实例方法,truncate,它可以在两个日期间对Series进行切片:
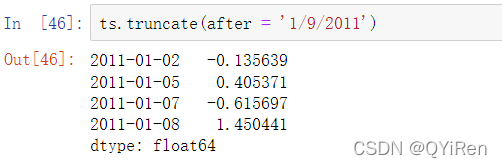
上面这些操作也都适用于DataFrame,并在其行上进行索引:
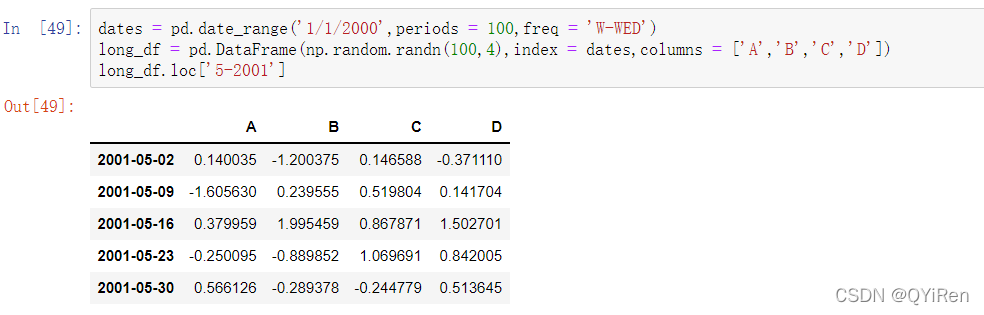
11.2.2 含有重复索引的时间序列
在某些应用中,可能会有多个数据观察值落在特定的时间戳上。
示例:
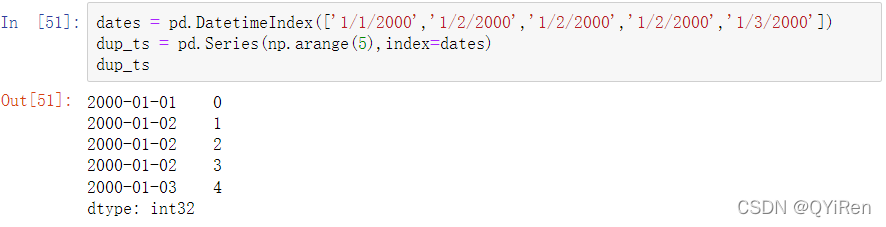
通过检查索引的is_unique属性,我们可以看出索引并不是唯一的:
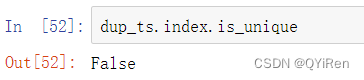
对上面的Series进行索引,结果是标量值还是Series切片取决于是否有时间戳是重复的:
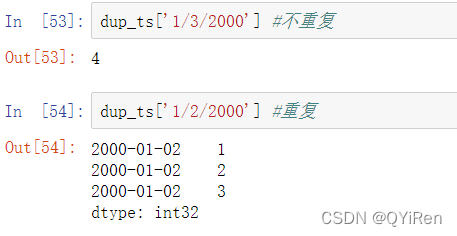
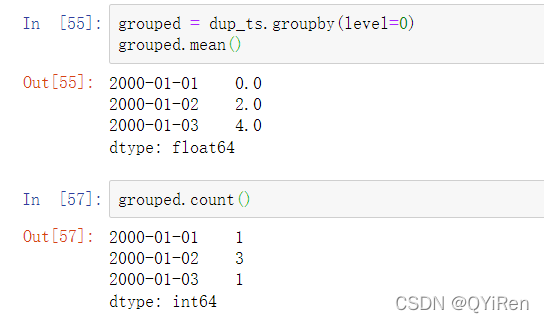
假设你想要聚合含有非唯一时间戳的数据。一种方式就是使用groupby并传递level=0:
11.3 日期范围、频率和移位
pandas的通用时间序列是不规则的,即时间序列的频率不是固定的。
经常有需要处理固定频率的场景,例如每日的、每月的或每15分钟,这意味着我们甚至需要在必要的时候向时间序列中引入缺失值。
pandas拥有一整套标准的时间序列频率和工具用于重新采样、推断频率以及生成固定频率的数据范围。
例如,你可以通过调用resample方法将样本时间序列转换为固定的每日频率数据:
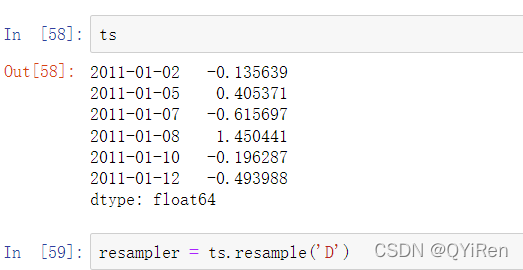
字符串’D’被解释为每日频率。在频率间转换,又称为重新采样,后边详细讲解。
11.3.1 生成日期范围
pandas.date_range是用于根据特定频率生成指定长度的DatetimeIndex:
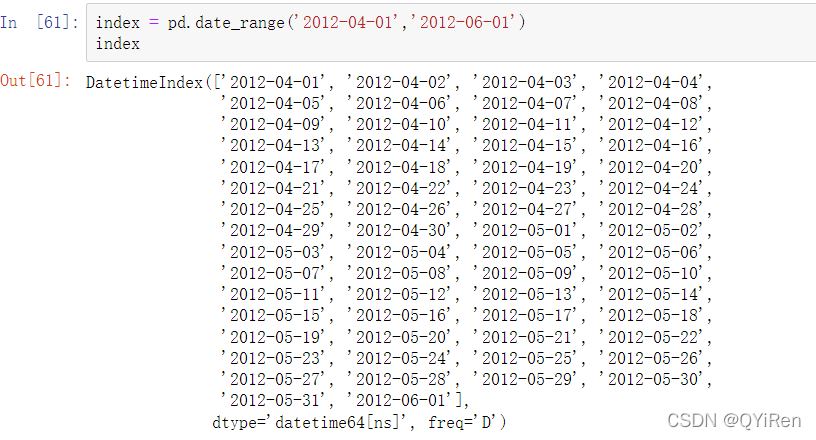
默认情况下,date_range生成的是每日的时间戳。
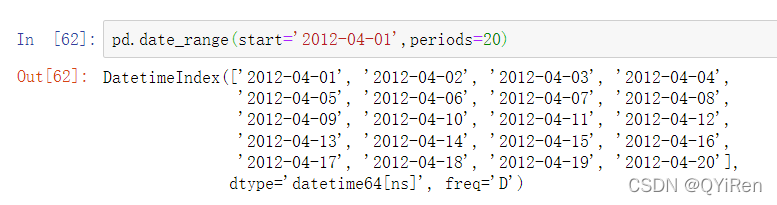
如果你只传递一个起始或结尾日期,你必须传递一个用于生成范围的数字:
开始日期和结束日期严格定义了生成日期索引的边界。例如,如果你需要一个包含每月最后业务日期的时间索引,你可以传递’BM’频率(business end of month,月度业务结尾;),只有落在或在日期范围内的日期会被包括:

基础时间序列频率(不全):


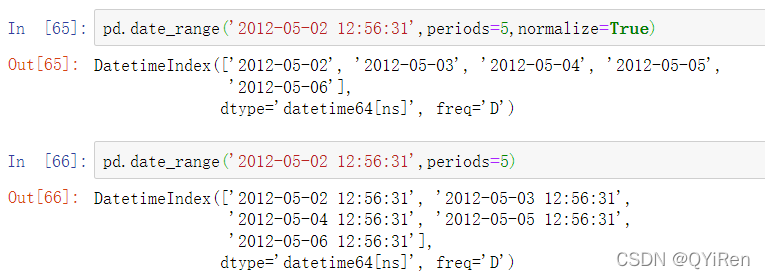
默认情况下,date_range保留开始或结束时间戳的时间(如果有的话):
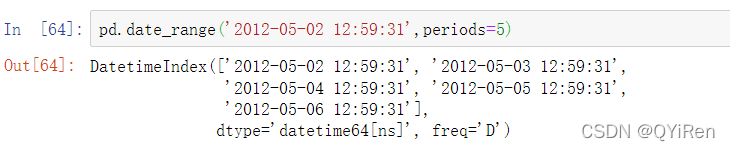
有时候你会获得包含时间信息的开始日期或结束日期,但是你想要生成的是标准化为零点的时间戳。有一个normalize选项可以实现这个功能:
11.3.2 频率和日期偏置
pandas中的频率是由基础频率和倍数组成的。
基础频率通常会有字符串别名,例如’M'代表每月,'H’代表每小时。
对于每个基础频率,都有一个对象可以被用于定义日期偏置。
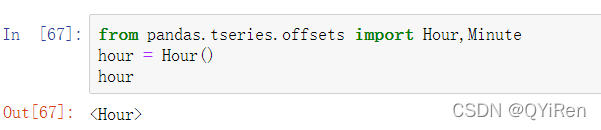
例如,每小时的频率可以使用Hour类来表示:
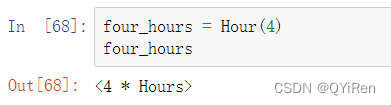
你可以传递一个整数来定义偏置量的倍数:
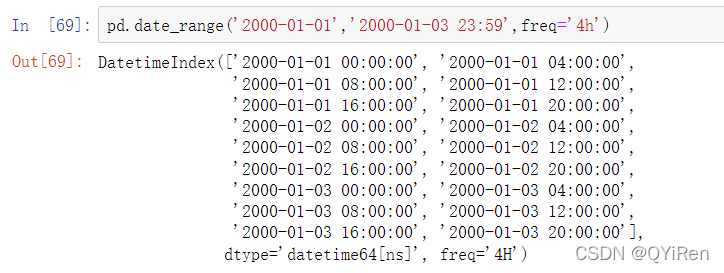
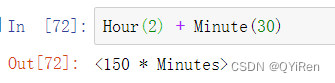
在大多数应用中,你都不需要显式地创建这些对象,而是使用字符串别名,如’H'或’4H'。在基础频率前放一个整数就可以生成倍数:
多个偏置可以通过加法进行联合:
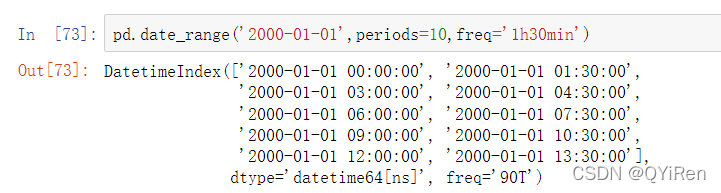
类似地,你可以传递频率字符串,例如’1h30min’将会有效地转换为同等的表达式:
有些频率描述点的时间并不是均匀分隔的。例如,'M'(日历月末)和’BM'(月内最后工作日)取决于当月天数,以及像之后的例子中,取决于月末是否是周末。我们将这些日期称为锚定偏置量。
11.3.2.1 月中某星期的日期
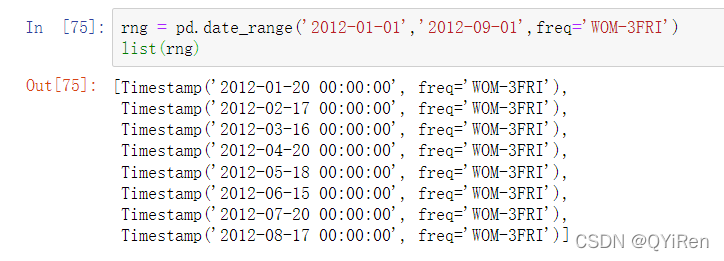
"月中某星期"(week of month )的日期是一个有用的频率类,以’WOM’开始。它允许你可以获取每月第三个星期五这样的日期:
11.3.3 移位(前向和后向)日期
"移位"是指将日期按时间向前移动或向后移动。
Series和DataFrame都有一个shift方法用于进行简单的前向或后向移位,而不改变索引:
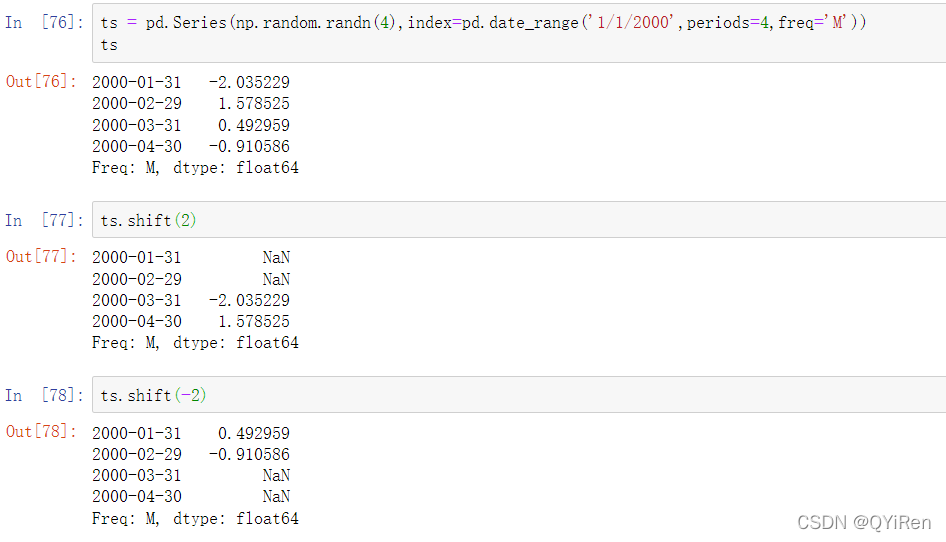
像上面这样进行移位时,会在时间序列的起始位或结束位引入缺失值。
shift常用于计算时间序列或DataFrame多列时间序列的百分比变化,代码实现如下:
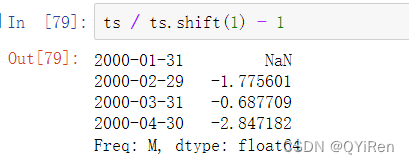
由于简单移位并不改变索引,一些数据会被丢弃。因此,如果频率是已知的,则可以将频率传递给shift来推移时间戳而不是简单的数据:
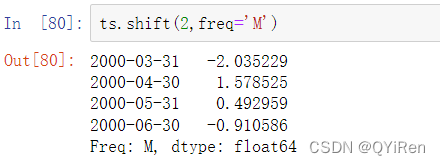
其他的频率也可以传递,为你前移和后移数据提供灵活性:
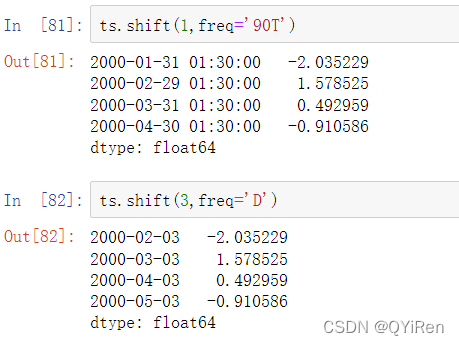
这里的T代表分钟。
11.3.3.1 使用偏置进行移位日期
pandas日期偏置也可以使用datetime或Timestamp对象完成:
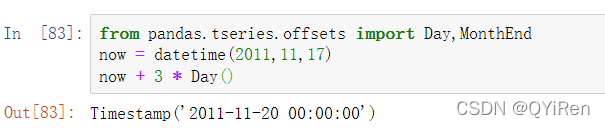
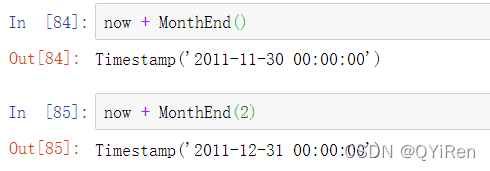
如果你添加了一个锚定偏置量,比如MonthEnd,根据频率规则,第一个增量会将日期“前滚”到下一个日期:
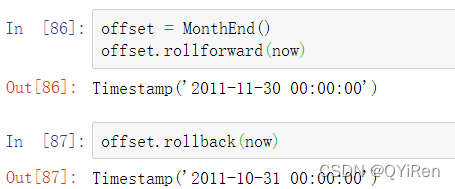
锚定偏置可以使用rollforward和rollback分别显式地将日期向前或向后"滚动":
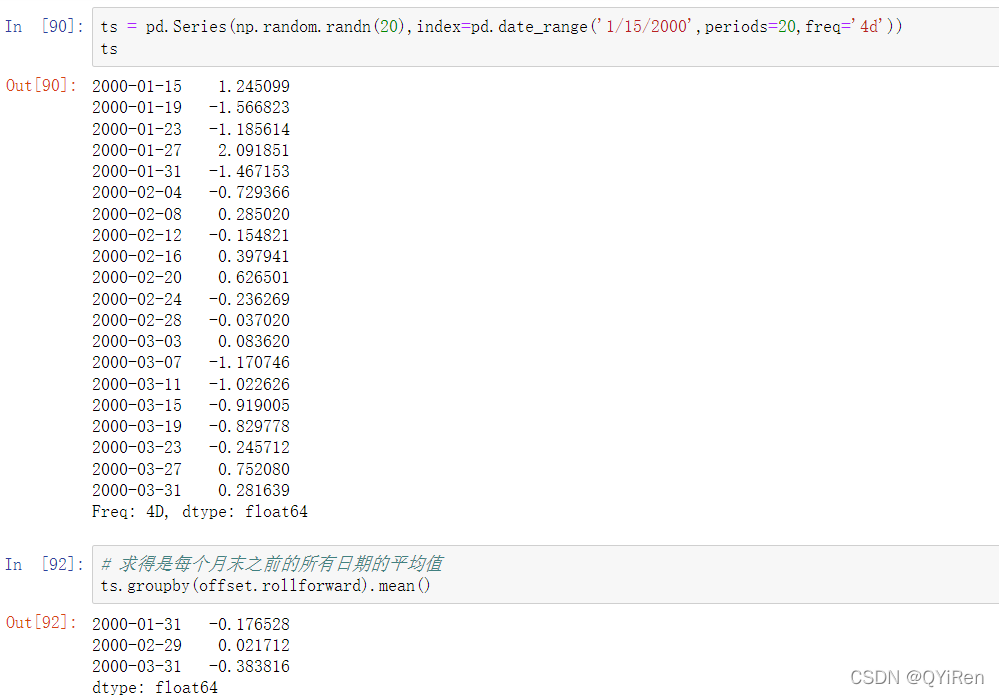
将移位方法与groupby一起使用是日期偏置的一种创造性用法:
使用resample是更简单更快捷的方法:

11.4 时区处理
在Python语言中,时区信息来源于第三方库pytz(可以使用pip或conda安装),其中公开了Olson数据库,这是世界时区信息的汇编。
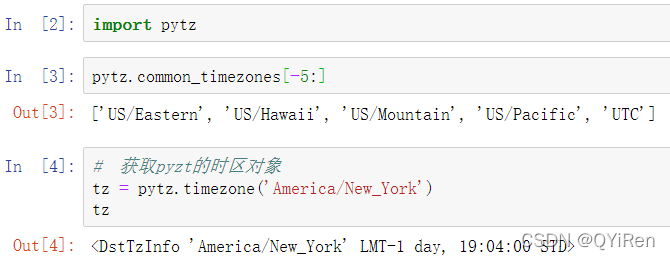
pandas中的方法可以接收时区名称或时区对象。
11.4.1 时区的本地化和转换
默认情况下,pandas中的时间序列是时区简单型的。例如,考虑下边的时间序列:
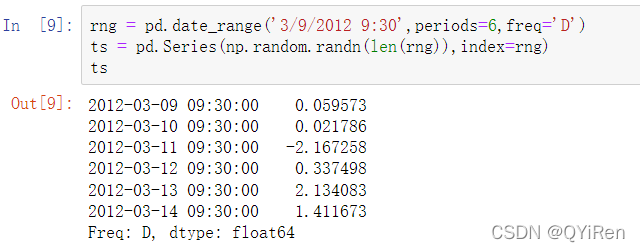
索引的tz属性是None:
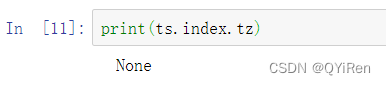
日期范围可以通过时区集合来生成:
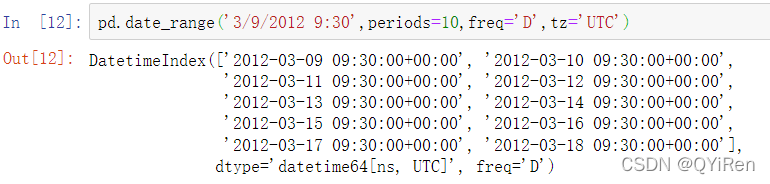
使用tz_localize方法可以从简单时区转换到本地化时区:
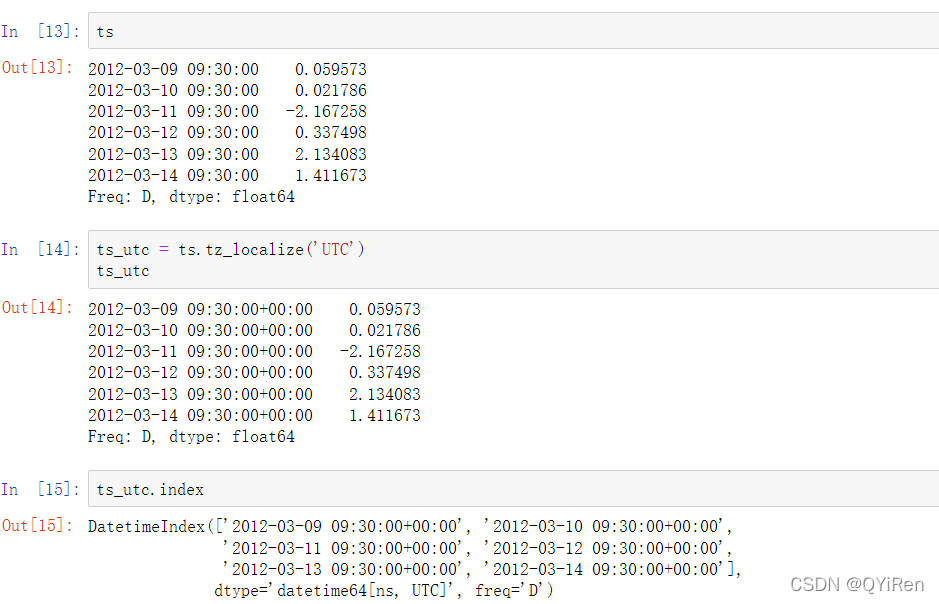
一旦时间序列被本地化为某个特定的时区,则可以通过tz_convert将其转换为另一个时区:

tz_localize和tz_convert也是DatetimeIndex的实例方法:

11.4.2 时区感知时间戳对象的操作
与时间序列和日期范围类似,单独的Timestamp对象也可以从简单时间戳本地化为时区感知时间戳,并从一个时区转换为另一个时区:

也可以在创建Timestamp的时候传递一个时区:

时区感知的Timestamp对象内部存储了一个Unix纪元(1970年1月1日)至今的纳秒数量UTC时间戳数值,该数值在时区转换中是不变的:
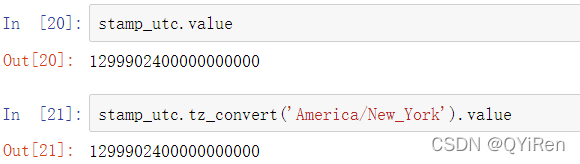
在使用pandas的DateOffset进行时间算术时,pandas尽可能遵从夏时制。这里我们构建恰好在DST转换之前发生的时间戳(向前和向后)。首先,我们构造转换到DST之前的30分钟的时间:
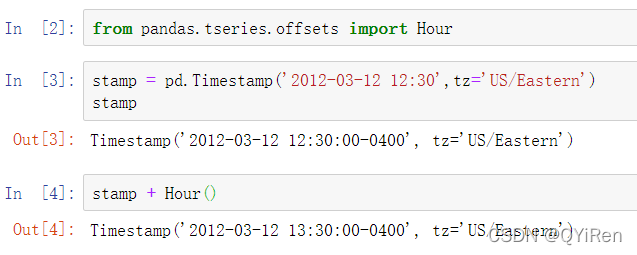
之后,我们构建从DST进行转换前的90分钟:
11.4.3 不同时区间的操作
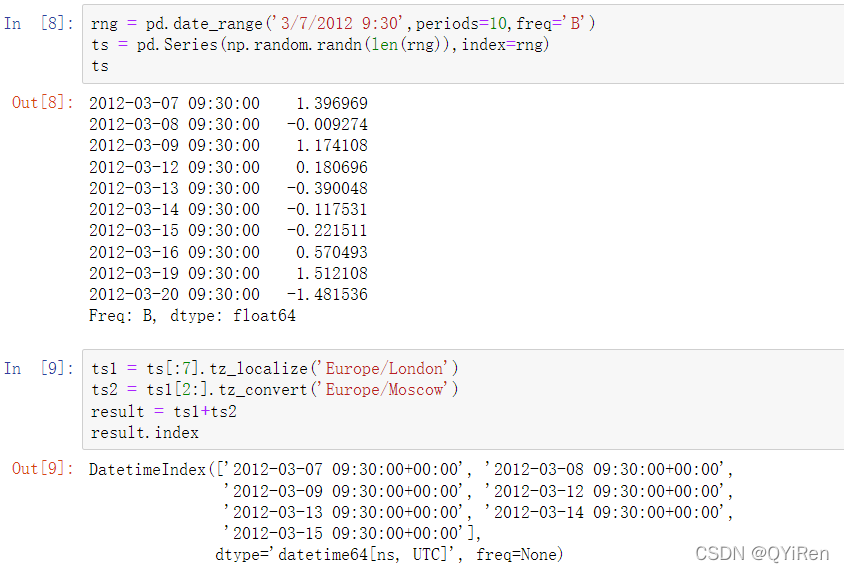
如果两个时区不同的时间序列需要联合,那么结果将是UTC时间的。由于时间戳以UTC格式存储,这是一个简单的操作,不需要转换:
11.5 时间时区和区间计算
时间区间表示的时间范围,比如一些天、一些月、一些季度或者是一些年。
Period类表示的正是这种数据类型,需要一个字符串或数字的频率:
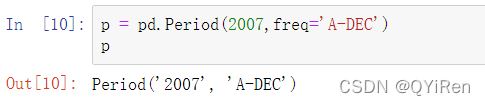
在这个例子中,Period对象表示的是从2007年1月1日到2007年12月31日(包含在内)的时间段。在时间段上增加或减去整数可以方便地根据它们的频率进行移位。
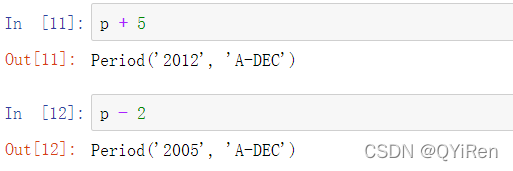
如果两个区间拥有相同的频率,则它们的差是它们之间的单位数:

使用period_range函数可以构造规则区间序列:

PeriodIndex类存储的是区间的序列,可以作为任意pandas数据结构的轴索引:
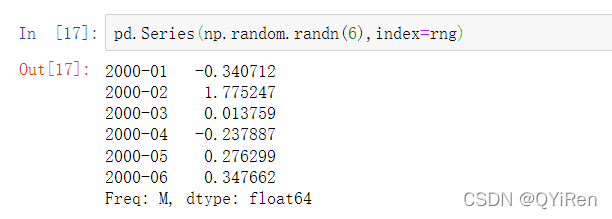
如果你有一个字符串数组,你也可以使用PeriodIndex类:

11.5.1 区间频率转换
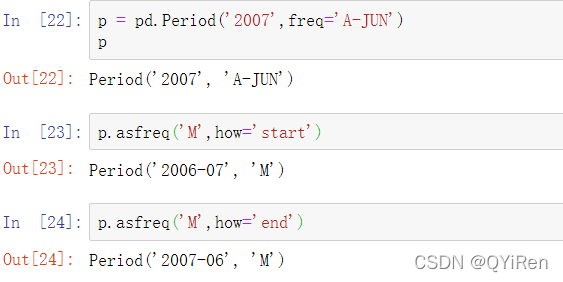
使用asfreq可以将区间和PeriodIndex对象转换为其他的频率。例如,假设我们有一个年度区间,并且想要在一年的开始或结束时将其转换为月度区间。这非常简单:
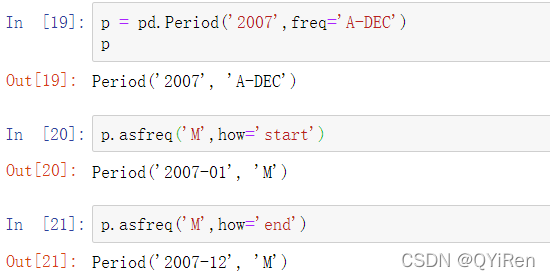
你可以将Period('2007', 'A-DEC')看作一段时间中的一种游标,将时间按月份划分,参见下图。对于除十二月以外的一个月结束的财政年度,相应的每月分期是不同的:
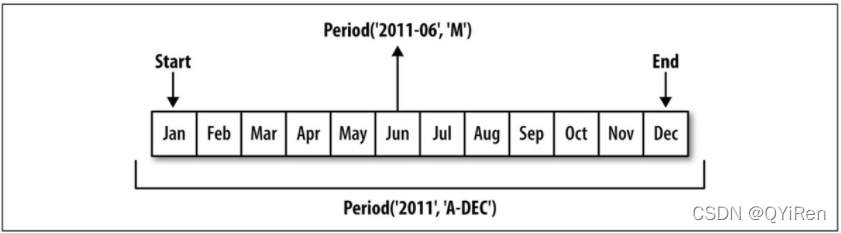
当你从高频率向低频率转换时,pandas根据子区间的"所属"来决定父区间。
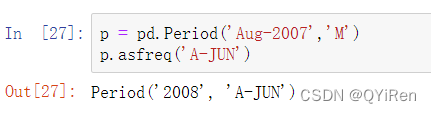
例如,在A-JUN频率中,Aug-2007是2008区间的一部分:
完整的PeriodIndex对象或时间序列可以按照相同的语义进行转换:
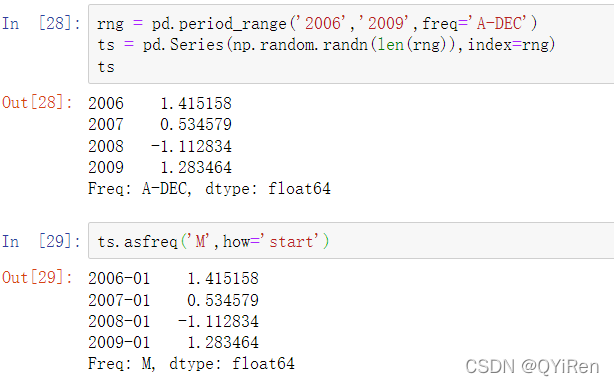
这里,年度区间将被替换为对应于每个年度区间内的第一个月的月度区间。
如果我们想要每年最后一个工作日,我们可以使用’B’频率来表示我们想要的是区间的末端:
11.5.2 季度区间的频率
季度数据是会计、金融和其他领域的标准。
很多季度数据是在财年结尾报告的,通常是一年12个月中的最后一个日历日或工作日。
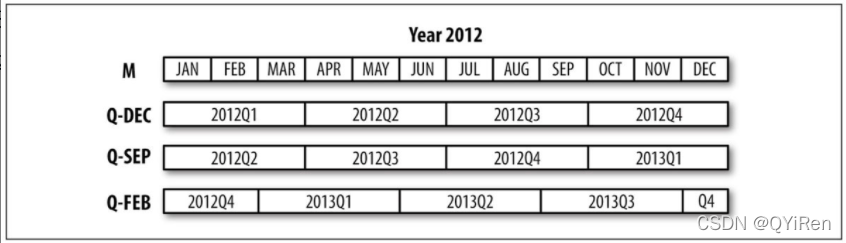
因此,由于是财年结尾,区间2012Q4有着不同的意义。pandas支持所有的可能的12个季度频率从Q-JAN到Q-DEC:
在财年结束于1月的情况下,2012Q4运行时间为11月至1月,你可以通过转换为每日频率进行检查,参考下图:
因此,做简单的区间算术是可行的,例如,要获取在季度倒数第二个工作日下午4点的时间戳,你可以这么做:

你可以使用peroid_range生成季度序列。它的算术也是一样的:
11.5.3 将时间戳转换为区间(以及逆转换)
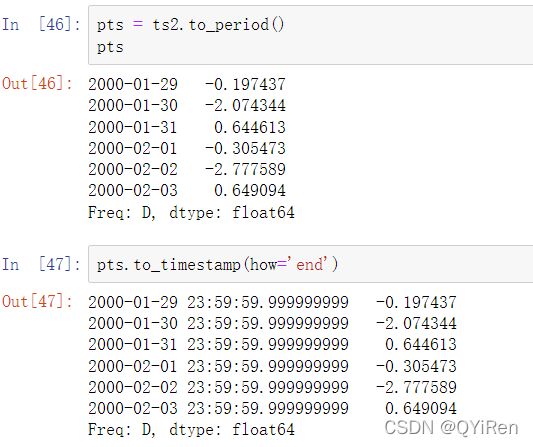
通过时间戳索引的Series和DataFrame可以被to_period方法转换为区间:
由于区间是非重叠时间范围,一个时间戳只能属于给定频率的单个区间。尽管默认情况下根据时间戳推断出新PeriodIndex的频率,但你可以指定任何想要的频率。在结果中包含重复的区间也是没有问题的:
使用to_timestamp可以将区间再转换为时间戳:
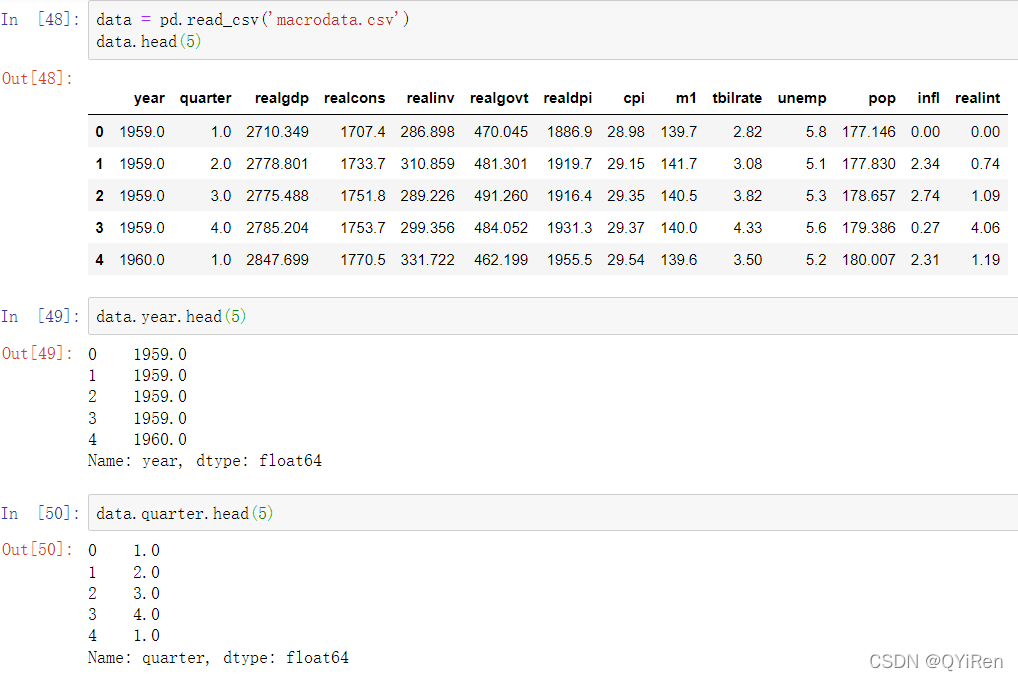
11.5.4 从数组生成PeriodIndex
固定频率数据集有时存储在跨越多列的时间范围信息中。例如,在这个宏观经济数据集中,年份和季度在不同列中:
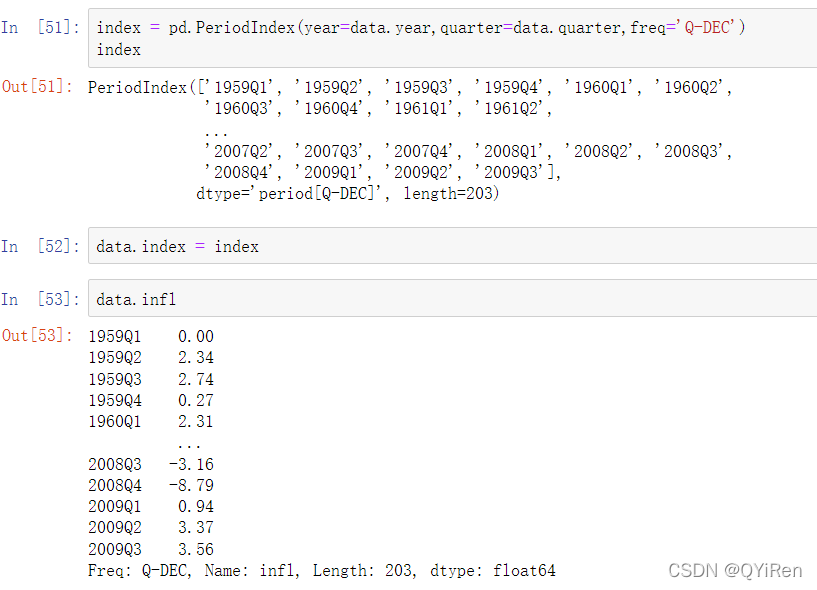
通过将这些数组和频率传递给PeriodIndex,你可以联合这些数组形成DataFrame的索引:
11.6 重新采样与频率转换
重新采样是指将时间序列从一个频率转换为另一个频率的过程。
将更高频率的数据聚合到低频率被称为向下采样,而从低频率转换到高频率称为向上采样。
并不是所有的重新采样都属于上面说的两类;例如,将W-WED(weekly on Wednesday,每周三)转换到W-FRI(每周五)既不是向上采样也不是向下采样。
pandas对象都配有resample方法,该方法是所有频率转换的工具函数。resample拥有类似于groupby的API;你调用resample对数据分组,之后再调用聚合函数:
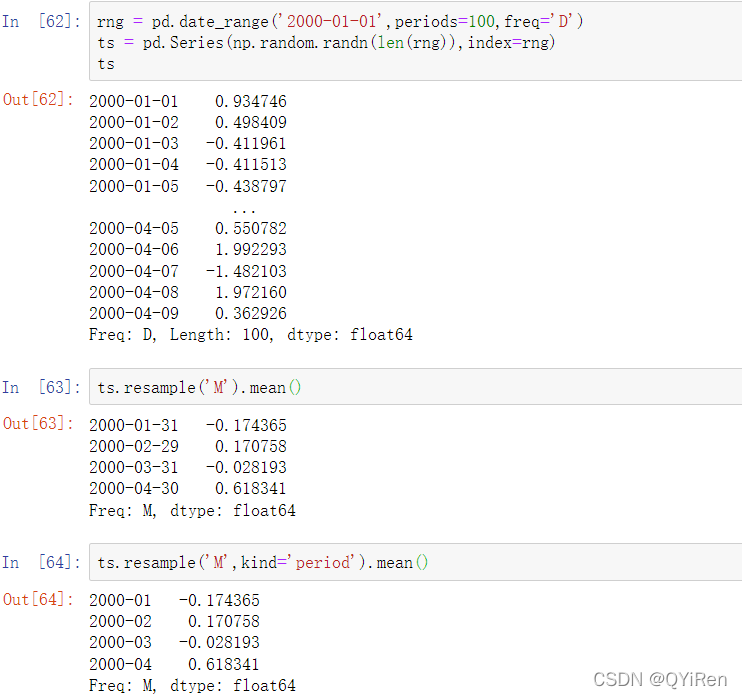
resample方法参数:

11.6.1 向下采样
将数据聚合到一个规则的低频率上是一个常见的时间序列任务。
将数据聚合到一个规则的低频率上是一个常见的时间序列任务。你要聚合的数据不必是固定频率的。期望的频率定义了用于对时间序列切片以聚合的箱体边界。
例如,要将时间转换为每月,'M’或’BM',你需要将数据分成一个月的时间间隔。每个间隔是半闭合的,一个数据点只能属于一个时间间隔,时间间隔的并集必须是整个时间帧。
在使用resample进行向下采样数据时有些事情需要考虑:
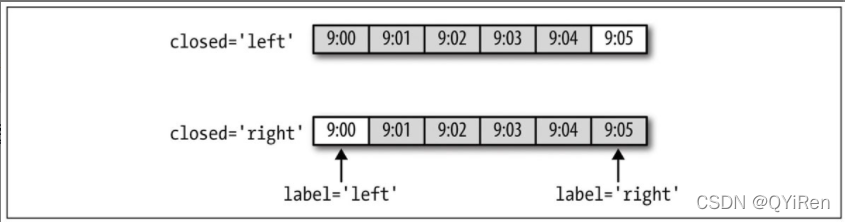
· 每段间隔的哪一边是闭合的
· 如何在间隔的起始或结束位置标记每个已聚合的箱体
示例:
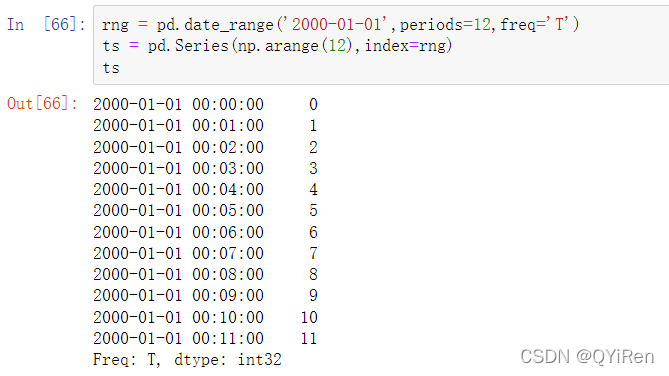
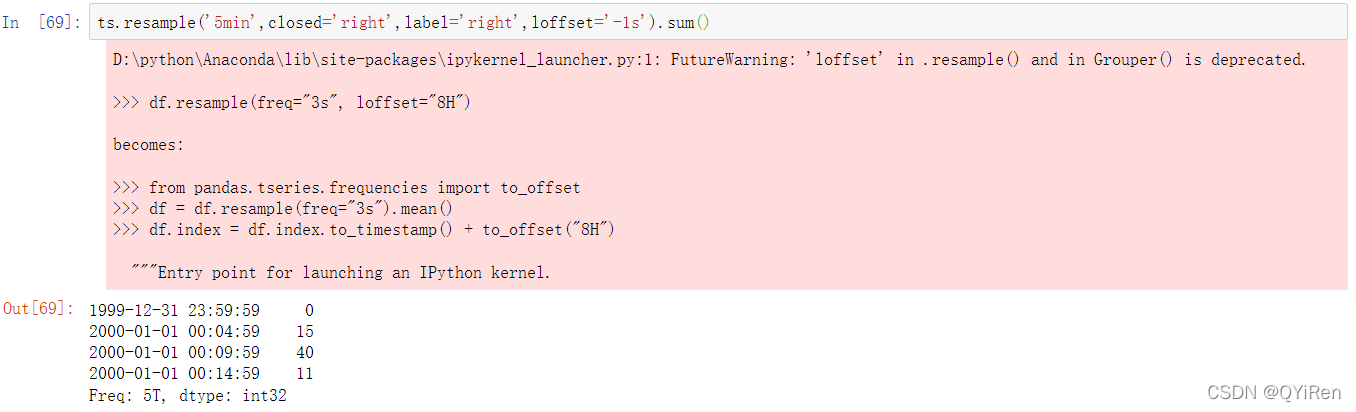
假设你想通过计算每一组的加和将这些数据聚合到五分钟的块或柱内:
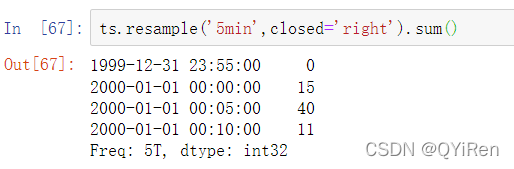
传递的频率按五分钟的增量定义了箱体边界。默认情况下,左箱体边界是包含的,因此00:00的值是包含在00:00到00:05间隔内的。传递closed='right’将间隔的闭合端改为了右边。
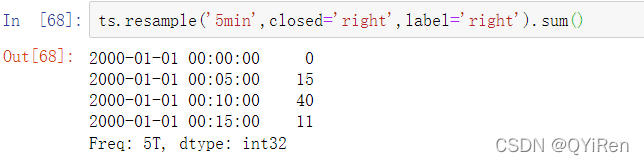
产生的时间序列按照每个箱体左边的时间戳被标记。传递label='right’你可以使用右箱体边界标记时间序列:
下图阐明了分钟频率按五分钟频率进行的重新采样:
可能需要将结果索引移动一定的数量,例如从右边缘减去一秒,以使其更清楚地表明时间戳所指的间隔。要实现这个功能,向loffset传递字符串或日期偏置:
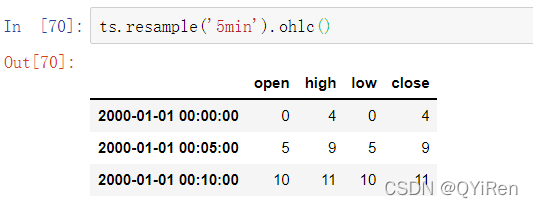
11.6.1.1 开端-峰值-谷值-结束(OHLC)重新采样
在金融中,为每个数据桶计算四个值是一种流行的时间序列聚合方法:第一个值(开端)、最后一个值(结束)、最大值(峰值)和最小值(谷值)。通过使用ohlc聚合函数你将会获得包含四种聚合值列的DataFrame,这些值在数据的单次扫描中被高效计算:
11.6.2 向上采样与插值
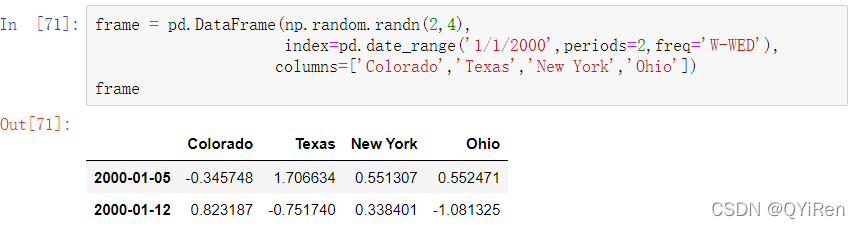
当从低频率转换为高频率时,并不需要任何聚合。让我们考虑带有每周数据的DataFrame:
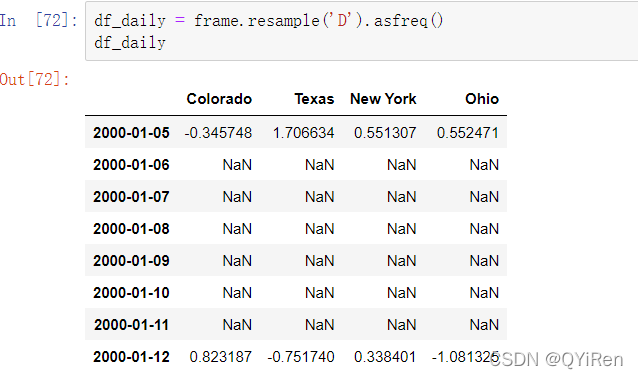
当对这些数据使用聚合函数时,每一组只有一个值,并且会在间隙中产生缺失值。我们使用asfreq方法在不聚合的情况下转换到高频率:
假设你想在非星期三的日期上向前填充每周数值。fillna和reindex方法中可用的填充或插值方法可用于重采样:
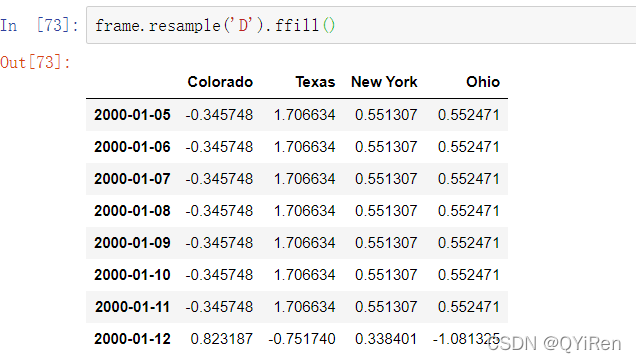
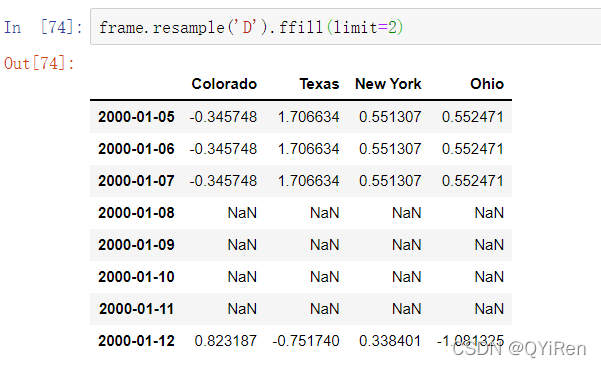
你可以同样选择仅向前填充一定数量的区间,以限制继续使用观测值的时距:
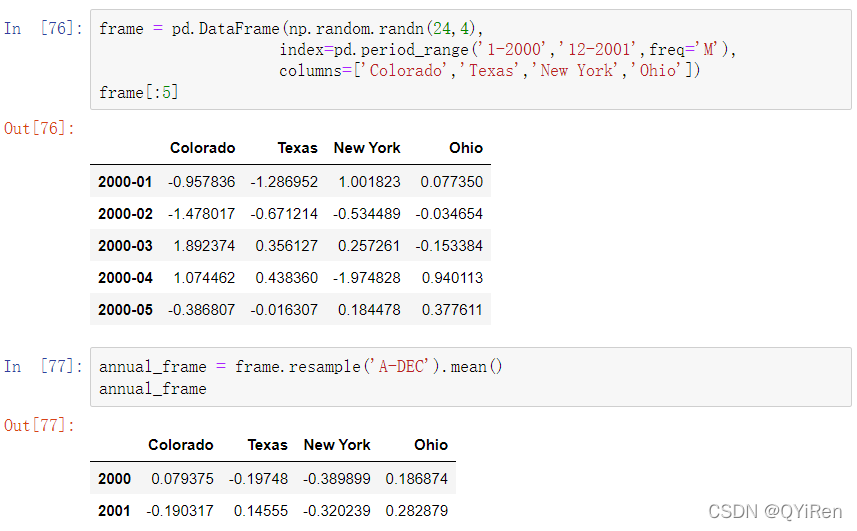
11.6.3 使用区间进行重新采样
对以区间为索引的数据进行采样与时间戳的情况类似:
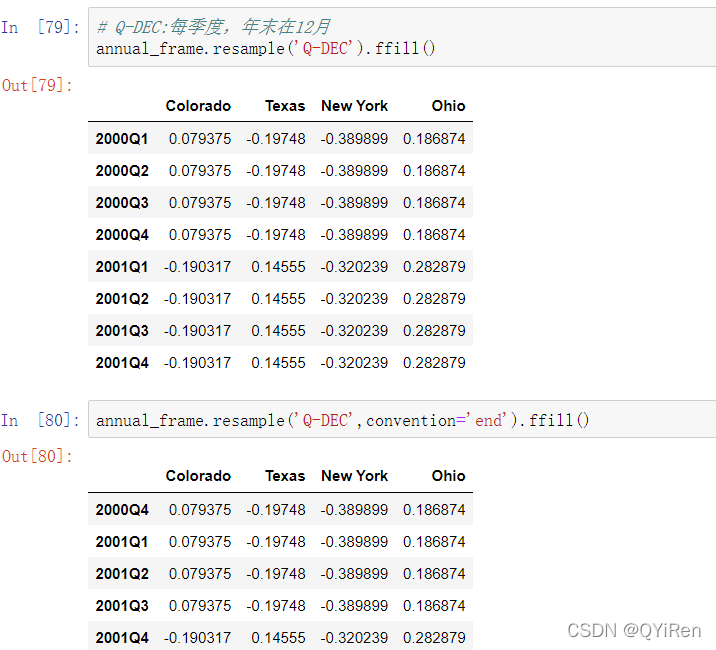
向上采样更为细致,因为你必须在重新采样前决定新频率中在时间段的哪一端放置数值,就像asfreq方法一样。convention参数默认值是’start',但也可以是'end':
由于区间涉及时间范围,向上采样和向下采样就更为严格:
· 在向下采样中,目标频率必须是原频率的子区间。
· 在向上采样中,目标频率必须是原频率的父区间。
如果不满足这些规则,将会引起异常。这主要会影响每季度、每年和每周的频率。
11.7 移动窗口函数
统计和其他通过移动窗口或指数衰减而运行的函数是用于时间序列操作的数组变换的一个重要类别。这对平滑噪声或粗糙的数据非常有用。称这些函数为移动窗口函数,尽管它也包含了一些没有固定长度窗口的函数,比如指数加权移动平均。与其他的统计函数类似,这些函数会自动排除缺失数据。
先载入一些时间序列数据并按照工作日频率进行重新采样:
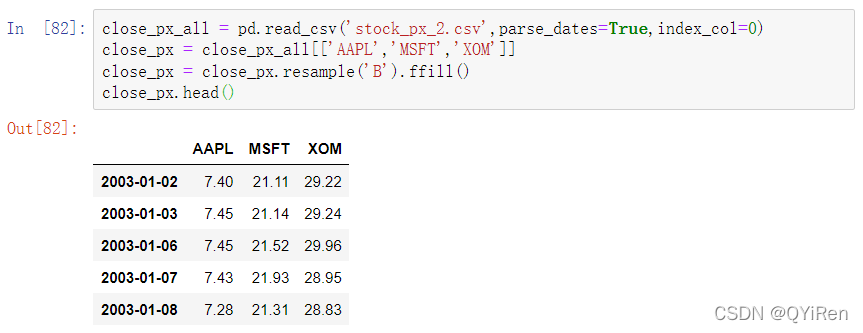
介绍rolling算子,它的行为与resample和groupby类似。
rolling可以在Series或DataFrame上通过一个window(以一个区间的数字来表示,参见下图)进行调用。
表达式rolling(250)与groupby的行为类似,但是它创建的对象是根据250日滑动窗口分组的而不是直接分组。因此这里我们获得了苹果公司股票价格的250日移动窗口平均值。
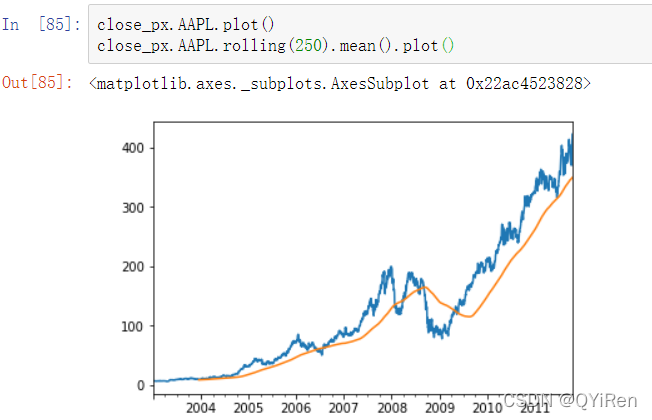
默认情况下,滚动函数需要窗口中所有的值必须是非NA值。由于存在缺失值这种行为会发生改变,尤其是在时间序列的起始位置你拥有的数据是少于窗口区间的(见图苹果公司250日每日返回标准差):
为了计算扩展窗口均值,使用expanding算子,而不是rolling。扩展均值从时间序列的起始位置开始时间窗口,并增加窗口的大小,知道它覆盖整个序列。
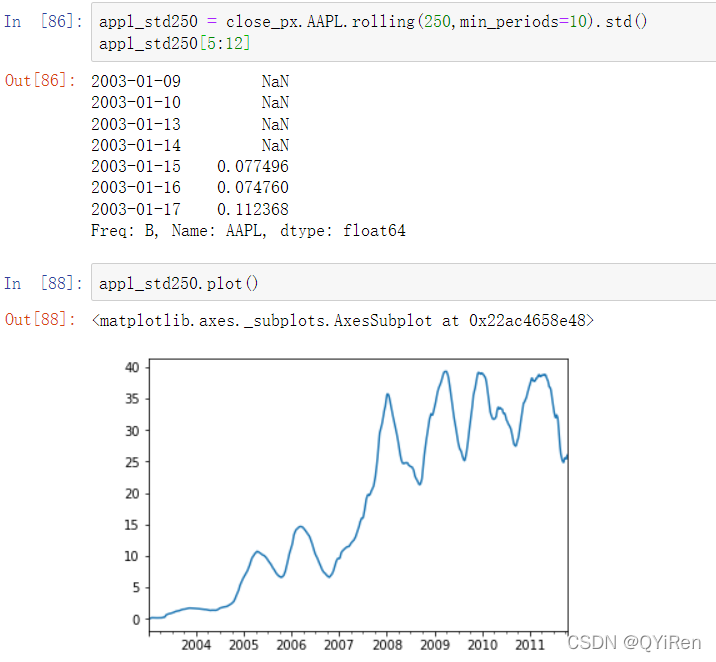
expanding_mean = appl_std250.expanding().mean()在DataFrame上调用一个移动窗口函数会将变换应用到每一列上(见图股票价格60日MA,Y轴取对数):
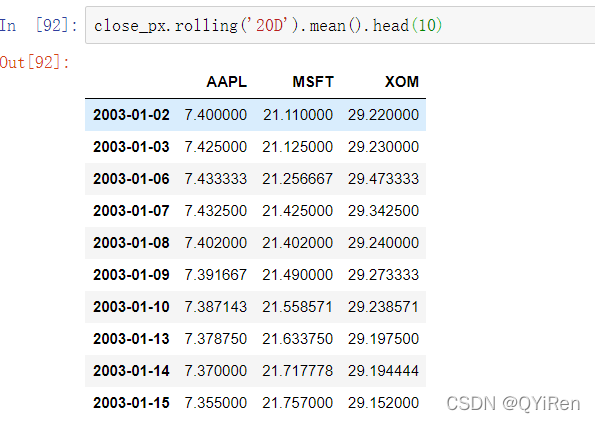
rolling函数也接收表示固定大小的时间偏置字符串,而不只是一个区间的集合数字。对不规则时间序列使用注释非常有用。这些字符串可以传递给resample。例如,我们可以像这样计算20天的滚动平均值:
11.7.1 指数加权函数
指定一个常数衰减因子以向更多近期观测值提供更多权重,可以替代使用具有相等加权观察值的静态窗口尺寸的方法。有多种方式可以指定衰减因子。其中一种流行的方式是使用一个span(跨度),这使得结果与窗口大小等于跨度的简单移动窗口函数。
由于指数加权统计值给更近期的观测值以更多的权重,与等权重的版本相比,它对变化“适应”得更快。
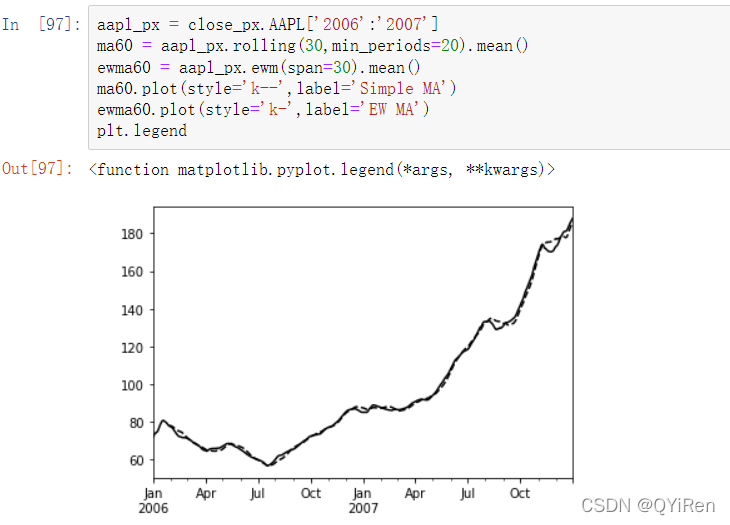
pandas拥有ewm算子,同rolling、expanding算子一起使用。以下是将苹果公司股票价格的60日均线与span=60的EW移动平均线进行比较的例子(见图,简单移动平均与指数加权平均对比):
11.7.2 二元移动窗口函数
一些统计算子,例如相关度和协方差,需要操作两个时间序列。例如,金融分析师经常对股票与基准指数(如标普500)的关联性感兴趣。为了了解这个功能,我们首先计算所有我们感兴趣的时间序列的百分比变化:

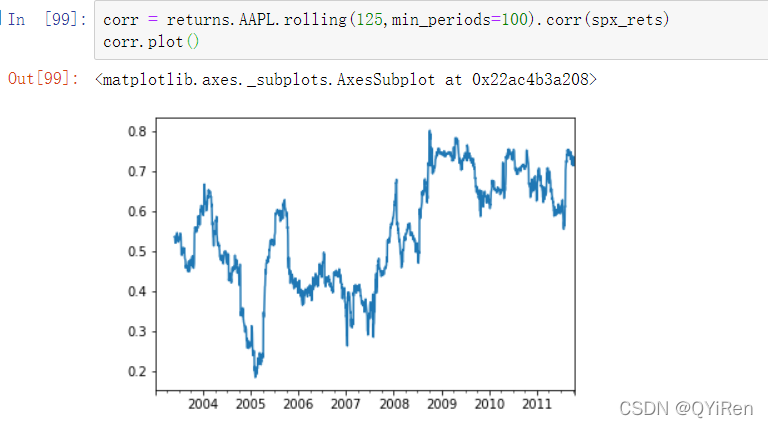
在我们调用rolling后,corr聚合函数可以根据spx_rets计算滚动相关性(见图,苹果公司与标普500的六个月的收益相关性):
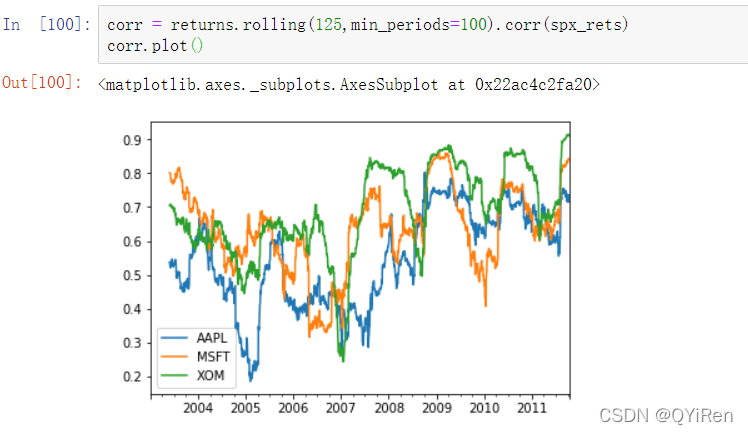
假设你想要一次性计算多只股票与标普500的相关性。编写循环并创建一个新的DataFrame是简单的但可能也是重复性的,所以如果你传递了一个Series或一个DataFrame,像rolling_corr这样的函数将会计算Series(例子中的spx_rets)与DataFrame中每一列的相关性(见图,多只股票与标普500的六个月收益相关性):
11.7.3 用户自定义的移动窗口函数
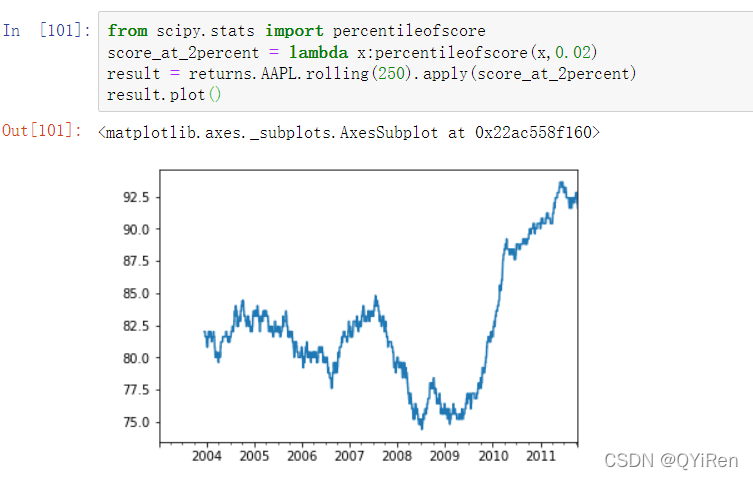
在rolling及其相关方法上使用apply方法提供了一种在移动窗口中应用你自己设计的数组函数的方法。唯一的要求是该函数从每个数组中产生一个单值(缩聚)。例如,尽管我们可以使用rolling(...).quantile(q)计算样本的分位数,但我们可能会对样本中特定值的百分位数感兴趣。scipy.stats.percentileofscore函数就是实现这个功能的(见图):
参考书籍
--《利用Python实现数据分析》

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)